Механизм вывода речи у человека
Как возникает речь?
До сих пор мы пытались дать читателю некоторые основные сведения о том, как наш организм воспринимает и генерирует сигналы для управления речевым выводом, или речью. После того как кора головного мозга приняла сигнал генерации речи, проанализировала его и сформулировала командные коды для речевого тракта, начинается непосредственно процесс генерации слышимой речи. Это, очевидно, самое важное звено в цепи получения речи. Правда, возможна "речь" и без участия этого звена, т. е. без произнесения слов. Например, мы можем прочесть слово hello про себя, "сказать" и "услышать" его мысленно, не приводя в действие органы речи. При этом фактически мы приводим механизм речи в готовность, но не подаем выходных команд на многочисленные органы голосового тракта человека.
Решив же произнести слово вслух, мы отдаем большому числу наших органов команду выполнять одновременно разные действия при минимальном сознательном участии с нашей стороны. Сложность этой почти подсознательно выполняемой задачи необходимо понять, чтобы представить себе всю трудность генерации синтезируемой компьютером речи. Проследив за работой голосового тракта - он начинается в легких и заканчивается ртом,- легче будет понять, почему были выбраны те или иные методы синтеза речи. Возможно, вы сами сможете предложить какие-либо новые методы синтеза речи.
От легких до губ
Участвующие в генерации речи органы человека образуют канал сложной формы, идущий от легких к кончикам губ. Этот канал длиной около 30 см вместе с остальными органами речи изображен схематически на рис. 2.3. Чтобы разобраться в процессе образования речи от начала до конца, надо проследовать по этой схеме от легких по трахее до гортани, пройти глотку и наконец добраться до выхода через нос или рот. Хотя вся полость имеет длину около 30 см, голос действительно начинает обретать свою форму лишь на последних примерно 15 см. В конце концов после модификации и артикулирования в носовой полости, глотке и во рту звуки обретают форму определенного осмысленного слова. Но если вы не проучились два первых курса в медицинском институте, вам все же нелегко будет понять из приведенной схемы, как в голосовом тракте создается речь. Однако, сопоставив эту схему с моделью речевого механизма, показанной на рис. 2.4, можно связать различные функции голосового тракта с соответствующими речевыми эффектами. На участке ниже рта между обеими схемами существует однозначное соответствие, так как звук здесь очень мало модифицируется. Когда же звук или воздух под воздействием легких и голосовых связок проходит через глотку в рот, аналогия становится достаточно сложной. В этом легко убедиться, если попытаться сказать ah, сохраняя неизменными открытое положение рта, челюсти, языка, губ и зубов. Попробуйте теперь заметно изменить характеристики вашего голоса, не приводя в движение упомянутые голосовые "фильтры" рта. Если вы поступили честно и оставили все без движения, то единственно, что вы сможете изменить, это высоту основного тона произносимого вами звука или его громкость (амплитуду). Внимательно выполняя этот эксперимент, заметим, что можно произвести еще одно изменение в голосовом тракте, не нарушая условий опыта. Оно достигается полным расслаблением мышц голосовых связок, расположенных ниже глотки, и выражается в прекращении колебаний связок и превращении речи с голосом в простое прохождение воздуха, не сопровождающееся голосом. Такой вид речи, как и речь с голосом, так же важен для нормального разговора, как и звук, создаваемый колебаниями голосовых связок. Далее в этой главе мы познакомимся с белым шумом, возникающим при простом прохождении воздуха из легких через голосовой тракт. Но прежде попытаемся разобраться в работе голосового тракта и найти электронные аналогии каждому виду взаимодействий, ибо наша цель - понять, как можно с помощью электронных схем синтезировать речь.
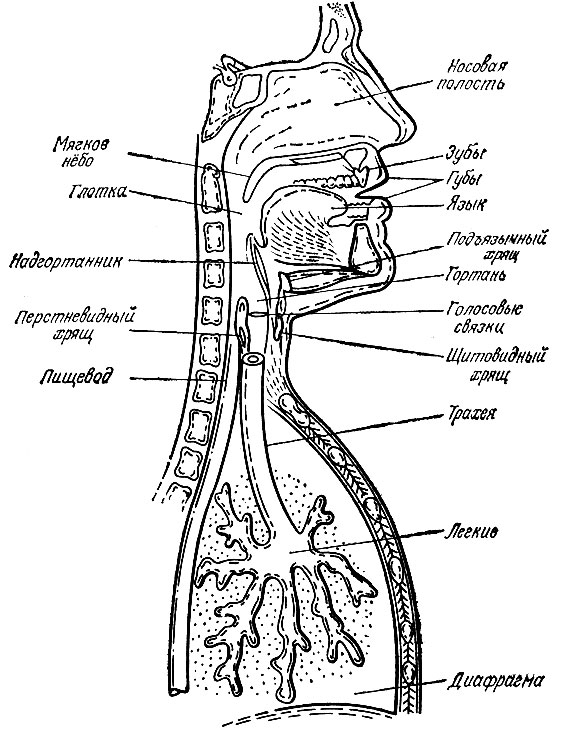
Рис. 2.3. Органы, участвующие в процессе генерации речи
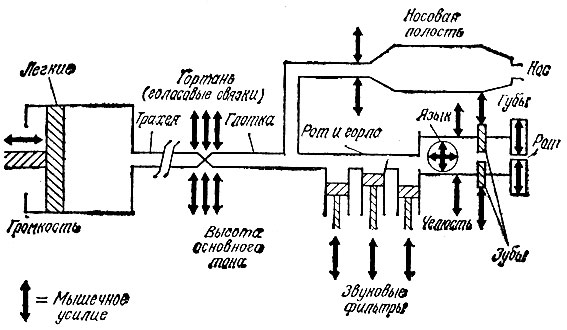
Рис. 2.4. Механическая модель голосового тракта
Первое, что следует сделать для генерации речи,- это выдохнуть воздух из легких, в результате чего создается воздушный поток через голосовой тракт. Такой процесс происходит всегда, когда мы дышим через рот, но никакого звука при этом не слышно, пока в работу не включаются голосовые органы. Как только мы решили, что выдох должен стать речью, мы начинаем формировать звук. Это можно сделать, либо заставив колебаться голосовые связки (гортань), либо ограничивая прохождение воздуха языком, зубами и губами. В результате получаются звонкие, например гласные, звуки или соответственно фрикативные типа S или F.
Допустим теперь, что мы хотим произнести слово из гласных звуков. Подходящее слово, не требующее ни фрикативных, ни согласных звуков,- это восклицание ow. Рассмотрим последовательно, что происходит, когда мы произносим это слово.
Легкие начинают выпускать воздух в объеме достаточном, чтобы возникли произвольные колебания голосовых связок. Если поток воздуха из легких недостаточен для возбуждения колебаний голосовых связок, то слово произносится шепотом. Иначе говоря, голосовые связки начинают колебаться при некотором пороговом значении воздушного потока из легких. Мы подсознательно "задаем" нужное количество выдыхаемого воздуха, прежде чем начать говорить, и тем самым определяем громкость (амплитуду) речи. Если же попытаться сказать слово очень тихо, то нетрудно заметить, что это можно сделать, повысив высоту основного тона голоса. Но если пытаться говорить с прежней громкостью, существенно понизив тональность, то придется значительно увеличить количество воздуха, пропускаемого через голосовые связки.
Форма волны звуковых колебаний, создаваемых голосовыми связками, подобна той, что показана на рис. 2.5. Именно такую форму волны мы увидели бы на экране осциллографа с достаточным усилением, если бы нам удалось поставить микрофон в горле непосредственно на выходе из гортани. Спектральная характеристика того же сигнала, поданного на анализатор спектра или систему частотного анализа, показана на рис. 2.6. Для тех, кто незнаком с анализаторами спектра, поясним, что эта кривая характеризует распределение частотных составляющих импульса на выходе голосовой щели (см. рис. 2.5) в полосе звуковых частот. Как можно видеть, максимум этого распределения смещен в область нижних частот: 200-300 Гц.
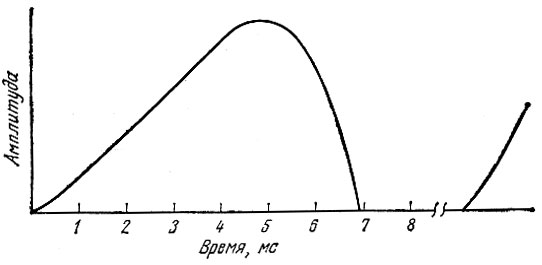
Рис. 2.5. Форма импульса на выходе голосовой щели
Когда в процессе речи голосовые связки натягиваются, частота основной составляющей (или составляющих) спектра повышается, что выражается в повышении высоты основной тональности голоса. Частота основного тона мужского голоса лежит в пределах 130-146 Гц и имеет среднее значение около 141 Гц. Частота основного тона женского голоса находится в области 188-295 Гц; ее среднее значение близко к 233 Гц. В особых случаях, когда речь содержит сильные ударения, частота основного тона на выходе голосовой щели может достигать 480 Гц.
Не следует забывать, что рассматриваемые нами частоты - это генерируемые вследствие колебаний голосовых связок основные гармоники, а не обертоны, возникающие при резонансах в горле, носовой и ротовой полостях. Другими словами, форма волны, или импульс, показанный на рис. 2.6, повторяется с интервалом, соответствующим основным гармоникам.
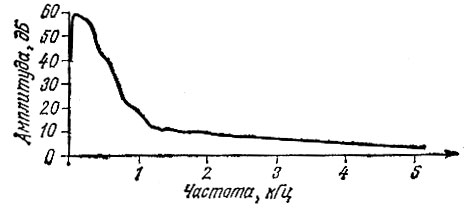
Рис. 2.6. Частотный спектр импульса на выходе голосовой щели
Голосовые фильтры
Мы рассмотрели функции голосовой системы человека, которая создает основной звуковой тон речи посредством колебаний голосовых связок. До этого момента электронный синтез голоса сравнительно прост, так как упрощенную кривую колебаний голосовых связок можно записать в электронной памяти, а затем воспроизводить для получения основного звукового тона речи.
Наиболее сложные речевые структуры формируются в голосовом тракте выше голосовых связок. Рот, нос и губы производят фильтрацию гармоник, или обертонов, создавая частотные спектры, соответствующие известным нам звукам, которые мы называем нормальными речевыми сигналами. Электронным приборам непросто справиться с такой задачей. В самом деле, вернувшись к рис. 2.4, можно увидеть, что во рту и горле есть много подвижных, регулируемых, элементов. К тому же на этой упрощенной схеме представлены далеко не все звуковые фильтры, имеющиеся в ротовой полости.
В предыдущих параграфах этой главы мы познакомились с процессом формирования естественной речи и узнали, как головной мозг генерирует сигналы, управляющие речью. В конечном счете эти сигналы приводят в движение мышцы лица, от которых зависит звуковая фильтрация. Таким образом, для создания электрической модели голосового тракта, позволяющего получать искусственную речь, близкую к естественной, компьютер должен управлять таким же числом фильтров. Если учесть, что на лице, во рту и горле существует около 50 мышц, движением которых можно изменять импульс на выходе гортани, то трудно даже представить, насколько сложна задача моделирования 50 фильтров с помощью компьютера. Мало кого привлекла бы попытка создать систему из 50 фильтров; еще меньше, видимо, найдется энтузиастов заняться программированием управляемого изменения таких фильтров в процессе разговора. В этом основная трудность синтеза речи. Как же довести такой сложный механизм до достаточно простой формы, с которой можно работать?
Прежде всего посмотрим, что происходит, когда в звуковой фильтр (электронный или акустический), называемый также резонатором, вводится колебание, по форме соответствующее импульсу на выходе голосовой щели. Реакция резонатора на этот импульс возбуждения может быть такой, как показано на рис. 2.7. Хотя импульсы возбуждения следуют с небольшой частотой повторения, порядка 100-300 Гц (верхний график), выходной сигнал резонирующего звукового фильтра получается подобным "звону" колокола после удара по нему, причем частота "звона" в четыре-пять раз превышает частоту исходного возбуждающего сигнала. "Звон" звукового фильтра (или резонатора) служит характеристикой резонирующего устройства. Вспомним, например, как дети часто дуют поперек горлышка открытой бутылки с лимонадом, создавая при этом звук определенного тона. Если из бутылки отпить немного лимонада, то частота звука становится ниже. В этом случае изменяется длина резонансной полости в бутылке, которая и определяет резонансную частоту звукового фильтра. Примерно то же самое происходит в полости рта, когда там возбуждаются обертоны импульса, образовавшегося на выходе голосовой щели. Хотя мы ограничиваем наше рассмотрение одним частотным резонатором, в голосовом тракте действует множество резонаторов-фильтров, и каждый из них характеризуется своей резонансной частотой (зависящей от формы резонатора), которая быстро меняется в процессе речи.
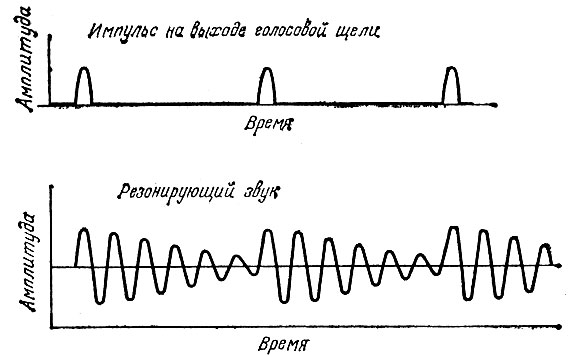
Рис. 2.7. Процесс возбуждения звукового резонатора
Различные резонансные частоты полостей голосового тракта называют формальными частотами. Для удовлетворительного синтеза речи обычно нужны три-четыре формантные частоты. Они лежат в диапазоне от 200 (первая форманта мужского голоса) до 2000 Гц (третья форманта женского голоса). Точным расположением формантных частот в звуковом спектре и определяется звук, который мы интерпретируем как речь. Процесс речи заметно усложняется вследствие того, что все форматные частоты присутствуют в речи одновременно и непрерывно перемещаются вверх-вниз по частотному спектру в соответствии с особенностями произносимого слова. Поэтому, слушая говорящего человека, вы слышите звук не какой-либо одной частоты, а множество обертонов, которые образуются при фильтрации импульсов, формируемых на выходе голосовой щели.
На рис. 2.8 приведены примеры частотных спектров речи. В каждом из спектров содержание формантных частот различно, так как произносятся разные гласные звуки. Максимумы спектров на частотах f1, f2, и f3 соответствуют резонансам голосового тракта, или формантам, образующимся в процессе нормальной речи.
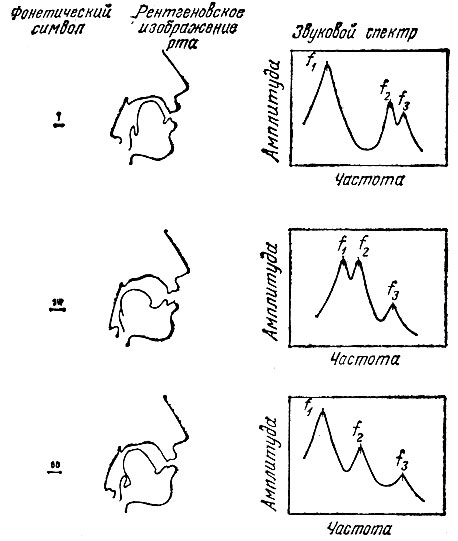
Рис. 2.8. Форманты в спектре речи
Теперь, исходя из спектров, показанных на рис. 2.8, посмотрим, как будет меняться со временем спектр некоего набора звуков, вроде i-aw-oo. Результирующий спектр будет чем-то похож на ряд кинокадров, идущих на рисунке в последовательности сверху вниз. При переходе от звука i к звуку aw форманты смещаются по частоте так, как показано на втором "кадре". А при произнесении звука оо форманты становятся такими, как на третьем "кадре". Для визуального представления непрерывных спектров звуков речи разработаны специальный метод и устройство. На выходе такого устройства фактически получается видимая речь, которую часто называют "отпечатком голоса" или спектрограммой. Рассмотрим, что представляет собой спектрограмма, поскольку нам придется встречаться с таким представлением речи в дальнейшем.
Начнем с рис. 2.9, где приведено несколько моментальных снимков частотных спектров (они соединены между собой вертикальными линиями), расположенных последовательно вдоль оси времени. С увеличением амплитуды колебания данной конкретной частоты горизонтальная линия, соответствующая этой частоте, становится более черной. Другими словами, чем больше амплитуда колебания (громкость звука) какой-либо частоты, тем темнее соответствующая ей линия в каждый момент времени. Так, в момент времени 0,1 с на анализатор спектра подается тональный сигнал частотой 1000 Гц. Затем частота сигнала скачком возрастает до 2000 Гц, сохраняя ту же самую амплитуду в продолжение еще 0,2 с, после чего (в момент времени 0,4 с) снова увеличивается до 4000 Гц и начинает уменьшаться по амплитуде на протяжении оставшегося (до окончания секунды) интервала. С помощью этой довольно упрощенной спектрограммы можно следить за изменением амплитуды и частоты входного сигнала, получая двумерное представление входного сигнала в зависимости от времени. Разумеется, если мы подадим на вход анализирующей системы две (или больше) частоты, то в процессе записи получится две или больше черных линий, соответствующих частотам и амплитудам звуковых сигналов. Таков механизм получения записей видимой речи, или спектрограмм, с которыми мы еще неоднократно встретимся.
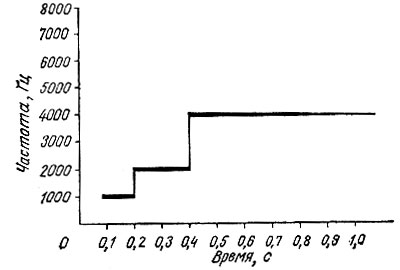
Рис. 2.9. Спектрограмма тональных частот
Чтобы лучше представить, как выглядит типичная спектрограмма, на рис. 2.10 показана видеограмма звука ah в слове father. Заметим, что каждая из темных полос - это формантная частота, присутствующая на протяжении всего времени произнесения данного звука. Предположим далее, что мы намерены сконструировать три полосовых фильтра, управляемых напряжением, и допустим, что их характеристики должны изменяться со временем так, чтобы они соответствовали ходу темных полос на спектрограмме. Если на входы фильтров подавать низкочастотные импульсы, подобные тем, что формируются на выходе голосовой щели, то выходной сигнал такой системы фильтров будет весьма похож на речь, записанную на спектрограмме.
Эта система фильтров в принципе представляет собой простой синтезатор речи, основанный на формантном синтезе, который используется во многих системах фонетического синтеза. Более подробно мы рассмотрим этот метод в главе, посвященной методам синтеза речи.
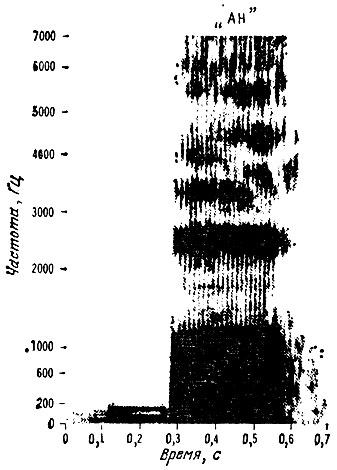
Рис. 2.10. Видеограмма звука ah (как в слове father)
Резонансы со свистом и шипением
Последняя группа звуков, которой мы коснемся в данной главе,- это глухие звуки типа s, t, f, р, sh, ch и к, образующиеся при участии зубов, губ и языка. Эти звуки (о них мы будем говорить также в следующей главе), необходимые для понимания речи человека, возникают исключительно в результате резонансов при ограничении потока воздуха из легких. Если, например, мы ограничим выход воздуха из полости рта губами и зубами, то получим звук f. Если ограничить выход воздуха языком и зубами, то образуется звук th. Главное различие между этими двумя звуками - в силе резонанса, который возбуждается белым шумом, генерируемым ограниченным воздушным потоком. (Белый шум в данном случае определяется как звук с равномерным распределением спектра частот по звуковому диапазону.)
Поскольку источник шума при произнесении этих звуков находится у самого выхода ротовой полости, различные резонансные полости в горле и задней части рта не оказывают существенного влияния на звук, создаваемый губами или зубами. Следовательно, идея формантных частот для этих звуков (называемых фрикативными или взрывными) фактически не применима, так как большинство резонаторов в процессе формирования звуков не участвует. Более простой путь к пониманию сути дела - рассмотреть спектрограмму фрикативного звука s в слове seal (рис. 2.11). Этот звук, создаваемый губами и зубами, очень слабо фильтруется в ротовой полости и в горле; поэтому обнаружить резонансы на его спектрограмме очень трудно. Но имеющиеся резонансы характеризуют информационное содержание этого звука и позволяют распознавать его в речи.
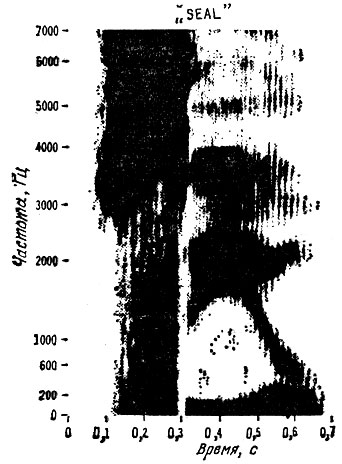
Рис. 2.11. Видеограмма, показывающая спектр звука s (как в слове seal)
В данной главе мы познакомились, хотя и весьма кратко, с механизмом генерации речи у человека. Начав с описания голосового тракта человека, мы закончили наш рассказ упоминанием о синтезе речи с использованием формантных частот. Мы попытались пояснить, как головной мозг управляет процессом речи - от момента возникновения возбуждающего сигнала в мозге до формирования звуковой речи. Внимательно прочитав эту главу, вы получите общее представление о механизме генерации речи человека. А это создает основу для понимания проблем компьютерного синтеза речи. До сих пор нам было не важно, какой язык формируется из звуков, генерируемых голосовым трактом. Переходя к следующей главе, мы должны оговориться, что при знакомстве с другим важным разделом науки о речи - лингвистикой мы будем пользоваться английским языком.
|
ПОИСК:
|
При использовании материалов сайта активная ссылка обязательна:
http://informaticslib.ru/ 'Библиотека по информатике'