Элементарное сопоставление с образцом
Хотя Лисп сам по себе не имеет встроенного сопоставления с образцом, легко написать на этом языке функции, осуществляющие сопоставление образцов. Можно поэтому сказать, что Лисп является хорошим языком для реализации сопоставления образцов.
Многие реализованные подмножества языка с возможностями сопоставления имеют те свойства, которые будут продемонстрированы нами ниже.
В сопоставлении участвуют подобные s-выражения
Начнем с понятий списков образцов и списков фактов. Часто список, соответствующий факту, будет использоваться для представления истинных утверждений, относящихся к некоторому реальному или вымышленному миру. На данный момент и факты, и образцы будут ограничены списками атомов. В образцах, однако, могут содержаться некоторые специальные атомы, не используемые в фактах, например атомы из одного символа? или > .
.

Ниже мы построим функцию, называемую MATCH (СОПОСТАВЛЕНИЕ), которая будет сопоставлять один образец и один факт. Эта функция будет интенсивно применяться для иллюстраций того, как реализуются и используются функции сопоставления. Сначала, однако, посмотрим, что, собственно, ищет функция MATCH.
Когда с некоторым фактом сравнивается образец, не содержащий специальных атомов, то сопоставление считается успешным только тогда, когда они в точности одинаковы, так что каждая позиция занята у них одинаковыми атомами. Если мы сопоставляем (ЦВЕТ ЯБЛОКО КРАСНЫЙ), как образец, с идентичным фактом (ЦВЕТ ЯБЛОКО КРАСНЫЙ), то сопоставление будет, разумеется, успешным:
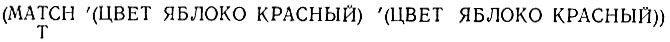
Но сопоставление (ЦВЕТ ЯБЛОКО КРАСНЫЙ) с (ЦВЕТ ЯБЛОКО ЗЕЛЕНЫЙ) не проходит:
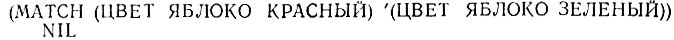
Выделенный атом? обладает тем свойством, что он сопоставим с любым атомом. Это сильно расширяет полезные возможности функции MATCH:

Атом  также расширяет возможности функции MATCH, благодаря тому что он сопоставим с одним или несколькими атомами. Образцы, содержащие
также расширяет возможности функции MATCH, благодаря тому что он сопоставим с одним или несколькими атомами. Образцы, содержащие  , могут оказаться сопоставимыми с фактами, у которых больше атомов, чем в образце:
, могут оказаться сопоставимыми с фактами, у которых больше атомов, чем в образце:
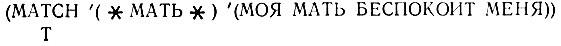
Теперь посмотрим, как можно было бы реализовать функцию MATCH. Мы будем придерживаться стратегии движения вдоль образца и вдоль факта атом за атомом, проверяя, совпадают ли атом образца и атом факта в каждой позиции. Переводя на терминологию системы Лисп, мы строим функцию, которая проверяет первые элементы обоих списков и, если сравнение успешно, движется дальше, вызывая себя рекурсивно для работы над CDR от этих списков:

В первом предложении функции COND проверяется, не исчерпаны ли списки, если да, то рекурсия заканчивается. Теперь, поскольку мы хотим, чтобы сопоставление завершалось удачно не только, когда атомы образца и атомы факта совпадают, но также и в случае, когда атомом образца является вопросительный знак, то мы должны слегка обобщить процедуру:

Мы также должны проверить, не короче ли один из списков другого - иначе функция MATCH собьется, если более короткий список сопоставляется с началом более длинного.

Рассмотрим примеры.
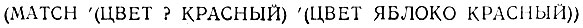
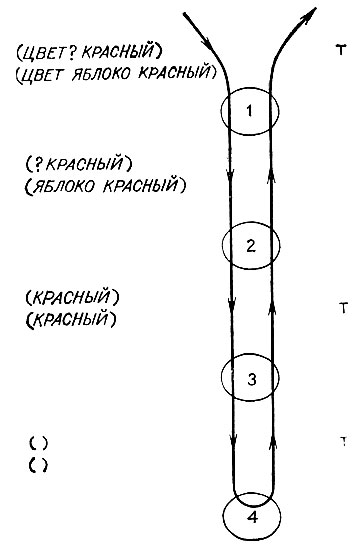
Рис. 14.1. В MATCH совершается рекурсия, пока текущий первый атом в образце является либо ? либо совпадает с текущим первым атомом в факте. При одновременном достижении конца образца и факта на нижнем уровне возвращается Т и передается наверх
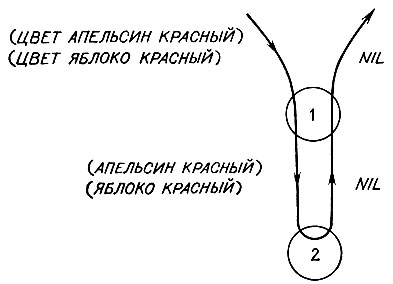
Рис. 14.2. Если в ходе рекурсии MATCH встречается с образцом и фактом, которые не согласуются в первой позиции, то на нижнем уровне возвращается NIL и передается наверх
В качестве окончательного результата мы получим Т, как показано на рис. 14.1. Но если мы обратимся к
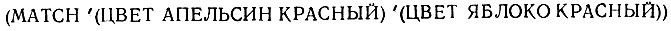
то мы получим в результате NIL, как показано на риc. 14.2.
Теперь, чтобы сильно расширить возможности нашей функции сопоставления, мы включим в нее свойство, благодаря которому * будет сопоставимо с одним или более атомами. Вот пробная версия:

Переключаемое звездочкой предложение COND в этой версии обеспечивает рекурсивное обращение к MATCH. Срабатывает одна из грех возможностей: * ни с чем не сопоставима, в этом случае она выбрасывается и сопоставлению подвергается остальная часть образца; * сопоставима с одним атомом, в этом случае отбрасывается и ?*, и этот атом; ?* сопоставима с двумя или более атомами, в этом случае мы продолжаем действовать в рекурсивной манере, сохраняя * в образце, отбрасывая первые атомы, с которыми она сопоставима успешно.
Второй член в указанном предложении COND на самом деле излишен, если может сопоставляться с любым числом атомов, включая нулевое их число. От него можно избавиться, и функция MATCH будет все равно работать. В этом случае MATCH отделяет и сопоставляет оставшуюся часть Р с нетронутым списком D или же сохраняет * и передвигается на один атом в данных в предположении, что это один из атомов, сопоставимых со *. Вероятно, моделирование поможет прояснить работу рекурсии при этих обстоятельствах. См. рис. 14.3.
С другой стороны, в этой функции COND может быть опущено первое предложение, а не второе. Тогда * должна будет обязательно сопоставима, по крайней мере с одним атомом, как и определялось первоначально.
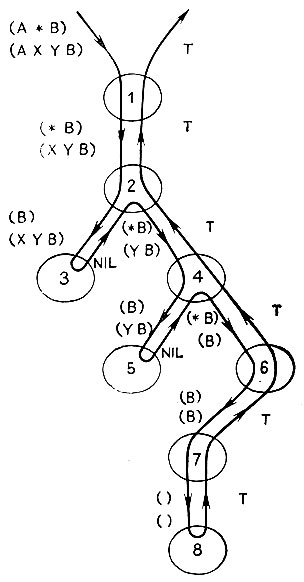
Рис. 14.3. Когда в образце встречается атом, он замещает произвольное число элементов. Функция MATCH отбрасывает либо *,либо первый элемент в факте на каждом уровне рекурсии. Попытка отбросить * делается перед приемом следующего элемента факта, который имеет место при сохранении *
Одновременные присваивания придают дополнительные возможности операциям сопоставления
Следующее направление усовершенствования лежит в обобщении функции MATCH таким образом, чтобы она присваивала определенные значения, когда сопоставление проходит успешно. Атомы, которые начинаются со знаков > или действуют как ? и * в процессе сопоставления, но в случае успеха их значениями становится то, с чем они сопоставимы. Переменные с > должны иметь в качестве значений атомы, тогда как переменные с * должны иметь в качестве значений списки сопоставляемых атомов. Обозначение >, использованное здесь, должно наводить на мысль о "заталкивании" значений в переменные с предлогом >. Разработчики языков сопоставления очень искусны в выборе синтаксиса.

Сопоставление с > и присваивание могут быть реализованы путем использования двух новых функций, ATOMCAR и ATOMCDR, и добавления предложения в COND, в котором АТОМСАР выделяет первый символ в атоме для его изучения. Обратите внимание на использование SET для присваивания значения переменной образца тому элементу в данных, с которым оно сопоставимо.
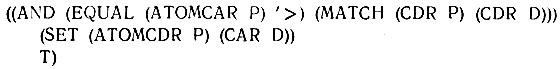
Таким образом, вначале мы убеждаемся, что атом начинается с >, и остальная часть сопоставления проходит успешно. Если так, то мы делаем указанные присваивания значений и передаем Т на следующий уровень вверх.
На самом деле, в большинстве систем Лиспа отсутствуют функции ATOMCAR и ATOMCDR, но часто имеется что-то вроде функций EXPLODE и IMPLODE*. Функция EXPLODE появляется в программе, чтобы разбить атом на список из составляющих его символов, каждый из которых появляется как отдельный атом:

Функция IMPLODE выполняет дополнительную к EXPLODE операцию, превращая список атомов в один атом:
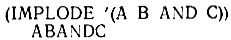
Используя EXPLODE и IMPLODE, легко определить ATOMCAR и ATOMCDR:

* (В реализации Лиспа на Фортране, например, эти функции называются соответственно UNPACK и PACKLIST (т. е. РАСПАКОВАТЬ и ЗАПАКО- ВАТЬ-СПИСОК).- Прим. перев.)
- Такой способ реализации одновременного присваивания неэффективен, потому что операции EXPLODE и IMPLODE выполняются слишком часто. Очевидно, было бы быстрее пользоваться менее изящным синтаксисом, когда атом >XYZ представляется как список (>XYZ). Тогда вместо
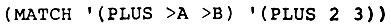
мы писали бы
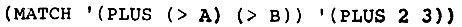
- Лучшая из этих альтернатив может быть реализована в наиболее развитых системах Лиспа, в которых допускается декларация специальных свойств символов при пересылке их из файла или терминала в активную центральную память. Тогда можно дело организовать так, что атомы, начинающиеся c >, превращаются в двухэлементные списки, всегда начинающиеся с >. Пользователь видит лишь приятный синтаксис, но внутри системы Лисп используется синтаксис неуклюжий, но эффективный.
Переменные со звездочкой обрабатываются в том же духе, на этот раз путем присваивания им значения в виде списков атомов, которые сопоставимы с этими переменными, с использованием следующего:

Заметьте, что никакого присваивания и никакого применения SET не происходит до тех пор, пока не будет проведена вся рекурсия и не будет заведомо известно, что сопоставление удалось. Затем, по мере того как Т возвращается с более и более высоких уровней, выполняются функции SET и продолжает строиться соответствующий список. Этот процесс начинается с выражения
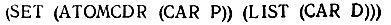
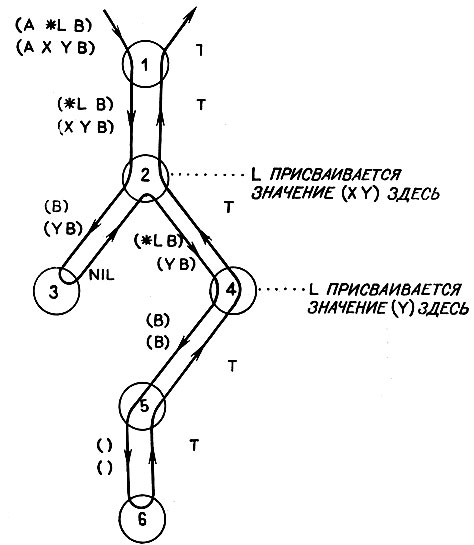
Рис. 14.4. Переменные, которым предшествует *, могут быть подставлены вместо произвольного числа фактов. Успешное сопоставление с образцом ведет к установке значения переменной со * равным соответствующим элементам факта
Этим начинается построение списка, когда * окончательно сопоставляется с последним атомом и в рекурсии больше не участвует.
Затем, по мере развития процесса на уровнях, где * была сохранена для сопоставления с атомами, расположенными дальше в списке, мы находим выражение (SET
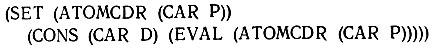
Функция EVAL получает список атомов, просмотренных к настоящему моменту, используя (ATOMCDR (CAR Р)), функция CONS добавляет атом, успешно сопоставленный на текущем уровне, а функция SET делает этот расширенный список новым значением переменной, отмеченной И так продолжается до тех пор, пока все атомы в списке не будут сопоставлены.
Посмотрите внимательно на следующий пример.
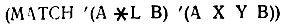
Рис. 14.4 показывает, что *L должна быть сопоставима с X и Y, при этом L присваивается значение (X Y).
Ограничения на то, чему может быть сопоставлена переменная образца
Другое усовершенствование может быть сделано, если мы не хотим указывать на конкретный атом в определенном положении или допустить какой-либо атом вообще. Вместо этого нам нужен член некоторого класса атомов, например чисел или атомов определенной длины или атомов со специальным свойством в списке свойств. С этой целью мы введем свойство ограничения. Чтобы им воспользоваться, необходимо подставить некоторый описательный список в образец, где прежде ожидались только атомы. Этот список имеет следующую форму:

Идея состоит в том, что соответствующая позиция в действительности должна быть занята атомом, который удовлетворяет всем предикатам, перечисленным в этом ограничении. Так мы могли бы определить предикат, который имеет значение Т только для атомов из четырех букв 4LETTERP:
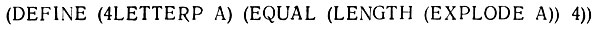
Такой предикат в дальнейшем мог бы быть использован в пакете ограничений, ограничивая класс приемлемых атомов в соответствующих позициях фактов атомами из четырех букв. Этот пакет ограничений мог бы иметь следующий вид:
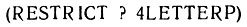
Он мог бы быть использован, как в следующем примере, в котором мы вместо ? употребляем переменную >V, позволяющую посмотреть на то, чему этот пакет соответствует.

V теперь имеет значение БЛОК.
Ограничения для ? могут быть реализованы следующим образом:

После того как проделаны соответствующие тесты по проверке пакета ограничений, атом из факта подается на предикаты в ограничении посредством функции MAPCAR. Затем AND проверяет, все ли предикаты возвращают значения Т, и если так, то весь тест в функции COND успешен, и на этом элементе осуществляется рекурсия. Конечно, подобное свойство может быть добавлено и для переменных со звездочкой.
Ниже идет определение для функции MATCH, которое включает все, кроме ограниченных * переменных, опущенных лишь потому, чтобы сделать программу более компактной:

В системах сопоставления с образцом, кстати, могут потребоваться и другие вещи. Например, часто требуется также извлечь значения из переменных образца. Это иллюстрируется последующим случаем, в котором используется синтаксис с <, чтобы указать, что элемент факта должен соответствовать значениям элемента данных, а не самому элементу данных. >
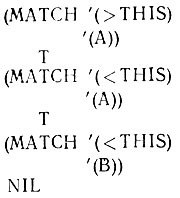
С этой добавкой символы > и < образуют мнемонику. Первый обозначает "вталкивание" значения в переменную после проведения сопоставления, а другой - извлечение значения перед проведением сопоставления.
В последующих главах свойства, связанные с > и <, потребуются, тогда как свойство, связанное со * ,- нет.
Многие проблемы сопоставления остаются нерешенными
Описанная система сопоставления является простой, потому что она ориентирована на сопоставление одного списка атомов с другим. Более того, не существует представления о степени близости: либо сопоставление успешно, либо нет. Работа с сетями, фреймами или другими большими объемами знаний может оказаться намного более трудным делом, потому что возникают следующие возможности:
- Система сопоставления должна работать с более прризвольными структурами. Имеется определенное разнообразие в вопросе о том, как могут соответствовать различные части.
- Система сопоставления должна выдавать некоторый показатель по шкале, простирающейся от полного отсутствия совпадения, среднего или хорошего совпадения до абсолютного. Может быть, нужно иметь некоторое суммарное описание характера соответствия.
Включение этих возможностей может оказаться чрезвычайно трудной задачей. Литература здесь мало что говорит.
|
ПОИСК:
|
При использовании материалов сайта активная ссылка обязательна:
http://informaticslib.ru/ 'Библиотека по информатике'