6. Применение ЭВМ в стилистических исследованиях
Оценка особенностей текстов, принадлежащих к различным языковым и речевым стилям, выявление индивидуальных стилистических особенностей авторов представляют собой достаточно сложный процесс, поскольку для решения таких задач необходимо исследовать тексты большой длины. Именно по этой причине ЭВМ все чаще используется для проведения подобных исследований.
Научные работы по этой проблеме, проводимые с помощью ЭВМ и без нее, показывают, что для оценки текстов, принадлежащих к различным языковым (художественный, научный, публицистический, деловой, драматургия, поэзия), речевым и авторским стилям, могут быть использованы следующие текстовые характеристики: 1) длина слова в буквах; 2) длина предложения в словах; 3) частота употребления существительных; 4) частота употребления прилагательных; 5) частота употребления глаголов; 6) частота употребления наречий; 7) структура предложения; 8) частота употребления подлежащего; 9) частота употребления сказуемого; 10) типы используемых придаточных предложений; 11) частота употребления временных форм глагола; 12) частота употребления отдельных служебных слов (частиц, союзов и т. п.); 13) частота употребления слов определенных семантических групп; 14) другие характеристики.
Допустим, что в процессе анализа трех стилей какого-либо языка (драматургия, публицистика и научный стиль) средняя длина слова* в текстах этих стилей оказалась равной соответственно 4,74; 5,6 и 6,46 буквы. Видно, что тексты драматургии резко отличаются от текстов публицистических и научных. Еще более интересные результаты дает подсчет употребительности слов по их длине в трех различных стилях (табл. 14).
* (Средняя длина слова (Lcр) определялась по формуле
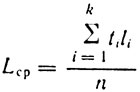
где ti - количество слов в тексте длиной в li, букв; n - общее число слов в тексте; k - наибольшее количество букв в слове.)
Из таблицы 14 видно четкое деление текстов, относящихся к различным языковым стилям.
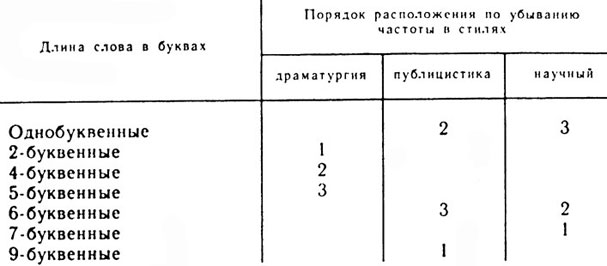
Таблица 14
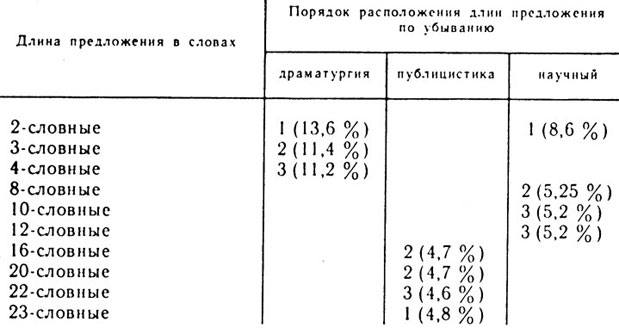
Таблица 15
Еще более характерны показатели средней длины предложения* в этих трех видах текстов. Они соответственно равны 6,63 слова (драматургия), 17,1 слова (публицистика) и 12,1 слова (научный стиль). Более детальные данные по их употребительности представлены в таблице 15.
* (Средняя длина слова (Pcр) определялась по формуле
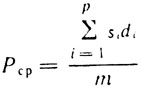
где si - число предложений в тексте длиной в di, букв; m - общее число предложений в тексте; p - наибольшее количество слов в предложении)
Объединим все только что сказанное в таблицу 16 формальных признаков для определения принадлежности текста к трем языковым стилям.
Подсчет только что приведенных характеристик для любого текста можно поручить ЭВМ. Она это сделает с большой точностью и сама определит, к какому стилю относится этот текст.
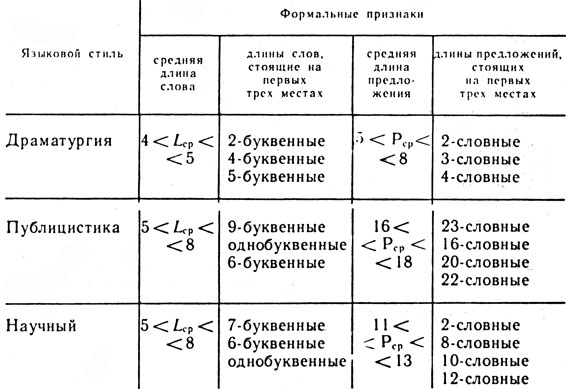
Таблица 16
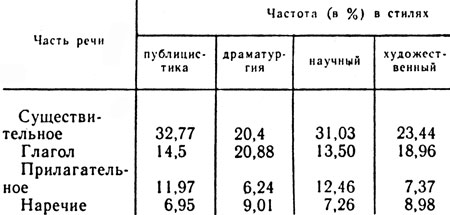
Таблица 17
Алгоритм таких действий ЭВМ может быть представлен так, как показано на рисунке 17.
Еще большей диагностической силой обладают характеристики 3-14 из числа приведенных выше.
Например, частота употребления существительных, глаголов, прилагательных и наречий в русских текстах представлена в таблице 17. Если внимательно рассмотреть ее, можно заметить, что для каждого стиля характерно свое распределение указанных частей речи.
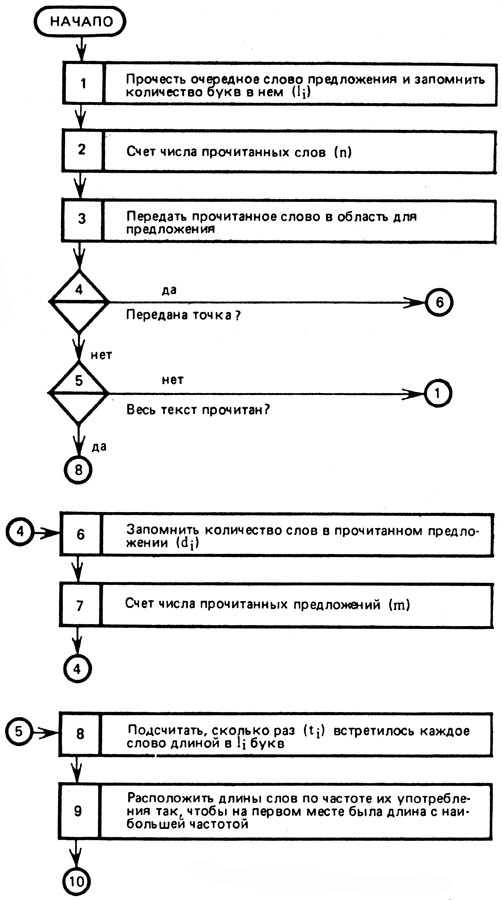
Рис. 17
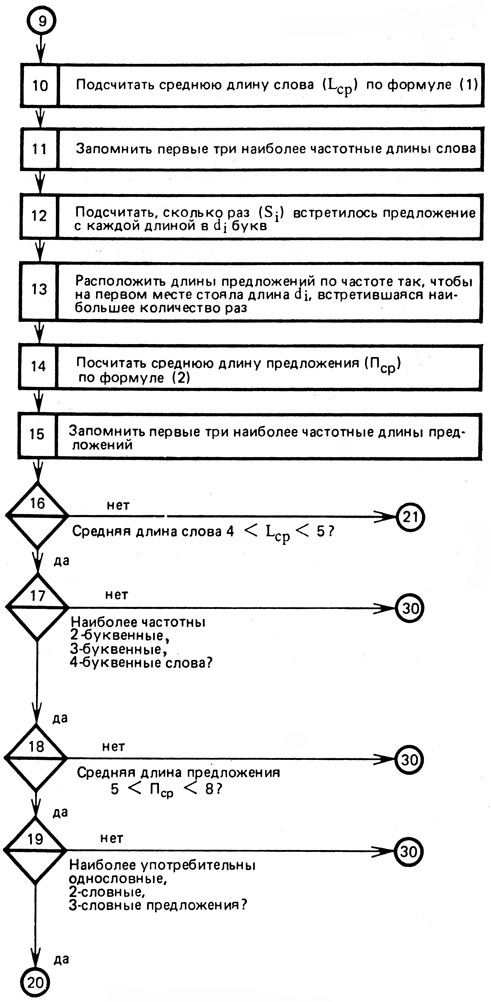
Рис. 17 (продолжение)
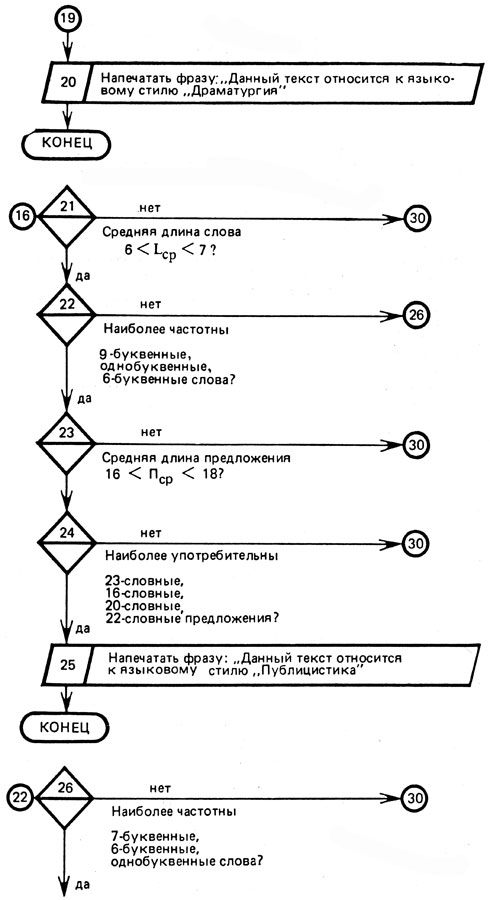
Рис. 17 (продолжение)
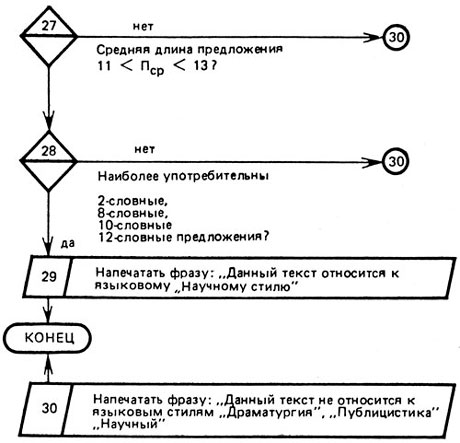
Рис. 17 (окончание)
Интересные данные можно получить, если использовать для определения различий в стилях структуры предложений, зафиксированных (в %) в соответствующих текстах (табл. 18).
Интересной характеристикой языкового, речевого и авторского стилей является употребительность различных типов придаточных предложений. В таблице 19 приведены данные об употребительности в трех языковых стилях некоторых типов придаточных предложений, а в таблице 20 даны сведения о частоте тех же типов в произведениях отдельных авторов. Как видно, и эти показатели весьма своеобразны для языковых и авторских стилей.
Однако практическое использование машиной всех указанных характеристик весьма затруднительно. Дело в том, что ЭВМ по форме слова не может определить его класс, все его грамматические характеристики (род, число, падеж, время и т. п.). Так же по формам слов невозможно определить со 100-процентной вероятностью тип предложения вообще и тип придаточного предложения в частности. Поэтому использование машиной указанных стилевых показателей возможно в том случае, когда текст перед вводом в ЭВМ специальным образом готовится. С помощью специальной системы индексов (помет) указывается часть речи, к которой относится каждое слово предложения, время глагола, тип придаточного предложения и т. п. Например, для кодирования частей речи русского языка может быть использована таблица 21. Коды типов придаточных предложений приведены в таблице 22, а в таблице 23 даны индексы для кодирования отдельных грамматических значений слов.
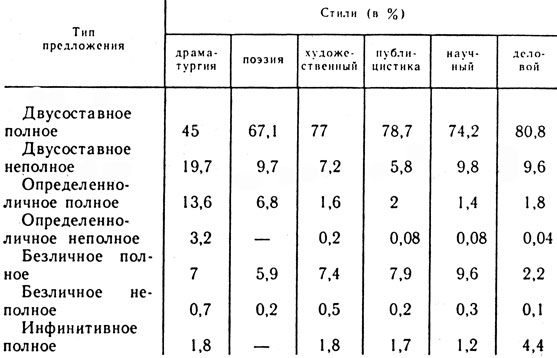
Таблица 18
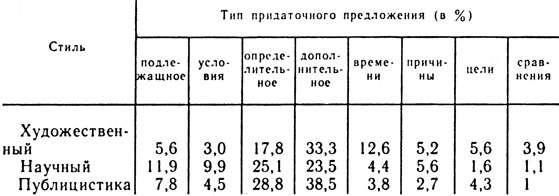
Таблица 19
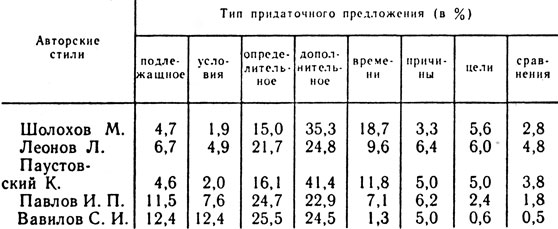
Таблица 20
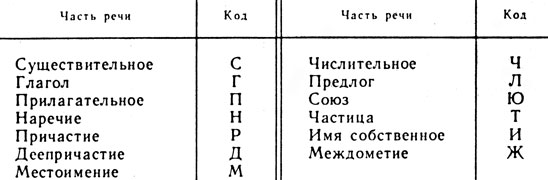
Таблица 21

Таблица 22
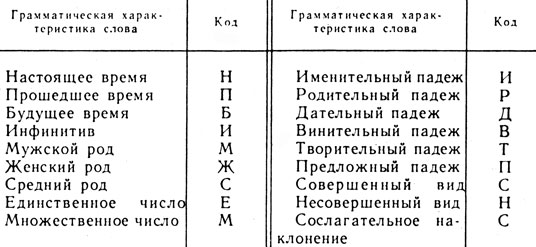
Таблица 23
Кодирование текстов для обработки на ЭВМ для определения их стилистических особенностей с привлечением сразу нескольких характеристик проводится в следующем порядке. Первым индексом у каждого слова ставится индекс части речи. Далее указывается число, затем род (для существительного, прилагательного, числительного, причастия, глагола). Следующий индекс указывает время (для глагола, причастия) или падеж (для существительного, местоимения, прилагательного, числительного).
Признак принадлежности к тому или иному типу придаточных предложений ставится после подчинительного союза (за знаком класса слова), а если нет подчинительного союза - за точкой.
Например, будем использовать для стилистической характеристики некоторого текста такие показатели:
- употребительность существительного;
- употребительность глагола;
- употребительность имени собственного;
- употребительность наречия;
- употребительность временных форм глагола;
- употребительность типов придаточных предложений.
Тогда слова двух следующих сложных предложений (с придаточными времени и дополнительным) получат такие индексы (см. табл. 22-24):
КОГДА-ЮВ СОВСЕМ-Н СТЕМНЕЛО-ГП, МУР- ЗУК-И ПОДНЯЛСЯ-ГП. ЖИЗНЬ-С УЛЫБАЕТСЯ-ГН ТОМУ-М, КТО-ЮД УЛЫБАЕТСЯ-ГН ЖИЗНИ-С
В этом случае ЭВМ, ориентируясь на данные, при-веденные в таблицах 21-23, определит принадлежность текста к тому или иному стилю и стилевые особенности текста.
|
ПОИСК:
|
При использовании материалов сайта активная ссылка обязательна:
http://informaticslib.ru/ 'Библиотека по информатике'