6. Оптимальный код
Как уже говорилось, общее правило при построении экономного кода следующее: чаще встречающиеся сообщения нужно кодировать более короткими кодовыми словами, а более длинные слова использовать для кодирования редких сообщений. Это правило и было реализовано в рассмотренном выше методе кодирования Фано. Но всегда ли метод Фано приводит к наиболее экономному коду? Оказывается, нет. Способ построения оптимального кода, который мы здесь изложим, потребует от нас более тонких рассуждений.
Пусть сообщения A1, А2, ..., AN имеют вероятности р1, р2, ..., pN (р1 ≥ р2 ≥ ... ≥ pN) и кодируются двоичными словами a1, a2, ..., aN, имеющими длины l1, l2, ..., lN. Постараемся выяснить, какими свойствами должен обладать двоичный код, если он оптимален.
1. В оптимальном коде менее вероятное сообщение не может кодироваться более коротким словом, т. е. если pi < рj, то li ≥ lj.
Действительно, в противном случае поменяем ролями I кодовые обозначения для Ai и Аj. При этом средняя длина кодовых слов изменится на величину
т. е. уменьшится, что противоречит определению оптимального кода.
2. Если код оптимален, то всегда можно так перенумеровать сообщения и соответствующие им кодовые слова, что
р1 ≥ р2 ≥ ... ≥ pN и при этом
l1 ≤ l2 ≤ ... ≤ lN. (1)
В самом деле, если рi > рi+1, то из свойства 1 следует, что li ≤ li+1. Если же pi = pi+1, но li > li+1, то переставим сообщения Аi и Ai+1 и соответствующие им кодовые слова. Повторяя эту процедуру нужное число раз, мы и получим требуемую нумерацию.
Из неравенств (1) следует, что сообщение AN кодируется ловом aN наибольшей длины lN.
3. В оптимальном двоичном коде всегда найдется, по крайней мере, два слева наибольшей длины, равной lN, и таких, что они отличаются друг от друга лишь в последнем символе.
Действительно, если бы это было не так, то можно было бы просто откинуть последний символ кодового слова aN, не нарушая свойства префиксности кода. При этом мы, очевидно, уменьшили бы среднюю длину кодового слова.
Пусть слово at имеет ту же длину, что и aN и отличается от него лишь в последнем знаке. Согласно свойствам 1 и 2 можно считать, что lt = lt+1 = ... = lN. Если t ≠ N-1, то можно поменять ролями кодовые обозначения at и aN-1, не нарушая при этом неравенств (1).
Итак, всегда существует такой оптимальный код, в котором кодовые обозначения двух (наименее вероятных) сообщений AN-1 и AN отличаются лишь в последнем символе.
Отмеченное обстоятельство позволяет для решения задачи рассматривать только такие двоичные коды, у которых кодовые обозначения aN-1 и aN для двух наименее вероятных сообщений AN-1 и AN имеют наибольшую длину, отличаясь лишь в последнем символе. Это значит, что концевые вершины aN-1 и aN кодового дерева искомого кода должны быть соединены с одной и той же вершиной а предыдущего "этажа" (см. рис. 12).
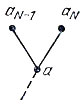
Рис. 12
Рассмотрим новое множество сообщений A(1) = {A1, А2, ..., AN-2, А} с вероятностями p1, p2, ..., pN-2, p = pN-1 + pN. Оно получается из множества {A1, А2, ..., AN-2, AN-1, AN} объединением двух наименее вероятных сообщений AN-1, AN в одно сообщение A. Будем говорить, что A(1) получается сжатием из {А1, А2, ..., AN-2, AN-1, AN}.
Пусть для A(1) построена некоторая система кодовых обозначений K(1) = {a1, a2, ..., aN-2, a}, иными словами, указано некоторое кодовое дерево с концевыми вершинами a1, a2, ..., aN-2, a. Этой системе можно сопоставить код К = {a1, a2, ..., aN-2, aN-1, a} для исходного множества сообщений, в котором слова aN-1 и aN получаются из слова а добавлением соответственно 0 и 1. Процедуру перехода от К(1) к К назовем расщеплением.
Справедливо следующее утверждение, открывающее путь для построения оптимального кода:
Если код К(1) для множества сообщений A(1) является оптимальным, то оптимален также и код К для исходного множества сообщений.
Для доказательства установим связь между средними длинами l‾ и l'‾ слов кодов K и K(1). Она, очевидно, такова:
Предположим, что код K не является оптимальным, т. е. существует код К1 со средней длиной l1‾ < l‾. Как отмечалось, можно считать, что концевые вершины a˜N-1 и a˜N его кодового дерева (см. рис. 13) соответствуют кодовым обозначениям для наименее вероятных сообщений AN-1 и AN. Тогда эти обозначения отличаются лишь в последнем символе. Рассмотрим код K(1)1 = {a˜1, ..., a˜N-2, а˜}, в котором слово а˜ получается из a˜N-1 отбрасыванием последнего символа. Средние длины l‾1 и l'‾1 связаны соотношением, аналогичным (2):
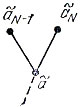
Рис. 13
Из неравенства l1‾ < l‾ следует l'‾1 < l'‾, что противоречит оптимальности кода K(1). Утверждение доказано.
Теперь ясно, что для построения оптимального кода южно использовать последовательные сжатия исходного множества сообщений.
Проиллюстрируем процесс последовательных сжатий и расщеплений на примере множества из пяти сообщений с вероятностями p1 = 0,4; р2 = р3 = р4 = р5 = 0,15. Процесс этот отражен в следующей таблице:
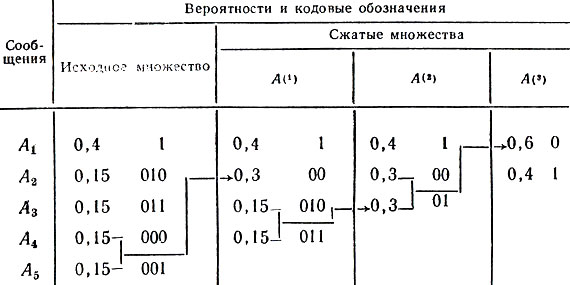
Таблица 12
Каждое из множеств А(1), А(2), А(3) получается сжатием предыдущего множества. Множество А(3) состоит из двух сообщений, поэтому оптимальный код K(3) содержит два кодовых обозначения - 0 и 1. Последовательное расщепление K(3) дает оптимальный код для исходной системы сообщений.
Средняя длина l‾ кодовых слов, равная 0,4 + 4 × 3 × 0,15 = 2,2, является, как это следует из предыдущего, минимально возможной для данного множества сообщений.
Описанный метод кодирования был предложен в 1952 г. американским математиком Д. А. Хаффменом и называется его именем. Сравним теперь оптимальный код из таблицы 12 с кодом Фано для того же множества сообщений, который строится ниже.
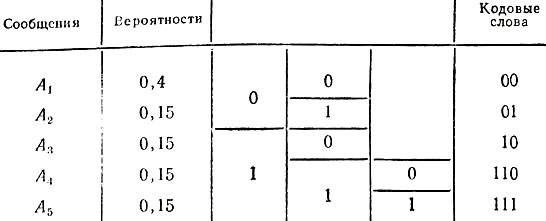
Таблица 13
Подсчитаем среднюю длину l‾F кодовых слов в этом случае:
Следовательно, метод кодирования Фано не всегда приводит к оптимальному коду.
Как и метод Фано, метод кодирования Хаффмена может быть распространен на случай кодового алфавита, состоящего из произвольного числа символов. Этот вопрос рассмотрен в книге [2].
|
ПОИСК:
|
При использовании материалов сайта активная ссылка обязательна:
http://informaticslib.ru/ 'Библиотека по информатике'