Аналоговый синтез формантных частот речи

Аналоговый синтез формантных частот речи
Описанный метод кодирования-восстановления речевого сигнала можно назвать "фотографированием" речи. В то же время синтез речи по методу аналоговых формант, или формантных частот, лучше характеризовать как живописное изображение того же речевого рисунка. Кодированный речевой сигнал должен существовать еще до того, как его произнес синтезатор, точно так же, как сами по себе существуют в природе пейзаж или предметы, которые мы хотим сфотографировать. В отличие от этого метод синтеза формантных частот представляет собой способ выражения той же речи искусственным путем, аналогично тому, как художник рисует наблюдаемую картину. Особенности каждого из этих двух методов синтеза речи в значительной мере совпадают с особенностями соответствующего изобразительного средства: фотография дает точное воспроизведение оригинала, тогда как живописное полотно, хотя и достаточно близко к оригиналу, никогда не совпадает с ним точно. Однако в зависимости от поставленной цели каждый из методов с известным приближением описывает исходную обстановку или речь.
Существует много методов реализации формантного синтеза речи. Но основные функциональные операции для генерации речи при разных способах формантного синтеза в принципе одинаковы. Все они основываются на детальном знании фонем и фонетическом расчленении речи (см. гл. 3). Познакомившись немного подробнее с количественными характеристиками фонетической речи, мы сможем заложить основы для понимания сущности формантного метода синтеза речи. Обратившись к описаниям спектрограмм речи, показанным на рис. 2.10 и 2.11 (гл. 2), вспомним, что темные частотные полосы визуализированной речи называются формантными частотами. Тот факт, что у нас имеется возможность визуальными и электронными способами распознавать в человеческой речи эти меняющиеся частоты, позволяет сформулировать метод синтеза искусственной речи, основанный на одновременной генерации необходимого числа формантных частот.
Если теперь посмотреть на табл. 6.2 и вспомнить приведенное в гл. 3 описание фонем гласных звуков, то мы обнаружим в этой таблице фонемы некоторых знакомых нам звуков, но здесь они охарактеризованы более подробно. Для каждого звука в таблице даны три основные форматные частоты, которые наблюдаются в спектрограммах соответствующих фонем, произносимых "средним" мужским голосом. Эти частоты, F1, F2 и F3, можно различать визуально на спектрограмме каждой произносимой гласной. Поскольку каждая из этих гласных является "статической", частоты остаются стабильными на протяжении всего времени их произнесения. Теперь, призвав на помощь немного воображения нетрудно представить электронную схему (рис. 6.13) с тремя параллельными полосовыми фильтрами (их средние частоты равны форматным частотам F1, F2, F3), которая возбуждается задающим генератором с выходным сигналом, аналогичным импульсу, формируемому в голосовой щели. Как ни проста эта схема, она может служить основой фонемного синтезатора гласных при условии, что формантные частоты F1, F2 и F3 регулируются в пределах, указанных в табл. 6.2.
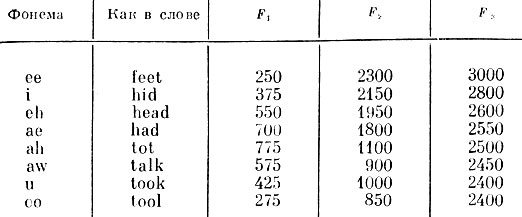
Таблица 6.2. Типичные формантные частоты для ряда фонем гласных звуков
Средняя частота каждого из параллельных полосовых фильтров регулируется таким образом, чтобы в процессе речи синтезатора достигалось совпадение с эквивалентными резонансами полостей рта и горла. Результирующая речь, получаемая суммированием выходов этих трех фильтров, весьма близка к речи человека. В спектрограмме выходного сигнала этой схемы содержатся три формантные частоты, идентичные формантным частотам в спектрограмме речи человека, произносящего те же гласные. Если в схеме на рис. 6.13 четыре ручки регулировки заменить компьютерным управлением высотой основного тона голоса и тремя формантными частотами, то можно программировать компьютер, который по нашим командам будет произносить требуемые гласные. То, что мы описали, и есть основа системы синтеза речи по методу формантных частот.
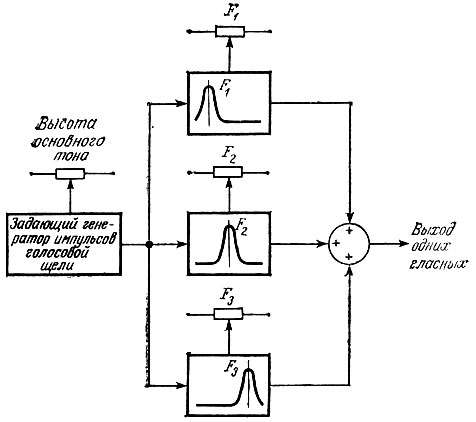
Рис. 6.13. Базовая схема формантного синтезатора речи
Единственная трудность в создании такого синтезатора формантных частот связана теперь с тем, что его речевые способности строго ограничены - он может генерировать только гласные звуки. Хотя построенная таким образом схема весьма интересна, поскольку наглядно демонстрирует метод электронной генерации фонетической речи, при работе с ней мы очень быстро исчерпаем весь запас слов и фраз, которые она способна произносить. Чтобы расширить диапазон возможностей формантного синтезатора, необходимо ввести источник фрикативных и взрывных согласных, а также аналог носовой резонансной полости, имитирующий носовые согласные. Блок-схема этого расширенного формантного синтезатора приведена на рис. 6.14.
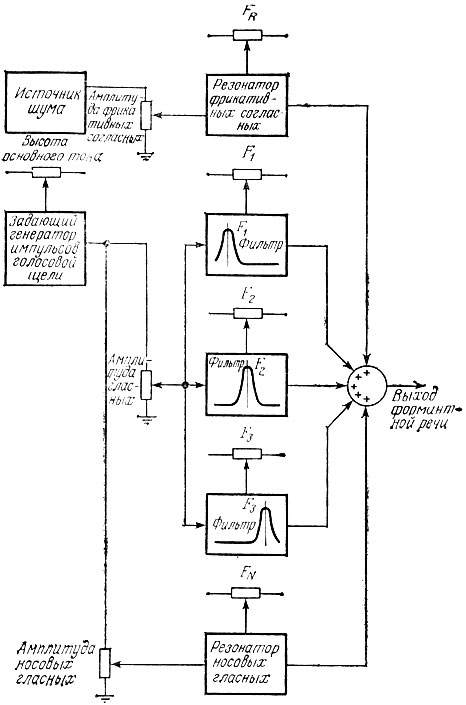
Рис. 6.14. Полная схема формантного синтезатора речи
Когда мы введем в новую схему синтезатора весь набор средств, необходимых для полного синтеза речи, она, конечно, усложнится по сравнению с предшествующей схемой, но не слишком сильно. Заметим, что вместо прежних четырех органов управления и регулировка теперь стало девять. Три из них служат для управления амплитудами фрикативных, гласных и носовых звуков, один - для регулирования высоты тона, а пять остальных - для регулирования частот различных резонансов. Если построить систему, которая имела бы пять ручек управления на передней панели, и если бы ваши руки обладали исключительной подвижностью, то посредством этой системы вы могли бы воспроизводить речь, подобно тому как это делали творцы первых "говорящих" машин. К счастью, мы располагаем таким преимуществом, как возможность компьютеризации управления органами регулировки, так что компьютер окажет нам неоценимую помощь в генерации синтезированной речи. Заменив каждый из девяти регулировочных потенциометров в схеме, изображенной на рис. 6.14, соединением с параллельным компьютерным портом, мы можем приступить к программированию синтезатора. Позже в процессе синтеза можно производить все необходимые регулировки со скоростью, которая требуется, чтобы добиться приемлемого приближения к нормальной речи человека.
Теперь предположим, что мы в состоянии надлежащим образом синтезировать изменения формантной частоты, необходимые для воспроизведения дифтонгов и "нестатических" фонем, путем перенастройки управления в полной схеме синтезатора с частотой 100 Гц; тогда, учитывая, что каждое управляющее слово состоит из 8-битового байта, мы можем управлять синтезатором при параллельной передаче управляющих слов со скоростью 900 байт/с. Но это еще не скорость выдачи используемых нами фонем, а всего лишь скорость передачи данных в самом синтезаторе, необходимая для текущих регулировок фильтра, высоты голосового тона и амплитуд при воспроизведении каждой отдельной фонемы. Данная информация, как правило, хранится в специальной управляющей таблице в памяти компьютера отдельно для каждой фонемы и ее вариаций - аллофонов. Она вызывается в виде последовательности, которая определяется входной последовательностью фонем в речевом выходе управляющей программы. Например, по каждой фонеме, которая вводится в компьютер, компьютерное управление синтезатора может потребовать до 30 полных перенастроек системы фильтров. Это означает следующее: чтобы компьютер выдавал схеме управления формантного синтезатора до 900 байт в секунду, в программу опроса справочной таблицы, которая управляет синтезатором, требуется вводить всего по 30 байт в секунду. Это соответствует тому, что выдача данных конечному пользователю производится со скоростью примерно 240 бит/с.
В то время как указанные выше значения скорости перенастройки фильтров могут меняться от системы к системе, зависимость между числом воспроизводимых фонем и размерами управляющей таблицы остается практически неизменной. Естественно, чем больше число обращений к справочной таблице по каждой фонеме, тем большей плавностью будет отличаться синтетическая речь и тем ближе она будет по звучанию к естественной артикуляции человеческой речи. Однако не следует надеяться, что речь подобной системы когда-нибудь будет звучать так, что ее не отличишь от человеческой. В ее синтезированной речи всегда прослушивается голос робота, что, согласно представлениям большинства людей, и должно быть характерно для компьютерной речи. Если вы захотите продемонстрировать подобную систему посторонним людям, то эффект будет весьма впечатляющим, но им, возможно, будет нелегко понять, что именно говорит система. Однако совершенно исключено, чтобы кто-нибудь мог принять синтезированную речь формантного синтезатора с фонемным возбуждением за предварительно наговоренную или восстановленную речь. Выход подобной системы всегда будет компьютерной речью.
Теперь посмотрим, как компьютер мог бы управлять типичным формантным синтезатором речи с фонемным возбуждением. Одна из возможных схем управления такой говорящей системы приведена на рис. 6.15. Слева на этой схеме изображен компьютер. Чтобы управлять такой системой, компьютер должен обладать следующими основными средствами:
- Набором 8-битовых выходных портов для реализации различных функций управления.
- Одним 8-битовым входным портом, служащим для уведомления компьютера о готовности синтезатора к приему следующего кадра данных для текущей перенастройки синтезатора.
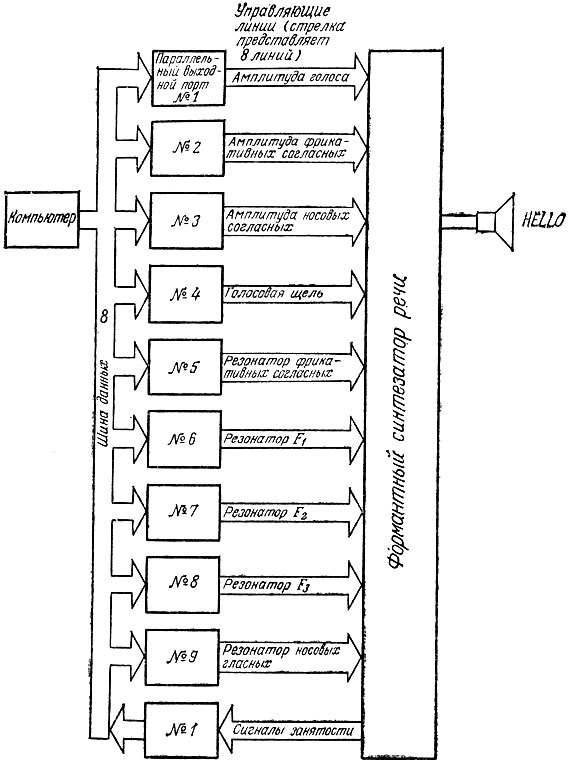
Рис. 6.15. Схема формантного синтезатора речи с компьютерным управлением
Если проследить ход различных управляющих линий, соединяющих на этой схеме различные блоки, то в них можно узнать те же средства управления формантным синтезатором, которые представлены на схеме рис. 6.14. Сигналы занятости, поступающие по управляющим линиям (показаны в нижней части рис. 6.15), сообщают компьютеру, что формантный синтезатор речи закончил произносить очередной кадр данных. Термин "кадр данных" выбран не случайно: он говорит о том, что управление синтезатором через отдельные порты производится не в произвольном порядке. Напротив, компьютер обновляет управляющие данные на всех девяти параллельных портах одновременно в соответствии с подлежащей воспроизведению фонемой или ее частью, затем ожидает окончания произнесения этого кадра (типичное время ожидания составляет 33 мс), после чего возобновляет цикл перенастройки управления для завершения произнесения фонемы.
На рис. 6.16 приведена функциональная блок-схема компьютерной программы для управления типичным формантным синтезатором. Если предположить, что синтезатор должен произнести слово hello, то программа в первую очередь должна расчленить вводимое слово на составляющие его фонемы. Ради простоты допустим, что в первом приближении для произнесения слова hello нужно воспроизвести всего четыре фонемы: h, eh, l и о. Если попытаться произнести это слово с помощью такой цепочки фонем, то оно будет звучать очень грубо и, вполне возможно, на слух окажется недостаточно понятным. Большинство фонемных синтезаторов располагает возможностью воспроизведения такого разнообразия фонем и их аллофонов для генерации речи, что для более точного произнесения слова hello могут использовать семь-восемь фонемных звуков.
Подойдя далее к той части блок-схемы программы, которая связана с процессом вывода речи, мы заметим, что компьютер обращается к управляющей таблице пс каждой фонеме, которую необходимо произнести. Если фонема является "статической", то фонемная управляющая таблица (имеющая ширину 9 байт и длину, равную 30 кадрам обновляющей информации) может содержать один и тот же обновляющий кадр, который повторяется 30 раз. Фонемам "нестатического" типа, или дифтонгам, будет соответствовать управляющая таблица, которая содержит набор меняющихся кадров обновляющейся информации, что связано с динамическими свойствами произносимого звука. Когда компьютер получает доступ к каждому из этих обновляющих кадров и выводит их на выходные порты, сопряженные с синтезатором речи, система начинает говорить. Когда же синтезатор речи завершает работу с очередным обновляющим кадром по произносимой фонеме, он сигнализирует компьютеру, что произнесение закончено, после чего компьютер обращается к следующей позиции управляющей таблицы, чтобы получить очередной обновляющий кадр для перенастройки синтезатора. Завершив воспроизведение очередной фонемы, компьютерная программа переходит к следующей фонеме произносимого слова и повторяет описанный цикл. Процесс продолжается до тех пор, пока не будут произнесены все фонемы расчлененного слова. После этого система оказывается готовой к приему следующего слова из произносимой фразы.
На этом, собственно, и можно закончить описание синтезатора, работающего по методу синтеза формантных частот. Довольно просто, не так ли? Или все же весьма сложно? Если при изучении блок-схемы программы вас поставит в тупик блок "Найти управляющую таблицу для выбранной фонемы", то не особенно огорчайтесь. Изготовители подобных систем формантного синтеза достаточно предусмотрительны и поставляют говорящие периферийные устройства, снабженные фонемными управляющими таблицами, которые являются резидентными средствами, т. е. размещены в постоянной памяти. В некоторых устройствах, например в формантном синтезаторе Тайп'н ток1, функция расчленения на фонемы даже включена в состав речевой системы. Сказанное означает, что для правильного произнесения слова достаточно просто ввести его в систему. Все логические операции, указанные на блок-схеме рис. 6.16, выполняются в самом периферийном устройстве для синтеза речи. Эта особенность характерна также и для ряда фонемных и аллофонных синтезаторов, построенных по принципу линейного предиктивного кодирования (ЛПК), которые описаны в следующем разделе. Потоки информации в фонетическом ЛПК-синтезаторе обычно имеют такой же вид, и его отличие от аналогового формантного синтезатора состоит лишь в том, что здесь используются не аналоговые, а цифровые управляемые речевые фильтры.
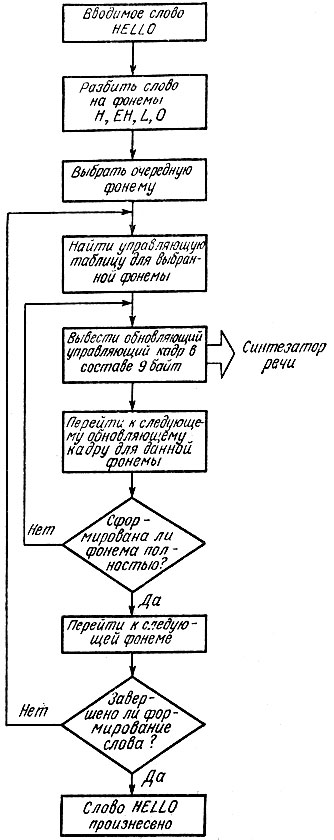
Рис. 6.16. Блок-схема программы для управления формантным синтезатором речи
1 ("Тайп'н ток" - торговая марка отделения "Вотракс" компании "Федерал скрю уоркс.")
Благодаря особенностям своей конструкции синтезаторы с фонемным и аллофонным возбуждением обладают способностью к воспроизведению неограниченного словаря. Поскольку синтезаторы этого типа произносят последовательности звуков, которые составляют естественную речь человека, все, что необходимо сделать, чтобы синтезатор воспроизвел слово,- это правильно составить цепочку из образующих слово фонем. Число фонем, используемых в фонемных синтезаторах, различно в разных конструкциях. Некоторые довольно грубые синтезаторы обходятся всего 32 фонемами, тогда как в других в распоряжение пользователей, синтезирующих слова, предоставляются сотни фонем и аллофонов. Совершенно очевидно, что, чем большее разнообразие звуков речи доступно пользователю, тем лучше будут звучать составленные из фонем слова и выражения. Однако увеличение набора фонем повышает требования к скорости передачи данных для воспроизведения речи и необходимому объему памяти. Это также приводит к увеличению нагрузки на компьютер, если он должен производить расчленение слов на отдельные фонемы.
В приведенном примере слово hello произносилось как последовательность четырех фонем. Для артикуляции дифтонгов и отражения динамических изменений речи в ходе произнесения подобного слова высококачественному аллофонному синтезатору может потребоваться от десяти до пятнадцати звуков речи. Задача нахождения четырех основных звуков слова hello может оказаться довольно простой, однако попробуйте найти 14-15 аллофонов, необходимых для воспроизведения этого слова в более сложных системах! Подобная задача почти неразрешима для более длинных слов. Для получения окончательно отработанной речи придется провести несколько часов за клавиатурой, действуя методом проб и ошибок.
И наконец, последнее замечание относительно формантных синтезаторов речи с фонемным возбуждением. При большем числе доступных пользователю звуков речи лучшего звучания окончательно отработанной речи можно добиться, лишь затратив достаточно много времени на правильную сборку слов из фонем и аллофонов. Если вас удовлетворяет звучание слова, составленного из меньшего числа фонем, то в таком случае вам, по существу, не нужны сотни вариаций фонем. Добавляя к слову, составленному из основных фонем, дополнительные звуки речи, вы лишь делаете речевой выход синтезатора более понятным все большему кругу нетренированных слушателей. Это не следует упускать из виду.
Конечно, если вы решите приобрести систему (речевого синтеза с фонемным возбуждением, наделенную способностью преобразовывать текст в речь, то вам придется столкнуться с другим ограничением: вы будете связаны словарем, который заложен в таблицу расчленения слов, встроенную в синтезатор. Естественно, можно воспроизводить слова, не входящие в эту таблицу, однако для этого придется самостоятельно заниматься фонетической композицией. Опыт показывает, что достаточно синтезатору, снабженному преобразователем текста в речь, произнести одно-два предложения, как система сталкивается со словом, которое она не способна правильно расчленить па фонемы,- тогда в синтезируемой речи появляются "марсианские" слова. Этот сбой даже нельзя отнести к недостаткам говорящей системы, ибо он скорее обусловлен чудовищной непоследовательностью правил, действующих в английской речи.
Метод аналогового синтеза формантных частот речи довольно специфичен. Если прослушать речь синтезаторов других типов и сравнить ее с речевым выходом синтезатора формантного типа, то их без труда можно различить. Звуки речи, генерируемые формантным синтезатором, отличаются значительной мягкостью и даже отдают некоторой слащавостью. Первые системы, в которых применялись аналоговые формантных фильтры, произносили слова так, как говорит человек с набитым ртом.
По мере совершенствования динамического изменения управляющих параметров речь формантных синтезаторов становилась более разборчивой. Этот метод синтеза речи весьма перспективен, и его использование, безусловно, будет продолжаться. Главное преимущество его - очень низшая скорость передачи данных, управляющих речевым выходом; подобная скорость характерна и для синтез" речи по методу ЛПК, о котором мы будем говорить в следующем разделе. Эти два метода синтеза речи обладают и другими сходными чертами. Знакомясь с методами синтеза речи на основе ЛПК и с тем, как цифровая фильтрация влияет на конечный речевой выход, не забывайте о схеме, представленной на рис. 6.14,- она позволит обнаружить удивительное сходство этих методов.
|
ПОИСК:
|
При использовании материалов сайта активная ссылка обязательна:
http://informaticslib.ru/ 'Библиотека по информатике'