Путь № 3 (случайный поиск)
Третий путь требует от наладчика, кроме здравого смысла, еще и смелости, так как ему предстоит совершать на первый взгляд весьма "странные" и "неразумные" поступки. Чтобы настроить систему этим способом, ему следует одновременно поворачивать все рукоятки в случайных направлениях на небольшой угол (напомним еще раз, что речь идет только о ручках третьего типа). А как добиться случайности? Для этого можно каждый раз подбрасывать монету и поворачивать ручку, например, вправо, если выпадет герб, и влево, если выпадет цифра. Нужно еще и запомнить полученные смещения.
Производя такую малопроизводственную и "крамольную" операцию, наладчик опирается на замечательное свойство случайности - содержать все возможные варианты. А среди них есть и те, которые улучшают гайку, причем их немало. Надо только сделать очередной случайный шаг. Если же он приведет к ухудшению гайки, следует вернуться обратно и восстановить предыдущее положение рукояток управления автоматом. Потом снова сделать случайный шаг, слегка повернув ручки управления в новом случайном направлении.
На первый взгляд кажется, что наладчик поступает крайне неразумно. Если при настройке по методу градиента (путь № 2) наладчик наверняка улучшал качество гайки, то теперь она может даже ухудшаться. Далее, где уверенность, что наладчику не понадобится для наладки слишком долго крутить ручки? Да и кончится ли этот процесс когда-нибудь?
Все эти вопросы и недоумения связаны с тем, что случайный способ наладки автомата - способ необычный. Если же присмотреться к нему внимательно, то можно увидеть большие его преимущества перед неслучайными (регулярными) методами настройки, которые были описаны выше (пути № 1 и № 2).
Действительно, при случайном повороте ручек управления деталь может либо улучшиться, либо ухудшиться, причем оба результата следует ожидать в равной мере. Значит, в среднем каждый второй поворот рукояток будет улучшать работу станка. Как показывают опыты и расчеты, скорость настройки случайным методом значительно возрастает. Так, при работе по методу случайного поиска с системой, насчитывающей 100 ручек управления, наладчик затрачивает в среднем в 10 раз (!) меньше времени, чем при ее настройке методом градиента. Наладчик, двигаясь к цели, при неудаче возвращается обратно и снова продолжает поиск. При этом он делает разные шаги: и плохие, ухудшающие качество гайки, - тогда они немедленно устраняются, и хорошие. Среди этих хороших всегда будут просто хорошие, незначительно улучшающие гайку, и очень хорошие, сразу делающие гайку значительно лучше, чем в предыдущем случае. Это означает, что выбранное случайное направление изменения рукояток оказалось верным почти для всех рукояток и именно в этом или почти в этом направлении следует искать оптимальное положение ручек управления, которое соответствует наилучшей работе настраиваемой системы. Однако эти "очень хорошие" варианты случайного изменения пара метров автомата крайне редки и не они обеспечиваю? преимущество случайного поиска. Сила его в просто хороших вариантах, которые встречаются значительно чаще и которые поэтому легко случайно найти.
Случайный поиск в одной игре
Описанный метод настройки хорошо иллюстрируется известной детской игрой в "тепло - холодно". Читатель наверняка забавлялся в детстве этой нехитрой игрой. Правила ее просты и ясны: водящий должен найти предмет, спрятанный в комнате. Если он идет в неправильном направлении, то присутствующие ему кричат: "Холодно!" Если же он движется более или менее правильно, то его подбадривают криками: "Тепло!" Возгласы "Жарко!" сопровождают точное движение водящего на предмет.
Как ведет себя водящий? Какую стратегию поиска он выбирает? Сначала он делает шаг в случайном направлении. Услышав отрицательный ответ - "холодно", он снова делает случайный шаг. И так до тех пор, пока не услышит слова "тепло". Сделав шаг в этом направлении, он продолжает свои поиски удачного направления. Услышав "жарко", он уверенно двинется вперед.
Как легко заметить, игрок ведет себя так же, как самонастраивающаяся система, работающая методом случайного поиска. Для него сигналы "холодно", "тепло" и "жарко" определяют изменение критерия близости к цели (спрятанному предмету). Выбор им метода случайного поиска объясняется, по-видимому, тем, что он не знает других каких-либо приемов поиска. Это незнание оказало ему хорошую услугу, так как какой-либо другой метод усложнил бы ему поиск и затянул бы игру, да и сделал бы ее менее интересной.
Страсти вокруг случайного поиска
Продолжим наш разговор о самонастройке с применением метода случайного поиска.
Когда лет пятнадцать назад такой подход к решению проблемы самонастройки был предложен, он не оставил равнодушных. Все, кому пришлось сталкиваться со случайным поиском, разделились на две группы. Одни (их сначала было. большинство) откровенно возражали и небезуспешно острили по поводу случайного поведения. Другие также откровенно встали на защиту случайного поиска, видя в нем определенную перспективу для преодоления "проклятия размерностей" сложных систем.
(Это проклятие угрожает всем, кто берется настраивать очень сложную систему, имеющую большое число управляемых рукояток. Решать такие задачи пока никто не умеет.)
Споры вокруг случайного поиска постепенно утихают, ибо стало ясно, что в некоторых сложных ситуациях с большим числом рукояток управления случайный поиск является единственным методом, гарантирующим решение задачи. Если же рукояток немного и объект простой, то лучше действовать регулярными методами поиска (пути № 1 и № 2).
Надо сказать, что и до сих пор можно встретить людей, которые не могут свыкнуться с мыслью, что в определенных тяжелых случаях быстрее и надежней действовать случайным образом. Однажды мой хороший приятель после бурного обсуждения случайного поиска на очередной научной конференции умолял меня признаться, что все это чушь.
- Я все хорошо понимаю, - говорил он, - тебе это нужно для самоутверждения. Но скажи откровенно: случайный или неслучайный поиск - разве это так важно? А может быть, все-таки градиентный метод лучше? Признайся!
Я не признался.
А солидный и заслуженный теоретик авторитетно убеждал меня:
- Молодой человек, ну что вы занимаетесь случайным поиском? Я раньше тоже занимался им и доказал, что случайное поведение всегда равномерно хуже регулярного, а случайный поиск хуже регулярного поиска. Бросьте его!
Я не бросил.
В другой раз мне пришлось услышать, как один из рьяных противников случайного поиска жаловался:
- Я занимаюсь созданием сложнейших электротехнических устройств, и мне очень много приходится искать, моделируя поведение объекта на быстродействующей вычислительной машине. Так вот программисты определяют оптимальные варианты случайным поиском! Мне, в конце концов, безразлично, каким методом будет найден оптимальный вариант машины. Но ведь это же нелогично! Сколько я их ни убеждал, что случайный поиск это нонсенс, не могут понять! Если программист хоть один раз считал методом случайного поиска, его уже за уши не оттянешь. И что они в нем находят?
До сих пор страсти вокруг случайного поиска не утихли. Дело в том, что детерминизм нашего мышления отчаянно протестует против признания оптимальности случайного поведения. Приходится доказывать преимущества случайного поиска с формулами в руках. А против них возражать уже трудно.
Так постепенно случайный поиск завоевал не только право на существование, но и "эмансипировал" значительную область, где до этого царствовали детерминированные методы поиска.
Обучение при случайном поиске
Если в процессе случайного поиска наладчик еще и запомнит результаты своей работы с автоматом и последующий случайный выбор будет делать не совсем случайно, а с учетом результатов предыдущей работы, то такой метод даст еще больший выигрыш. Этот процесс называется самообучением. Наладчик станет в минимальное время настраивать и перестраивать автомат. Более того, работая методом случайного поиска с самообучением, он сможет наилучшим образом поддерживать автомат в требуемом состоянии.
Как известно, в процессе эксплуатации автомат и его инструменты изнашиваются, что ведет к повышению процента брака. Нужно все время находить такое новое положение рукояток управления, при котором брак? не будет. Делается это обычно так. При подстройке, наладчик опирается на опыт предыдущей наладки, ибо причина расстройки автомата осталась, по-видимому, одной и той же, например в виде износа резцов. Следующую за ней подстройку наладчик производит на базе предыдущих. Ее он сделает уже в один-два шага, так как раньше обучился устранять данную расстройку автомата и знает, куда, как и какие ручки крутить, чтобы настроить автомат в один прием.
Процесс самообучения во время случайного поиска напоминает обучение животных. Если животное случайно сделало то, чего от него требует дрессировщик, оно поощряется. Поощрение производится в надежде подкрепить случайное поведение пищевым рефлексом.
В случае неудачи животное наказывается в расчете на то, что его дальнейшее поведение будет иным и среди этих иных поведений встретится такое, которого ждет дрессировщик.
Надо помнить, что наказание имеет смысл лишь в том случае, когда способов поведения немного. Тогда животное, уклоняясь от наказания, сможет быстро случайно совершить требуемый образ действий. В сложной обстановке, когда вариантов поведения много, наказание вводить нецелесообразно - оно почти не ускоряет обучение, а только нервирует животное. Это и является теоретическим обоснованием преимуществ поощрения перед наказанием.
Рассмотрим простой опыт обучения лабораторных крыс в Т-образном лабиринте (он показан на рис. 76). Крысу выпускают в лабиринт с двумя ходами: направо и налево. Экспериментатор принимает решение научить крысу поворачивать направо, с этой целью он поощряет ее салом, если она поворачивает направо, и наказывает ударом тока, если она поворачивает налево. Через несколько сеансов обучения крыса уверенно сворачивает направо за салом. Она обучилась, чему способствовало и наказание и поощрение.
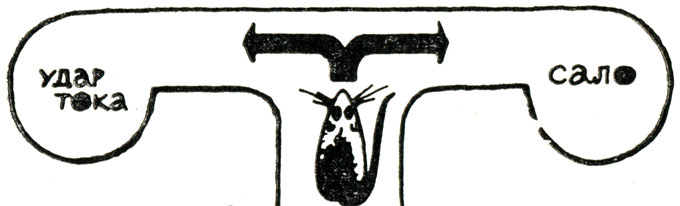
Рис. 76
Можно ограничиться одним наказанием: не давать ей сала при повороте вправо и по-прежнему "ударять" током при повороте влево. Крыса и в этом случае научится поворачивать направо, избегая наказания. Хотя процесс обучения окажется более длительным.
Если оставить только поощрение, то крыса начнет обучаться лишь после того, как случайно забредет в правый коридор.
На примере обучения крысы в лабиринте хорошо видно, что, комбинируя соответствующим образом поощрение и наказание, можно различными способами добиться одной заданной цели.
Совершенно аналогично происходит самообучение в процессе случайного поиска. Здесь так же можно комбинировать поощрение (увеличение вероятности удачного шага) и наказание (уменьшение вероятности неудачного шага) и достигать при этом цели - убыстрения работы поиска.
Мы все время говорили о наладчике, то есть о человеке, который настраивает автомат. А теперь представим, что нам надо заменить наладчика автоматической системой настройки, то есть машиной. Как легко заметить, ситуация с наладчиком, работающим по методу случайного поиска, имеет существенное преимущество - в ней очень просто заменить человека. Сделать это можно потому, что программа случайного поиска крайне проста и очень легко реализуется на автоматическом устройстве.
Автоматика случайного поиска
Схема такого устройства приведена на рисунке 77. Здесь настраиваемая система имеет определенное число управляемых параметров (ручек), которые приводятся в движение генераторами случайности. На выходе системы стоит преобразователь. Он определяет состояние настраиваемой системы и образует на выходе сигнал, который достигает нуля лишь при идеально настроенной системе. Преобразователь оценивает близость регулируемой системы к цели. Блок управления, наблюдая за этим критерием, воздействует на генераторы случайности, включая или выключая их в зависимости от поведения критерия близости.
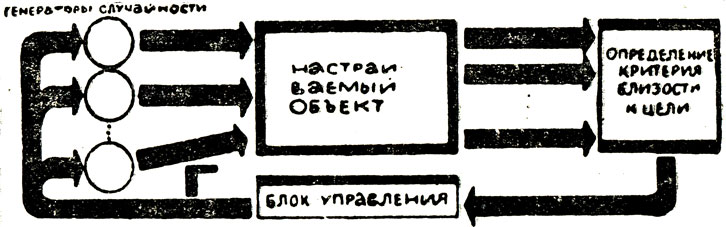
Рис. 77
Схема работает очень просто. Генераторы случайности изменяют положение ручек управления системы в случайном направлении. Если после этого настраиваемая система не стала лучше, то есть критерий близости к цели системы не уменьшился, то блок управления по каналу Г отдает команду на возврат ручек в предыдущее положение. Если же критерий уменьшился, то генераторами случайности отдается распоряжение на следующий случайный шаг, и т. д. Вот и все.
Для обучения достаточно по тому же каналу Г сообщать генераторам случайности приказы на их перестройку. Делается это следующим образом.
Одновременно с возвратом ручек управления блок управления по каналу Г отдает команду на изменение характеристик самих генераторов случайности. Изменения производятся такие, чтобы ситуация, требующая возврата ручек в первоначальное состояние, встречалась как можно реже. Это значит, что такое движение ручек управления после перестройки генераторов случайности будет встречаться значительно реже, чем до перестройки. Этим достигается более частое обращение к таким движениям ручек, которые приводят к улучшению работы регулируемой системы.
При описании рассматриваемого обучения можно использовать термины игры "тепло - холодно". Тогда обучение сведется к тому, что водящий, испробовав и получив "холодную" информацию, запомнит ее и уже с меньшей вероятностью шагнет в эту сторону в другой раз, то есть постарается реже ходить туда, где было "холодно", зато чаще будет пробовать другие направления. А исключив одно за другим "холодные", он обязательно наткнется на "теплое" или даже "горячее" направление.
Хорошо видно, что обучение в данном случае ограждает водящего от бестолкового повторения заведомо "холодных" шагов и наводит его одновременно на "теплые".
Как легко заметить, мы описали сейчас "обучение на собственных ошибках". В качестве "наказания" выбрано воздействие на генераторы случайности, уменьшающее вероятность появления неэффективных вариантов смещения ручек управления системы.
Можно воспользоваться также системой "поощрения", увеличивая вероятность тех смещений ручек, которые привели бы к улучшению качества работы системы, то есть к уменьшению критерия близости. В обоих случаях система успешно будет обучаться настройке и быстрее улучшать работу регулируемой системы, чем в случае без обучения.
Такая самообучающаяся система, как было показано, все время стремится улучшить качество своей работы. Но это качество может быть нарушено в любой момент. И тогда система должна быть готова к поиску нового положения ручек, при котором критерий близости к совершенству окажется минимальным. Но так как нулевое значение критерия, увы, не достигается, то система "не знает", чем объяснить отличие его от нуля: то ли тем, что меньшего значения критерия вообще нельзя достигнуть, то ли тем, что помеха выбила систему из наилучшего состояния. Поэтому она все время пытается улучшить себя, непрерывно пробует различные варианты изменения параметров и ищет, ищет, ищет... Одной из проблем поиска и является определение момента, когда можно считать, что объект уже настроен и поиск следует выключить.
Самонастраивающиеся системы получают в последнее время большое распространение. Действительно, хорошо и удобно, когда система сама настраивается и не требует вызова наладчика. И все же соображения удобства в данном случае играют не самую важную роль. Такие системы применяются там, где человек становится "узким местом" и не может обеспечить нормальную работу объектов в силу своих ограниченных возможностей. Иногда это просто необходимо, особенно если ситуация изменяется очень быстро и человек не в состоянии следить за ней. Кроме того, настройка большинства объектов редко бывает увлекательной операцией, и освобождение человека от этой скучной и однообразной работы является большой и благородной задачей. Но, пожалуй, самое важное применение самонастройки бывает там, где человек в принципе быть не может: это космос, "дикие" планеты, дно океана и т. д.
Но во многих случаях задача настройки больших систем типа автоматической линии бывает очень сложной. Нужны усилия огромного коллектива специалистов, чтобы ее отладить. В этом случае настройка оказывается во многом творческим процессом, и при ее автоматизации надо моделировать прежде всего творческую сторону настройки. А.это возможно лишь в том случае, если мы поймем, что такое творчество.
Так задача автоматизации настройки объекта связывается с проблемой творчества, и ее решение является первым шагом к автоматизации творческих процессов.
В заключение раздела заметим, что описанный способ автоматической настройки системы имеет предел; настраиваемая система достигает совершенства (хотя практически этого почти никогда не бывает) и поэтому не может стать лучше своего идеала.
В самое последнее время появился новый тип систем, так называемые самоорганизующиеся системы, которые не имеют предела улучшения и, подобно живым организмам, способны неограниченно улучшать свои свойства.
Но это уже другой рассказ.
|
ПОИСК:
|
При использовании материалов сайта активная ссылка обязательна:
http://informaticslib.ru/ 'Библиотека по информатике'