3.3. Списки, состоящие из списков
Те, кому удалось справиться с упражнением 3.4, наверняка заметили, что списковая структура с девятью элементами довольно громоздка. Рассмотрим типичный пример отношения stat:
Сама по себе подобная форма представления информации не так уж плоха. Но для извлечения, например, данных об автомобиле требуется следующее предложение:
X car Y if
X stat (Z х у z XI Y1 Z1 Y x1)
В результате значение, подлежащее определению, будет присвоено переменной Y. Но данное предложение будет работать, пока списки в базе данных содержат девять членов и никак не больше.
Указанный недостаток можно преодолеть, если составлять список из нескольких подсписков, в каждый из которых включать небольшое число членов. Если в какой-то момент времени подсписков становится слишком много, их, в свою очередь, можно объединить в подсписки более высокого уровня и т. д. С шестью подсписками, состоящими не более чем из шести элементов, работать довольно просто. А ведь это позволяет организовать доступ к 36 элементам данных. В интересах программиста включать в один и тот же подсписок данные, семантически связанные друг с другом. В нашем примере целесообразно один подсписок связать с профессией и включить в него специальность, годовой доход и стаж; другой подсписок будет содержать данные о склонностях человека: хобби, любимом музыкальном жанре и т. д. Это сделает программу легкой для понимания и удобной для использования и модификации. Более того, пользователям необязательно даже знать, как различные элементы объединяются в списки; они должны уметь только составлять запросы.
Предположим, что о каждом человеке надо хранить следующую информацию: возраст, дату и место рождения, адрес, профессию, годовой доход, стаж, название места работы и ее адрес, имя супруги (супруга), ее (его) возраст и число совместно прожитых лет. Будем считать всех интересующих нас людей совершеннолетними. Это не приведет к потере общности, поскольку в случае необходимости можно определить отношение, позволяющее отделить совершеннолетних от детей. Всю указанную информацию, представляющую собой смесь числовых и символьных данных, можно хранить в списках следующей структуры:
Bill stat ((42 Jan-25-1943 Leeds) (19 West-St Leeds) (butcher 1200 23) (self 8 York-Rd Leeds) (Jane 39 18))
Tom stat ((24 Nov-3-1960 Dover) (7 Eglington-St Andover) (engineer 8000 3) (Ace Engineers 17 Sprocket-St Salisbury) ()) Ted stat ((31 Mar-9-1954 Bath) (2 Brook-St Bath) () () (Laura 30 5))
Helen stat ((29 Aug-30-1956 Merton) (15 Albert-St Merton) (typist 6500 3) Hill-and-Son 6 Nelson-Rd Wimbledon) (Jack 29 5))
Joe stat ((67 Oct-9-1917 Bristol) (23 South-Rd Cheltenham) (retired () 5)() (Sarah 64 41))
Betty stat ((35 May-3-1950 Larne) (18 Antrim-Rd Lame) (nurse 950013)(St-Marys-Hospital 226 Longpark Belfast) (James 38 13))
Читатели имеют возможность заменять любые записи и добавлять нужные им данные. Информация хранится в следующей форме:
Извлечь любой нужный подсписок можно с помощью правил, аналогичных приведенным ниже:
X birth Y if
X stat(Y|Z)
X address Y if
X stat(ZY|x)
В данном случае переменные будут сопоставляться не с отдельными элементами данных, а с целыми подсписками. Так, согласно первому правилу переменная Y будет сопоставляться с подсписком, содержащим дату и место рождения. Запрос, позволяющий получить эту информацию, может выглядеть так:
В ответ на этот запрос система сообщит
Bill (42 Jan-25-1943 Leeds)
[Билл (42 25 января 1943 года Лидс)
и т. д.
Чтобы извлечь нужный элемент из подсписка, можно использовать правила типа
X age Y if
X stat ((Y|Z)|x)
Это правило позволяет получить информацию о возрасте, которая находится в первом элементе первого списка. Информацию о профессии можно извлечь с помощью следующего правила:
X job Y if
X stat (Z x (Y|у)|z
Таким образом, данные о профессии находятся в первом элементе третьего списка. Читатели теперь без труда составят отношения, предназначенные для извлечения всей остальной информации.
Упражнение 3.5
а. Составьте отношения для извлечения оставшихся под списков.
б. Определите, сколько элементов находится в каждом из пяти списков, и напишите отношения для доступа к этим элементам.
Упражнение 3.6
Составьте отношения для определения:
а. Кто состоял в браке одно и то же число лет?
б. У кого одинаковый стаж?
в. У кого стаж совпадает с числом лет, прожитых в браке?
г. Кто живет там, где родился?
д. Кто живет и работает там, где родился?
Тем читателям, которые хотят самостоятельно выполнить упражнения 3.5 и 3.6, рекомендуется пока не заглядывать дальше.
Поскольку каждый обобщенный список состоит из пяти подсписков, для доступа к ним необходимо пять правил. Ниже приведены эти правила, хотя в принципе читатели могут выбрать для отношений любые другие имена:
X birth Y if
X stat(Y|Z)
X home Y if
X stat(ZY|x)
X work Y if.
X stat(ZxY|y)
X firm Y if
X stat(ZxyY|y)
X marriage Y if
X stat(ZxyzY|X1)
С помощью каждого из этих правил можно получить сразу всю информацию, относящуюся к какой-то одной стороне личности. Например, запрос
позволяет определить имена всех тех, кто фигурирует в базе данных вместе с информацией о месте их работы.
Подсписки содержат 3, 3, 3, 4 и 3 элемента соответственно. Таким образом, общее число элементов данных равно 16. Очевидно, что для извлечения этих элементов потребуется 16 правил. Отметим, что в четвертом подсписке содержится четыре элемента: название фирмы, номер дома, название улицы, город. Вот эти 16 правил:
X aged Y if
X birth (Y|Z)
X birthdate Y if
X birth (ZY|x)
X birthplace Y if
X birth (ZxY|y)
X home-no Y if
X home(Y|Z)
X home-st Y if
X home(ZY|x)
X home-place Y if
X home(ZxY|y)
X job Y if
X work(Y|Z)
X earns Y if
X work(ZY|x)
X years-in-job Y if
X work(ZxY|y)
X employer Y if
X firn (Y|Z)
X work-no Y if
X firm(ZY|x)
X work-st Y if
X firm(ZxY|y)
X workplace Y if
X firm(ZxyY|z)
X spouse Y if
X marriage (Y|Z)
X spouse-age Y if
X marriage (Z Y|x)
X married Y if
X marriage (Z x Y|y)
В них использованы ранее определенные отношения, предназначенные для извлечения сразу всех данных, принадлежащих подсписку. Отметим, что можно получить данные из большего по размеру списка с помощью отношений вида
X aged Y if
X stat ((Y|Z)|x)
Это последнее правило, ссылающееся на отношение stat, может быть быстрее выполнено, поскольку в нем фигурируют только два отношения. С другой стороны, метод, заключающийся в использовании дополнительных правил для извлечения элементов данных из подсписка, определенного с помощью отношения stat, оперирует с более коротким списком неизвестных. Особенно это заметно для подсписков, расположенных в конце главного списка. Кроме того, преимущество этого метода также в том, что образ неизвестного списка одинаков сразу для нескольких правил. Чтобы убедиться в этом, достаточно сравнить правила, описывающие возраст и дату рождения, с правилами, описывающими место жительства.
Таким образом, программа, реализующая этот метод, во-первых, удобнее для понимания и, во-вторых, в случае добавления новых данных соответствующие им правила будут иметь ту же самую структуру, что и уже имеющиеся в программе правила. Для включения новых правил можно использовать команду cedit, упомянутую во второй главе. Отметим, что во всех выше описанных отношениях предусмотрена возможность расширения базы данных. Именно поэтому отношение marriage определяется так, как показано ниже:
X marriage Y if
X stat (Z х у z Y|X1)
а не так:
X marriage Y if
X stat (Z x у z Y)
Последнее правило дает возможность извлекать нужные данные, так как Y является последним подсписком в главном списке. Но при добавлении новых подсписков это правило надо модифицировать. Аналогично правило
X homeplace Y if
X home (Z x Y|у)
хотя и позволяет определить город, в котором живет тот или иной человек, но проигрывает по сравнению с правилом
X homeplace Y if
X home (Z x Y|у)
поскольку последнее не требует модификации в случае пополнения данных, принадлежащих подсписку.
Ясно, что много полезной информации может быть получено в результате анализа данных, находящихся в подсписках. Ниже дано несколько примеров, позволяющих получить эту информацию. Предположим, что необходимо найти всех тех, кто работает в том же городе, в котором живет:
all (x у: х homeplace у and x workplace у)
[определить все (х у: х живет в городе у и х работает в городе у)]
Bill Leeds
[Билл Лидс]
No (more) answers
[Ответов (больше) нет].
Однако попытка определить всех тех, кто работает не там, где живет, с помощью запроса
приводит к неудаче. В ответ на этот запрос будут получены следующие данные:
Bill Leeds Leeds
[Билл Лидс Лидс]
Tom Andover Dover
[Том Эндувр Дувр]
Helen Merton Wimbledon
[Эллен Мертон Уимблдон]
Betty Larne Belfast
[Бетти Лан Белфаст]
No (more) answers
[Ответов (больше) нет]
Понятно, что это не совсем то, что хотелось. Попробуем проанализировать последний запрос. Кажется, что поскольку две переменные у и z используются для названий городов, программа должна сопоставить им разные значения. Но это не так. Сначала программа ищет, какие константы можно сопоставить переменным х и у, причем эти константы должны входить в отношение homeplace. В результате х будет поставлено в соответствие Bill, a y - Leeds. Затем программа ищет пример отношения workplace, первым аргументом которого является Bill. После успешного завершения поиска несвязанной переменной присваивается значение Leeds. И, наконец, выводится первый из приведенных выше ответов. Заметим, что в запросе нет никакой информации о том, что у и z не могут принимать одно и то же значение. В процессе обработки запроса для хранения значений переменных х, у и z выделяется специальная структура, называемая стеком. После того, как первое решение найдено, значение г выталкивается из стека, и программа старается сопоставить с г другое значение. Процесс поиска альтернативных решений называется поиском с возвратом или бэктрекингом. Для переменной z на данном шаге других альтернативных значений не существует. Поэтому программа возвращается к оценке первой части запроса Bill home-place у. Поскольку новых значений для переменной у не существует, вся описанная процедура повторяется, только в качестве х теперь используется значение Тот.
Стек представляет собой структуру данных, которая занимает ряд смежных позиций памяти. Очередная порция данных помещается в стек с помощью операции PUSH, а удаляется из стека с помощью операции POP. Стек часто называют структурой типа "последним пришел - первым ушел"*. Это означает, что порция данных, помещенная в стек последней, удаляется первой. Функционирование стека напоминает работу автоматической раздаточной машины; отличие состоит в том, что данные и добавляются в стек и извлекаются из стека пользователями. Переменная вершина стека указывает на позицию, в которой размещается последний помещенный в стек элемент данных. Во многих ЭВМ стек реализован так, что "растет" сверху вниз, т. е. положение вершины стека остается неизменным, Но все это в принципе не касается тех, кто программирует на Прологе.
* (Часто используется аббревиатура LIFO (last in first out)- Прим. пер.)
На рис. 31 изображены диаграммы, иллюстрирующие выполнение операций со стеком; элемент Е3 помещается в стек последним - следом за элементами Е1 и Е2, а выталкивается первым. Операции со стеком широко используются Пролог-системой в процессе оценки применимости правил. В связи с этим программист должен сознавать, что существует опасность чрезмерного роста стека, и принимать необходимые меры для ее устранения. К более детальному рассмотрению этого вопроса мы перейдем позднее.
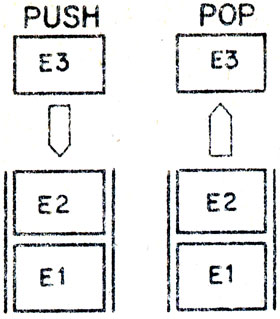
Рис. 3.1. Операции со стеком: PUSH - помещение элемента в стек; POP - выталкивание элемента из стека
Упражнение 3.7
Вернемся к обсуждавшемуся ранее вопросу. Может быть запрос
позволит решить проблему? Если для проверки Вы используете ЭВМ, то поймете, что это не так. Но тем не менее этот запрос очень похож на тот, который нам нужен.
Упражнение 3.8
Составьте запросы, позволяющие определить:
а. Кто зарабатывает более 8000 долл. и каков их точный годовой доход?
б. Каковы имена людей старше 30 лет, чей годовой доход менее 10 000 долл.?
в. Кто работает у себя дома?
г. Кто дольше, чем Том, работает на одном месте?
д. Кто женат дольше, чем Джо?
|
ПОИСК:
|
При использовании материалов сайта активная ссылка обязательна:
http://informaticslib.ru/ 'Библиотека по информатике'