Метод непосредственного кодирования-восстановления
Метод непосредственного кодирования-восстановления
Этот простейший метод генерации речи более других похож на цифровую запись. Выше мы ввели понятие выборки аналоговых сигналов с целью последующего восстановления речи. Правильное представление о механизме выборки очень важно для понимания методов кодирования-восстановления речи. Чтобы пояснить, как происходит выборка аналоговых сигналов, приведем такой пример. Рассмотрим выборку визуального (зрительного) сигнала. Здесь все происходит так же, как и в случае звукового аналогового сигнала, с той лишь разницей, что теперь мы имеем дело с визуальным сигналом.
Прежде всего выберем "сцену", на которой развертываются действия,- скажем, экран телевизора или проходящую поблизости скоростную магистраль с мчащимися по ней автомобилями. Теперь посмотрите на эту сцену и закройте глаза. Если далее вы будете быстро (с частотой примерно раз в секунду, т. е. 1 Гц) открывать и закрывать глаза, подобно тому как это делает обтюратор кинокамеры, то без труда сможете наблюдать за происходящим на сцене. Продолжайте мигать, открывая глаза на несколько секунд, и вы убедитесь, что вам действительно удается следить за событиями, протекающими перед вашим взором. То, что вы делали, соответствует визуальной выборке движения (аналогового сигнала). Если же какое-то действие произойдет "мгновенно" - пока глаза были закрыты, хотя мигание происходит с частотой 1 Гц,- то вы этого просто не заметите. Уменьшим теперь частоту мигания примерно до одного раза в десять секунд, т. е., закрыв глаза, вы считаете до 10, затем на мгновение открываете их и снова закрываете на 10 с и т. д. Повторив этот опыт в течение одной-двух минут, вы поймете, что теперь вам не удается пронаблюдать всю последовательность событий, происходящих на "сцене". По существу, вы уменьшили частоту выборки ниже предельной величины, определяемой критерием Найквиста, соблюдение которого необходимо для адекватного наблюдения и описания аналогового сигнала. При мигании с более высокой частотой у вас не должно возникать никаких трудностей при наблюдении за сценой и описании происходящих на ней действий. Рассмотренный пример полностью аналогичен процессу выборки слышимой речи, с тем лишь исключением, что в нашем примере выборка производится визуальным путем, а в случае речи - электронным. Различие между этими двумя случаями очень мало. В процессе преобразования звуков речи микрофоном генерируется электрический сигнал, который содержит как медленно, так и весьма быстро меняющиеся компоненты. Если бы мы стали делать выборки из этого сигнала с относительно низкой частотой, то самое большое, что нам удалось бы установить,- это то, что в сигнале действительно существуют медленно меняющиеся компоненты. Быстро меняющиеся компоненты сигнала ускользнули бы от нас при таком методе исследования. Если же мы начнем осуществлять выборку электрических сигналов микрофона со все возрастающей частотой, то будем обнаруживать все более высокочастотные компоненты сигнала. В целях иллюстрации на рис. 6.2 сравниваются выборки, осуществляемые с разными частотами.
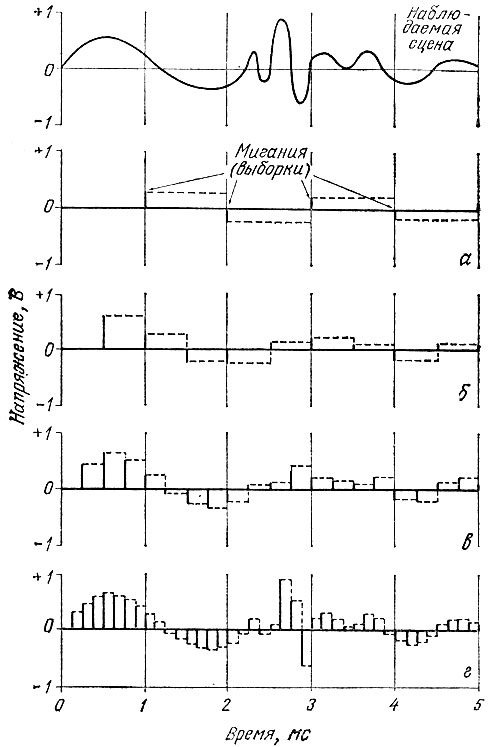
Рис. 6.2. Увеличение частоты выборки сигнала
На самом верхнем графике рисунка показан аналоговый сигнал, из которого должны быть получены выборки. По своему виду он весьма похож на сложные колебания, с которыми приходится иметь дело при обработке речи. Нетрудно заметить, что в составе этого сигнала имеются как медленно, так и быстро меняющиеся составляющие. Пользуясь терминами спектрального анализа, можно сказать, что медленно меняющиеся составляющие представляют собой низкочастотные компоненты, а быстро меняющиеся (центральная часть графика) - более высокочастотные компоненты. Если из этого сигнала, общая длительность которого равна 5 мс, производить выборку с частотой одна выборка в миллисекунду, то мы получим амплитудно-модулированный импульсный сигнал (рис. 6.2, а), который дает сравнительно мало информации об исходном колебании. Если попытаться восстановить форму первоначального сигнала по этим пяти импульсам, то это позволит нам судить лишь о самых низкочастотных компонентах. Удвоив частоту выборок, мы получим сигнал (рис. 6.2, б), который дает несколько больше информации об исходном сигнале. Еще и еще удваивая частоту выборок (рис. 6.2, в, г), мы получим амплитудно-модулированные импульсные сигналы, более точно воспроизводящие исходный сигнал. Процесс с удвоением частоты выборки можно проводить многократно - до тех пор, пока полученная форма сигнала не станет настолько точно соответствовать исходному колебанию, что дальнейшее повышение частоты выборки ничего более не добавит к ней. Поскольку наивысшая частотная составляющая в исходном (входном аналоговом) сигнале умещается во временном интервале несколько менее 0,5 мс, для адекватной характеристики сигнала мы должны, согласно теореме Найквиста, производить выборки с частотой четыре раза в миллисекунду. Этот случай представлен на рис. 6.2, в. В самом деле, показанный здесь сигнал содержит в себе большую часть высокочастотных выбросов исходного сигнала. Для большей точности воспроизведения сигнала частоту выборок можно еще удвоить, доведя до восьми раз в миллисекунду (рис. 6.2, г). В этом случае первоначальный сигнал отображается амплитудно-модулированным импульсным сигналом почти без искажения
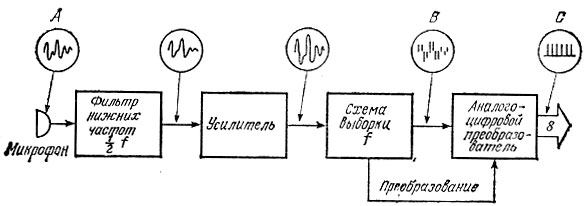
Рис. 6.3. Система выборки речевого сигнала
Процесс выборки аналогового сигнала, как было показано, дает нам последовательность импульсов, высота которых соответствует амплитуде сигнала в момент выборки, а длительность - ширине импульсов выборки. Информацию такого вида весьма трудно вводить в память компьютера. Для этого нужно сначала преобразовать изменения амплитуды импульсов к цифровому виду. Блок-схема, показанная на рис. 6.3, иллюстрирует, как это можно сделать.
В системе выборки (дискретизации) речи, представленной на рис. 6.3, сигналы речи, поступающие с микрофона, прежде всего пропускаются через фильтр нижних частот, что позволяет удалить из них составляющие с частотой, превышающей половину частоты выборки. Это нужно, чтобы не допустить проникновения посторонних сигналов, возникающих, когда выборка производится на частоте, менее чем в два раза превышающей частоты сигнала (вспомните теорему Найквиста). Затем сигнал подается на усилитель, где его уровень повышается настолько, чтобы стало возможным подать его на вход собственно схемы выборки. Здесь-то и выполняется процесс выборки, проанализированный на рис. 6.2. На выходе схемы выборки получается последовательность импульсов, промодулированных по амплитуде в соответствии с величиной аналогового сигнала в каждый из моментов выборки. Наконец, последний блок системы представляет собой аналого-цифровой преобразователь (АЦП). Заметим, что этот блок имеет одну входную линию, на которую поступают выборки аналогового сигнала, и восемь выходных линий. Существуют и более сложные АЦП с 16 или 18 битами (разрядами) на выходе; однако мы ограничимся величиной выходного сигнала 8 бит. Этот 8-битовый выходной сигнал АЦП используется для ввода данных в компьютер. В АЦП аналоговый входной сигнал преобразуется в Цифровую форму и в виде сигнала импульсно-кодовой модуляции (ИКМ) поступает с выхода АЦП в память компьютера.
Чтобы проиллюстрировать процесс импульсно-кодовой модуляции, на рис. 6.4 показаны более детально формы сигналов, обозначенных на рис. 6.3 буквами А, В и С. Мы рассмотрели, как осуществляется преобразование аналогового речевого сигнала в форму, пригодную для ввода в память компьютера. При этом сначала производится выборка, а лишь затем преобразование аналогового сигнала в ИКМ-сигнал. Важная особенность сигнала С, представленного на рис. 6.4, состоит в том, что импульсы этой последовательности постоянны по амплитуде и, следовательно, пригодны для ввода в память компьютера. Каждый из 8 бит ИКМ-сигнала речи может подаваться на последовательный вход компьютера для записи в его память. Вместе с тем эти 8 параллельных бит могут передаваться через параллельный вход компьютера и записываться непосредственно байт за байтом. Данные, поступившие на вход компьютера, вводятся в его память в виде цифровой записи амплитуд исходного речевого сигнала. Речевой информацией, хранящейся в памяти, можно манипулировать, используя для более плотного размещения информации программные средства. Подобные манипуляции, которые будут рассмотрены ниже, позволяют снизить требования, предъявляемые к памяти.
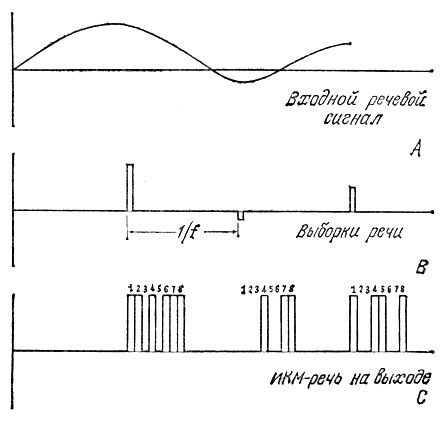
Рис. 6.4. Преобразование амплитудно-модулированного сигнала в импульсно-кодовый
Итак, мы знаем, как осуществляются выборка и запись аналоговой речи в память нашего компьютера. Теперь можно попытаться создать очень простой синтезатор речи с непосредственным кодированием. Примерная схема такого синтезатора приведена на рис. 6.5. В верхней части рисунка мы видим уже знакомую нам цепочку блоков, осуществляющих выборку речевого сигнала после микрофона (см. рис. 6.4). При частоте выборки 6 кГц эта схема дает на выходе 6000 8-битовых байтов в секунду. Ранее мы отметили, что для произнесения слова hello требуется примерно 0,3 с. При частоте выборки 6000 Гц число выборок для этого слова составит около 2000 байт. Сюда следует также включить короткие паузы в начале и в конце слова. Прямоугольник (обведен штриховой линией) в центре рис. 6.5 - это компьютер с 8-битовым параллельным портом ввода и 8-битовым параллельным портом вывода. Оба порта, конечно, могут быть реализованы в виде одного, и тогда речь воспроизводится через тот же самый двунаправленный порт, через который она была сначала записана.
В процессе сбора данных компьютером его резидентная программа переносит информацию из 8-разрядного АЦП и последовательно записывает ее в память. После произнесения слова процесс выборки заканчивается, а в памяти оказывается записанным цифровое представление слова hello. Как видно из рисунка, эта информация занимает адресное пространство от ячейки 1024 до примерно 3073. В данном случае информация представлена в двоичном коде при полном диапазоне изменений напряжения ±5 В. Колонка "нормализованные данные" содержит величины напряжений, эквивалентных записанным входным сигналам. Эта нормализованная информация в вольтах не имеет существенного значения для компьютера и показана здесь только для того, чтобы проиллюстрировать эквивалентность аналого-цифрового процесса выборки. В этой точке схемы синтезатора речи мы располагаем записанной в цифровом виде речью, и эту запись можно сохранять на диске или кассете для последующего воспроизведения.
Воспроизводящая часть схемы синтезатора представлена внизу рис. 6.5. Программа воспроизведения речи, хранимая в памяти компьютера,- это простая индексирующая программа, которая последовательными шагами просматривает записанную ранее информацию и выводит ее побайтно на 8-разрядный цифро-аналоговый преобразователь (ЦАП). Если ЦАП совместим с входным АЦП, то нормализация данных и их преобразование в напряжения не вызывает беспокойства. Преобразователи следят друг за другом и дают на выходе тот же самый сигнал напряжения, какой был подвергнут выборке на входе. Фактически это означает, что если у обоих преобразователей напряжения полный размах по напряжению составляет ±5 В, то выходной сигнал будет в точности соответствовать сигналу, поступившему на вход синтезатора.
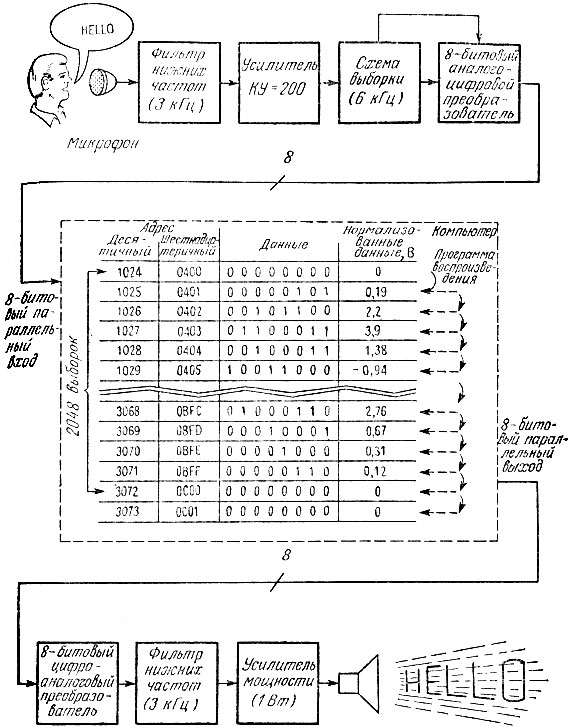
Рис. 6.5. Упрощенная схема синтезатора речи с непосредственным кодированием
Выход 8-разрядного ЦАП подсоединен к фильтру нижних частот (3 кГц), который отфильтровывает нежелательные высокочастотные компоненты, возникающие при восстановлении сигнала. На рис. 6.2, г им соответствуют прямоугольные верхушки импульсов. Затем выходной сигнал фильтра усиливается усилителем мощности и поступает на громкоговоритель. Речь, которую мы услышим из громкоговорителя, должна в точности повторять исходный речевой сигнал на входе синтезатора, за исключением небольших потерь в высокочастотной части спектра речевого сигнала, вызванных фильтром нижних частот. Иначе говоря, полученная речь по своему звучанию соответствует голосу говорящего и имеет такие же модуляцию и тональность, как и входной речевой сигнал.
В схеме синтезатора речи (рис. 6.5) не отражены лишь способ запоминания речи, используемый в компьютере при приеме сигнала, и программа воспроизведения в процессе синтеза речи. Вследствие довольно высокой частоты выборки (6 кГц) у компьютера остается примерно 17 мкс для приема и записи в память каждого байта информации. Такое требование к быстродействию компьютера исключает возможность применения программ записи и воспроизведения речи, составленных на языке Бейсик или каком-либо другом языке высокого уровня. Поэтому приемлем лишь один способ записи и воспроизведения синтезированной речи - программы, составленные на ассемблере. Насколько прост процесс кодирования речи, показывает блок-схема одной из возможных программ записи речи, приведенная на Рис. 6.6. После того как речь введена в память, можно Спускать программу воспроизведения первоначально закодированной речи. Простоту этой программы иллюстрирует рис. 6.7, где дана блок-схема программы на ассемблере, являющаяся обратной по отношению к блок-схеме рис. 6.6. Единственное важное сходство между этими двумя программами состоит в том, что программа вывода речи имеет ту же самую эквивалентную частоту выборки, что и программа ввода. Другими словами, если выборка входного сигнала производится со скоростью 6000 раз в секунду, то, естественно, желательно, чтобы закодированная информация поступала на ЦАП также со скоростью 6000 раз в секунду. Если эти скорости различны, то звучание речи на выходе синтезатора будет отличаться от исходного - подобный эффект получается, если пластинку, записанную со скоростью вращения 45 об/мин, проигрывать со скоростью вращения 33 1/3об/мин или наоборот.
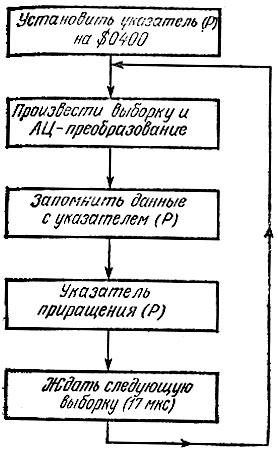
Рис. 6.6. Структурная схема возможной программы записи речи
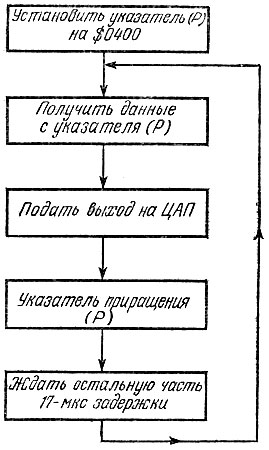
Рис. 6.7. Структурная схема возможной программы воспроизведения речи
Заменяя последний блок на рис. 6.7 таким, который будет уменьшать или увеличивать время задержки, можно получить на выходе компьютера довольно необычные звуковые эффекты. Если вообще исключить этот блок, то цикл выполнения программы займет менее 17 мкс и по своему звучанию речь на выходе будет напоминать механический голос Буратино. А если задержку в данном блоке сделать больше 17 мкс, то речь станет похожей на ворчание. При таком экспериментировании с блоком задержки фактически происходит сжатие и растяжение во времени поступающей на вход речи. При этом создается впечатление, что нормальный голос стал звучать быстрее или медленнее, сохраняя при этом все первоначально содержавшиеся в нем частоты. В действительности же, увеличивая время задержки воспроизведения с 17 до 34 мкс, мы вдвое понижаем все частотные составляющие голоса по сравнению с их исходными значениями. Поэтому, если при испытании такого простого синтезатора с кодированием и восстановлением речи получается речь искаженной тональности, то следует обратиться к блоку задержки (рис. 6.7) и, изменяя задержку, добиться правильного звучания. Запись и воспроизведение речи и других звуков с помощью этой простой системы доставит вам немало удовольствия. При творческом подходе можно попытаться объединить программу речевого вывода с игровыми и другими программами, записанными на языке Бейсик (напомним, однако, что программа воспроизведения речи должна быть записана на ассемблере).
|
ПОИСК:
|
При использовании материалов сайта активная ссылка обязательна:
http://informaticslib.ru/ 'Библиотека по информатике'