Вперед и выше
До сих пор мы занимались наименьшими звуковыми элементами английского разговорного языка - фонемами. Очевидно, однако, что из-за физических различий и эмоциональной окраски, которую придает речи говорящий, речь нельзя описать полностью одними лишь фонемами. Звучание каждой фонемы существенно зависит также от окружающих ее фонем. Когда мы начинаем группировать фонемы, создавая осмысленные фразы, мы произносим слова. Лингвистически состав слова можно анализировать в морфемах, морфах и алломорфах. Определение этих единиц речи довольно сложно; оно зависит не только от звуков, из которых состоит слово, но и от смыслового значения слова. Поскольку изучение смысловых значений слова и соответствующих разделов грамматики не входит в круг наших интересов, связанных с созданием синтезированной речи, мы просто примем к сведению, что эти элементы присутствуют в произносимых словах. Читатель, желающий глубже познакомиться с этими вопросами, может обратиться к списку литературы, приведенному в конце книги.
После того как фонемы выстроены в ряд, образуя более длинные и имеющие смысл последовательности звуков (называемые словами) можно выявить некоторые количественные характеристики этих последовательностей. Хотя, как уже отмечалось выше, правильное произнесение каждой фонемы в большой степени зависит от ее положения в слове, некоторые звуковые особенности фонем остаются неизменными, если рассматривать речь среднего человека. Эти особенности можно использовать при проектировании компьютерной речи и ее сравнении с "идеальной" человеческой речью.
Возьмем, к примеру, частоту употребления наиболее распространенных слов в разговорном английском языке. Имея перечень таких слов, необходимо позаботиться, чтобы синтезатор речи по крайней мере эти слова произносил точно, ибо они встречаются чаще других. Такой список, составленный много лет назад Годфри Дьюи из Гарвардского университета, приведен в табл. 3.1. Слова расположены здесь в порядке уменьшения частоты их появления, так что слова, употребляемые чаще всего, находятся вверху списка. При этом для каждого слова указана (в процентах) относительная частота его употребления. Например, из этой таблицы видно, что слово the встречается чуть чаще 7 раз на каждые 100 слов. Следующее наиболее употребимое слово of встречается почти 4 раза на 100 слов и т. д. Приведенная таблица может найти разнообразные применения. Так, следует заставить синтезатор речи "поупражняться" в произнесении приведенных здесь слов, чтобы убедиться, что они произносятся правильно. Данная таблица незаменима также при составлении минимального словаря для системы синтеза речи (если предусматривается хранение такого словаря в памяти системы).
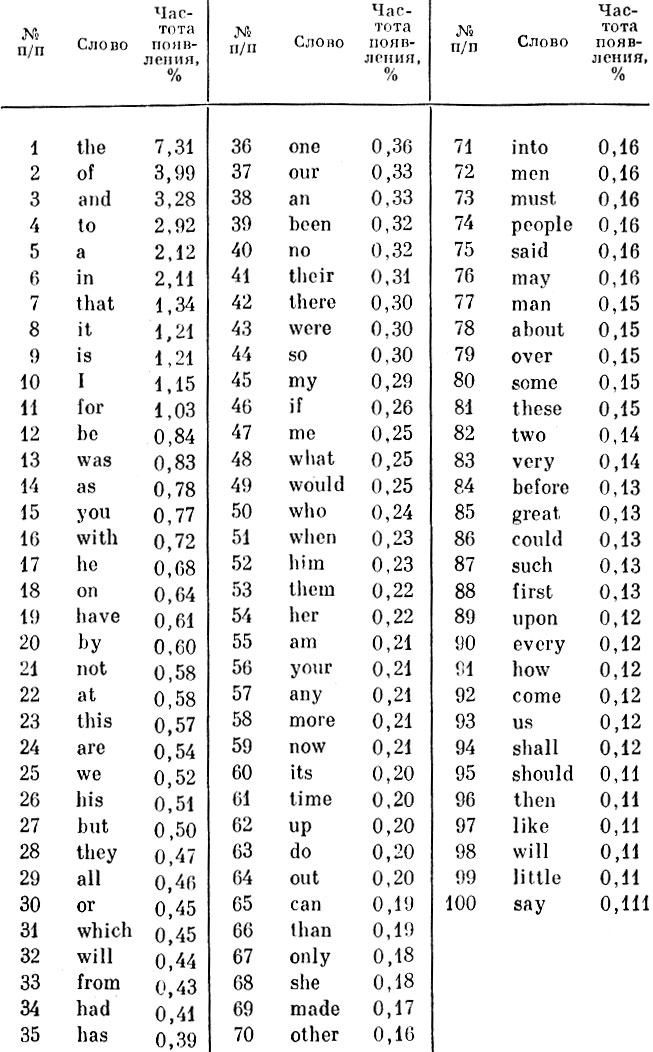
Таблица 3.1. Слова, наиболее часто встречающиеся в английской речи
Двигаясь дальше, мы можем также выявить звуки, наиболее часто встречающиеся в нашей речи (табл. 3.2). Эта таблица найдет себе применение не только при работе с системами фонетического синтеза, но и в тех случаях, когда требуется обеспечить правильное произношение звуков в любых системах синтеза речи. Каждый звук (фонема) в этой таблице дается с указанием относительной частоты его употребления; приводится также слово, характерное для произношения данного звука. Эта таблица дает нам информацию о наиболее употребимых фонемах. Руководствуясь ею, мы можем решить, какие звуки или фонемы следует опустить в упрощенной системе синтеза речи. Иными словами, если наша цель - создать элементарную фонетическую систему синтеза речи, то, вероятно, можно опустить такие звуки, как zh (azure) и дифтонг oi (boil), поскольку частота их употребления очень мала. Такие же фонемы, как i (tip), используемые наиболее часто, необходимо включить. При создании и анализе работы синтезатора речи полезна также информация об относительной фонетической мощности (или громкости), которая характеризует каждую фонему, произнесенную (средним) человеком.
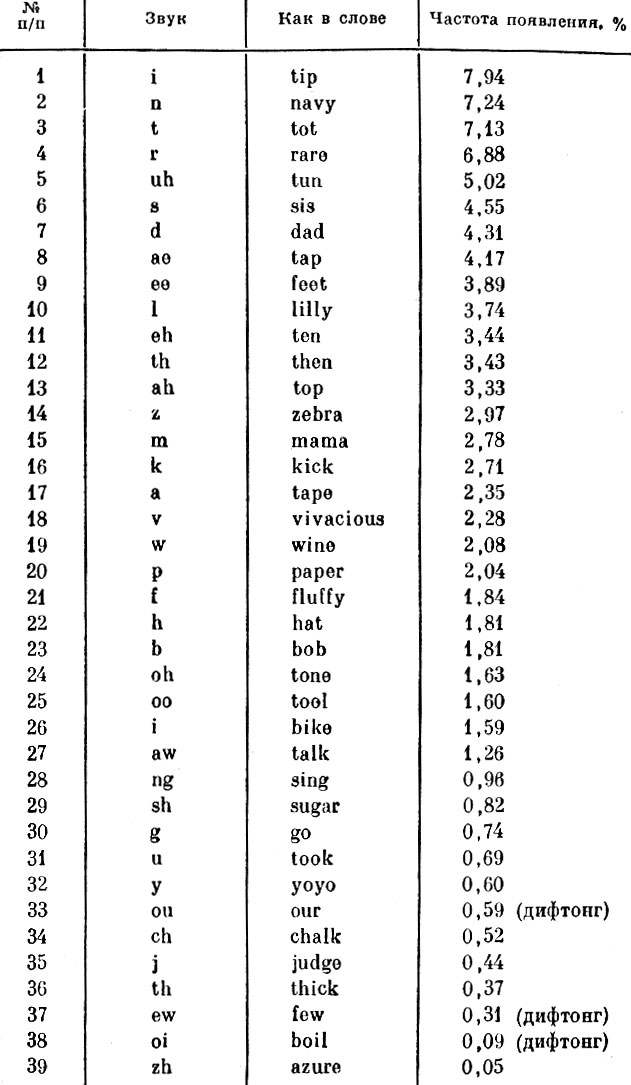
Таблица 3.2. Частота появления звуков речи
Из табл. 3.3 мы получаем представление об относительной мощности наиболее широко используемых фонем. Эта информация помогает нам приблизить речь компьютерного синтезатора к человеческой. В табл. 3.3 каждая фонема приводится с характерным словом и с указанием относительной громкости (по отношению к другим фонемам в таблице). У самой мощной фонемы aw (talk) громкость в 680 раз больше, чем у фонемы th (think). Если эту разность уровней выразить в децибелах (дБ), то она составит 28 дБ. Заметим, что по громкости первыми стоят гласные звуки, за ними идут промежуточные и носовые. Остальную часть таблицы занимают фонемы фрикативных согласных, которые произносятся более мягко. Конечно, значения громкости, приведенные в табл. 3.3, не учитывают слоговых ударений, которые могут увеличивать или уменьшать соотношения громкостей некоторых фонем. Приведенные здесь громкости соответствуют некоторой усредненной группе фонем, произносимых при спокойном разговоре.
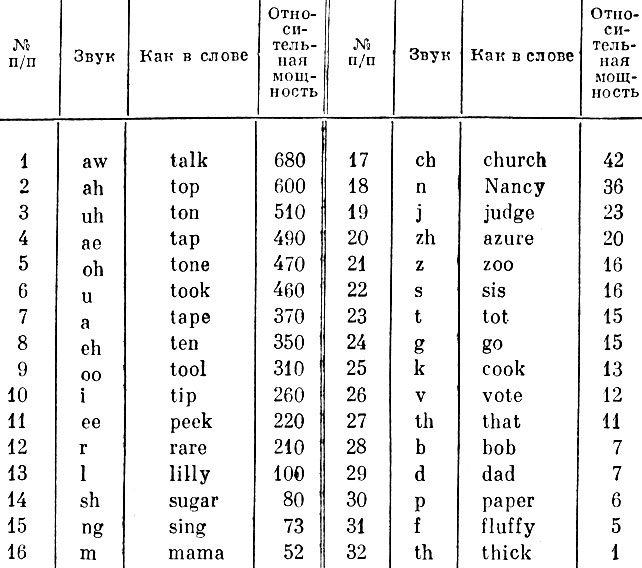
Таблица 3.3. Относительная мощность звуков речи
Эти три таблицы могут оказаться полезными при проведении испытаний и проверке систем синтеза речи. Разумеется, конечные результаты испытаний подобных устройств зависят от субъективной оценки слушателя. Ибо независимо от того, насколько искусственная речь с технической точки зрения соответствует естественной речи человека, оценку качества компьютерной речи дает все же человек. Наши же таблицы могут помочь приблизить параметры систем синтеза речи к количественным характеристикам обычного человеческого разговора. Если нужно оценить лингвистические способности системы синтеза речи, то следует подготовить серию контрольных слов, позволяющих проверить звучание фонем, используемых в речи. Чтобы лучше проверить качество речи синтезатора, можно пригласить какого-нибудь "свежего" человека, который ранее не слышал, как говорит система. Пусть тогда компьютер произнесет несколько слов из своего словаря, а вы оцените процент понимания слушателем каждого слова. Если беспристрастный слушатель неправильно воспринимает отдельные слова и группы слов, это, безусловно, говорит о недостаточном качестве воспроизведения синтезатором определенной фонемы или группы фонем. Следующий параграф поможет вам оценить имеющуюся в вашем распоряжении систему синтеза речи, если у вас только есть желание заниматься такой проверкой и имеется возможность программирования всего речевого словаря синтезатора.
Итак, предположим, что вам удалось создать устройство, которое говорит. Если вы намерены быть единственным слушателем своего детища, то, возможно, вполне удовлетворитесь имеющимися у него разговорными способностями. Но если вы хотите, чтобы речь вашей системы понимали и "неподготовленные" слушатели, то вам придется позаботиться, чтобы синтезатор имел правильное, общепринятое произношение. Ниже предлагается список слов, который можно использовать Для развития артикуляции синтезатора. Эти слова можно запрограммировать в память, чтобы синтезатор мог произносить их последовательно или в случайном порядке, давая возможность проверять правильность его произношения. Если неподготовленный слушатель сможет правильно опознать каждое из перечисленных слов, то это будет означать, что система имеет очень хорошее (точное) произношение. Неправильное понимание слушателем слов свидетельствует о наличии слабых мест в конкретной фонетической области и о необходимости внести изменения в программу или отрегулировать уровень громкости при генерации данного конкретного звука. Для каждой фонемы подобрана группа контрольных слов. Проверьте, сможете ли вы идентифицировать на слух каждую фонему, использованную в приведенных группах слов.
- Saw, Horse, Horn, Ball, Talk
- Yard. Clock, Top, Block, Star, Arm
- Gloves, Bug, Truck, Tub, Button, Ton
- Tap, Hat, Can, Black, Grass, Basket
- Tone, Boat, Coat, Snow, Stove, Comb
- Book, Cook, Foot, Look, Took
- Tape, Cake, Grapes, Table, Lady, Tail
- Ten, Bed, Dress, Bed, Steps, Feather, Sled
- Tool, Blue, Moon, Tooth, Shoe
- Tip, Chicken, Fish, Pillow, Pig
- Peek, Cheese, Meet, Sleep, Trees, Green, Feet
- Badio, Rake, Barrel, Car, Tire, Rabbit, Red
- Ladder, Lease, Leg, Letter, Ball, Bottle, Look
- Sheep, Shelf, Dish, Fish, Brush, Push, Shoulder, Shake
- Finger, Sing, Swinging, Ring, Tongue, Blanket
- Move, Music, Memory, Most, More, Meek, Mimic, Movie
- Chair, Cheese, Chicken, Watch, Catch, Matches, Teacher, Speach, Church
- Nasal, Know, Knife, Candle, Woman, Nancy, Spoon, Man
- Juice, Engine, Orange, Soldier, Bridge, Joke, Jump
- Glacier, Azure, Measure, Television
- Music, Zoo, Roses, Ears, Nose, Zebra, Scissors
- Seven, See, Saw, Sleep, Spoon, Basket, Glasses, Face
- Table, Tire, Butter, Tot, Letter, White
- Gloves, Grass, Gun, Golf, Digging, Wagon, Bug, Flag
- Crack, Pocket, Black, Clock, Cook, Fake
- Vase, Violet, Vivacious, Cover, Drive, River, Stove
- Thimble, Three, Thin, Thick, Mouth, Teeth
- Bed, Boat, Rabbit, Ribbon, Umbrella, Table, Bob
- Dog, Drink, Indian, Radio, Dud, Bed, Wood
- Paper, Pencil, Airplane, Apple, Pop, Cap, Rope, Sleep
- Feather, Finger, Fire, Fluffi, Elephant, Laugh, Roof, Knife
- These, Those, Brother, Then, Father, Feather, Loathe
Каждая из 32 основных фонем, представленных в списке, необходима для адекватного понимания речи, генерируемой синтезатором. Если у синтезатора обнаруживаются какие-либо дефекты в произношении одной или нескольких групп слов, то недостаток его речи можно характеризовать конкретными фонемами, содержащимися в неправильно произнесенных или неверно понимаемых группах слов. Сведения, изложенные в предыдущих параграфах данной главы, должны позволить вам идентифицировать каждую из специфических фонем в приведенном выше списке слов. Но не огорчайтесь, если у вас возникнут трудности с какой-либо группой слов,- ответы даны ниже:
Описанный тест пригоден для любого синтезатора речи и вообще для любого говорящего, если требуется проверить правильность произношения различных фонем или поупражняться с целью улучшения их произношения. Этот тест можно также использовать для сравнительных оценок качества речи.
|
ПОИСК:
|
При использовании материалов сайта активная ссылка обязательна:
http://informaticslib.ru/ 'Библиотека по информатике'