Синтез речи по методу линейного предикатного кодирования (ЛПК)
Синтез речи по методу линейного предикатного кодирования (ЛПК)
Линейное предикативное кодирование речи - один из наиболее стремительно развивающихся методов синтеза речи. Вместе с тем этот метод наиболее труден для понимания. Причина состоит в том, что регенерация речи при его использовании выполняется математически с использованием уравнений преобразования закодированной речи в спектры ее исходных частот. Однако существует определенное и большое сходство между этим методом и методом кодирования-восстановления речевого сигнала. Так, было бы очень трудно построить ЛПК-речь, начав с нуля. Как правило, ренерация параметров для синтеза речи методом ЛПК производится человеком, который наговаривает нужные слова. Сходство здесь, по существу, так велико, что если мы подробно изучим механизм процесса кодрования и восстановления речи по методу ЛПК, то в скрытой форме обнаружим в нем весь процесс кодирования речевого сигнала.
На рис. 6.17. показана упрощенная схема генерации речи по методу ЛПК. Слева на рисунке изображен микрофон, после которого речевой сигнал, произнесенный человеком, пройдя через аналого-цифровой преобразователь, принимает вид выборок дискретизированной речи. В этой части системы речевой сигнал представлен непосредственно в цифровом коде, и его можно хранить в памяти, а затем восстанавливать так, как было описано в предшествующих разделах, рассказывающих о восстановлении речи из закодированного речевого сигнала. Однако если выборки речевого сигнала. Однако если выборки речевого сигнала направляются в компьютер, который производит цифровой анализ речи с целью определения ее спектрального состава, то мы уже не располагаем последовательностью цифровых байтов, непосредственно соответствующей исходному речевому сигналу. Результирующие выходные кадры данных, поступающие из системы анализа речи, дают нам такую информацию, как высота основного тона голоса, характеристики формальных частот, а также данные об амплитуде и интонации. Массив информации на выходе цифрового процессора речи, таким образом, весьма впечатляет своими размерами; однако, не располагая всеми этими сведениями, невозможно в конечном счете осуществить ЛПК-кодирование. Блок "Линейное предикативное декодирование", реализованный на базе компьютера для обработки речи, преобразует спектральный состав речи в ЛПК-параметры. Основной принцип, положенный в основу линейного предиктивного кодирования, сводится к тому, что поступающие выборки речевого сигнала могут рассматриваться как лмнейные комбинации прошлых выборок речевого сигнала. Таким образом, блок кодирования превращается в устройство краткосрочного прогнозирования, т. е. своеобразного "предсказателя" последующего речевого сигнала. Выход этого предсказателя управляет параметрами и определяет числовые коэффициенты, которые используются для линейной предиктивной генерации речи.
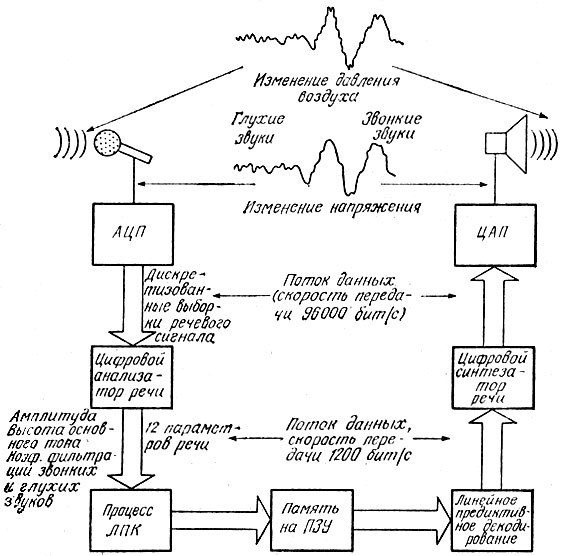
Рис. 6.17. Принцип линейного предиктивного кодирования
Параметры управления, формируемые в процессе линейного предиктивного кодирования, в обычном случае состоят из информации об амплитуде и высоте тона, которая сопровождается выдачей управляющего сигнала, указывающего, является ли звук звонким или глухим. Наиболее важными выходными данными в процессе ЛПК считаются коэффициенты для устройства прогнозирования - предикторные коэффициенты, которые в конечном счете используются в процессе восстановления речи цифровым фильтром. Число подобных коэффициентов меняется в зависимости от частоты дискретизации - частоты получения выборок и требуемого качества восстановленной речи. В современных коммерческих изделиях число предикторыых коэффициентов, как правило, равно 10-12.
Выходные данные с линейного предиктивного кодирующего устройства (кодера) имеют форму цифровой информации, которая содержится в постоянном запоминающем устройстве (ПЗУ) и служит для регенерации речи, формируемой системой ЛПК-синтеза. Далее в этом разделе мы рассмотрим типичный кадр ЛПК-данных и расскажем, какую роль играют различные коэффициенты. После того как ЛПК-параметры записаны в ПЗУ синтезатора, можно приступать к синтезу речи, используя процесс линейного предиктивного декодирования. Соответствующие операции выполняются в блоках, которые на рис. 6.17 расположены справа. Иногда все эти блоки изготавливаются в виде одной интегральной схемы, что позволяет получать речь, синтезированную ЛПК-методом, при минимальном объеме необходимых электронных схем. Структура интегральной схемы ЛПК-синтеза, выпускаемой фирмой "Тексас инструментс" (этой компании первой удалось построить схемы ЛПК-синтеза речи в виде микросхемы), показана на рис. 6.18.
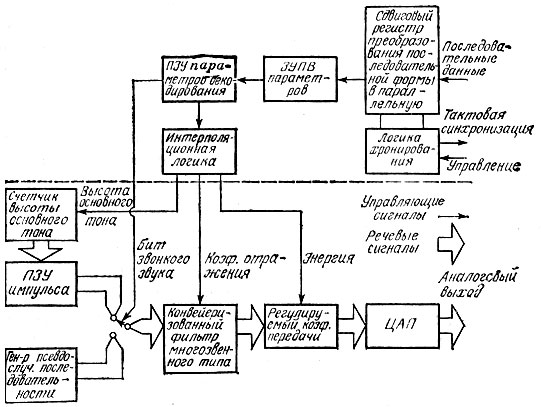
Рис. 6.18. Структурная схема ЛПК-синтезатора
Эта схема синтезатора, отражающая особенности внутреннего устройства системы ТМС-0281 (TMS 5100) фирмы "Тексас инструментс", показывает, как проходит информационный поток в полноструктурной системе восстановления искусственной речи по методу ЛПК. На рисунке логический поток данных следует из верхнего правого угла в левый, затем вниз (через штриховую линию), после чего поступает на выход (в правом нижнем углу схемы). Информация выводится в форме аналогового речевого сигнала. Часть схемы, изображенная выше штриховой линии, относится к системам цифровой обработки данных, которые приводят в действие механизм ЛПК-синтеза, Ниже штриховой линии представлены схемные компоненты, обеспечивающие прямой синтез речи с помощью расчетных ЛПК-коэффициентов.
Некоторые блоки на этой схеме не являются универсальными: здесь показан лишь один из возможных вариантов реализации ЛПК-синтеза, спроектированный в отделе говорящих изделий фирмы "Тексас инструментс". Однако блоки, приведенные в нижней части рис. 6.18,- действительно универсальные; они служат непременными компонентами практически всех речевых ЛПК-синтезаторов. Сказанное относится к генератору высоты основного тона (вспомните об импульсе голосовой щели), генератору псевдослучайного шума .ля получения фрикативных звуков и к системе цифровой фильтрации, служащей для модификации звонких и глухих звуков с целью их превращения в речь. Последний блок в системе ЛПК-генерации речи - это цифро-аналоговый преобразователь, который преобразует речь, записанную в форме единиц и нулей, в аналоговый сигнал, используемый для возбуждения громкоговорителя.
Как и у аналогового формантного синтезатора, возбуждение ЛПК-синтезатора производится периодически, причем частота поступления обновляющего управляющего кадра должна быть достаточно высокой, чтобы следить за динамикой изменения голосового тракта человека. В зависимости от изготовителя интегральной схемы и числа используемых предикторных коэффициентов (коэффициентов отражения) типичное значение частоты повторения кадров лежит в пределах 40-100 раз в секунду. Иными словами, в схемы ЛПК-синтеза каждые 10 или 25 мс вводится совершенно новый набор речевых данных, который используется для генерации речевого сигнала в остальную часть периода того же управляющего кадра. Исследовав более детально структуру кадра ЛПК-данных и то, как этот кадр связан со структурной схемой, изображенной на рис. 6.18, мы лучше почувствуем всю сложность такого процесса, как ЛПК-синтез. На рис. 6.19 дано наглядное описание ЛПК-данных, которые используются в ЛПК-методе, принятом фирмой "Тексас инструментс". В верхней части рисунка приведен кадр данных, относящийся к звонкому звуку. Каждая ячейка кадра представляет собой элемент информации, необходимой для формирования синтетического речевого выхода методом ЛПК. Первый элемент, "Энергия", служит для непрерывного управления амплитудой произносимой речи. Следующий элемент, "Повторить кадр", использует такое свойство речи, как медленное изменение характеристик голосового тракта при воспроизведении "статических" звуков. Если, например, во время произнесения какой-то фразы звук ah должен воспроизводиться в течение более длительного времени, чем продолжительность одного управляющего кадра, то используется бит (разряд) "Повторить кадр", который приказывает синтезатору повторить десять предыдущих коэффициентов фильтра (К1 - К10). Введение такого разряда повторения в кадр управляющих ЛПК-данных позволяет сократить почти на 80% число элементов в кадре для "статических" звуковых данных. Следующий элемент в ЛПК-кадре - управляющее слово "Высота основного тона", которое регулирует не только высоту тона (или период Р) синтезатора импульса голосовой щели, по и определяет, является ли воспроизводимый звук звонким или глухим. Если высота тона произносимой фразы равна нулю, то, согласно определению, это соответствует глухому звуку и тогда переключатель "звонкий - глухой" подключает к входу цифрового многозвенного фильтра источник псевдослучайного шума.
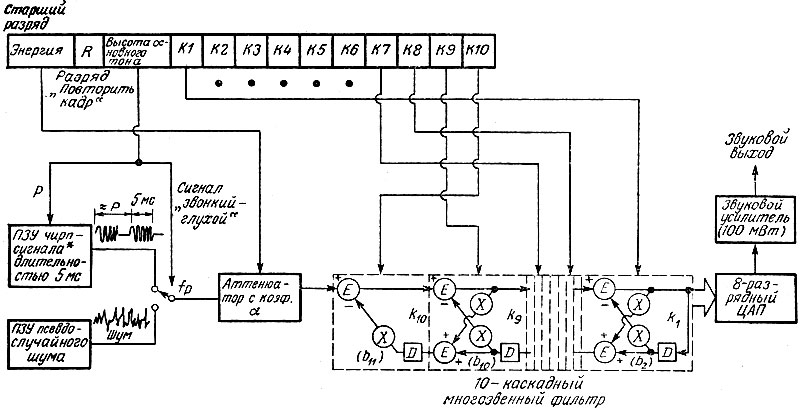
Рис. 6.19. Наглядное представление кадра управляющих ЛПК-данных фирмы 'Тексас инструментс'. (* Импульс с линейной частотной модуляцией, ЛЧМ.)
Десять последних элементов кадра ЛПК-данных соответствуют предикторным коэффициентам, которые используются в цифровом многозвенном фильтре для регенерации исходной речи. Каждый из этих 10 коэффициентов представляет собой численную величину, в соответствии с которой в многозвенном фильтре устанавливается коэффициент передачи в цепи специальной обратной связи. Для восстановления речи такое число коэффициентов используется не всегда (при воспроизведении глухих звуков оно меньше); это - максимальное количество коэффициентов для кадра управляющих ЛПК-данных в системе, разработанной фирмой "Тексас инструментс".
Различные типы кадров управляющих данных для ЛПК-синтезаторов речи проектируются с таким расчетом, чтобы сократить потребность в памяти и уменьшить предельную скорость передачи данных при синтезе речи. В синтезаторах, изготовляемых фирмой "Тексас инструментс", используются пять базовых форматов для кадров цифровой речевой информации (рис. 6.20). В синтезаторе TMS5100 максимальное число разрядов в полном управляющем кадре для звонкого звука равно 49. Кадр такого формата используется для формирования любого звука, который естественным образом воспроизводится вибрацией голосовых связок. Фрикативные и взрывные согласные генерируются с помощью управляющего кадра для глухих звуков; одновременно управляющее слово "Высота основного тона" устанавливается равным нулю. Обратите внимание на то, что число коэффициентов для фильтра снижается до четырех, поскольку шипящие звуки генерируются в части голосового тракта, расположенной выше, и, следовательно, в меньшей степени фильтруются в голосовом тракте. Длина управляющего кадра для глухих звуков равна 28 разрядам, что обеспечивает весьма эффективный речевой синтез, особенно если учесть, что таким путем генерируются высокочастотные звуки. Следующий формат кадра, приведенного на рис. 6.20,- формат "Повторить кадр". Как уже говорилось, такой кадр используется для повторения любого из предшествующих кадров при сохранении всех коэффициентов К1-К10 неизменными. Уменьшение длины управляющего кадра до 10 разрядов значительно повышает эффективность воспроизведения звуков "статического" типа. Два последних формата на рис. 6.20 - это форматы нулевой энергии и кода останова. Формат нулевой энергии есть не что иное, как "произносимое" молчание. При его воспроизведении выход синтезатора, по существу, выключается - с целью воспроизведения пауз в речи. Формат останова дает синтезатору команду прекратить говорить и вернуться в состояние готовности выполнять "следующие приказы управляющего компьютера. Хотя описанные кадры управляющих данных специфичны именно для систем синтеза речи, выпускаемых фирмой Тексас инструментс", им присущи характерные особенности и других систем, например ЛПК-синтезаторов, выпускаемых фирмами "Дженерал инструментс" и "Телесенсори", а также японских синтезаторов, работающих по принципу частотной корреляции (Паркор).
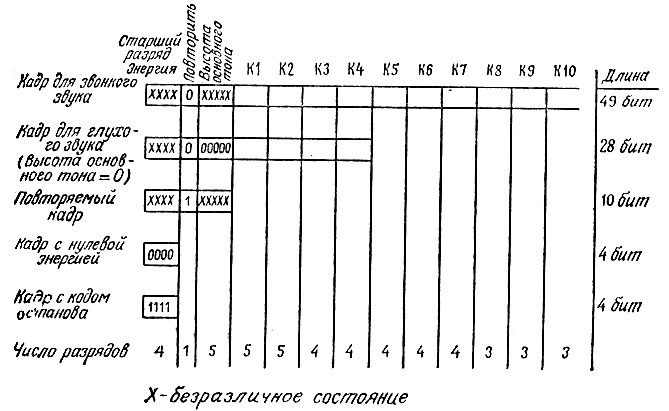
Рис. 6.20. Форматы ЛПК-данных, используемые фирмой 'Тексас инструментс'
Описание синтеза речи по методу линейного предиктивного кодирования мы вынуждены были дать на примере соответствующих аппаратных реализаций, хотя сам этот метод - чисто математический. Если бы мы попытались изложить процесс линейного предиктивного кодирования речи более строго, то 20-30 страниц этой книги нам пришлось бы заполнить одними уравнениями. Тем, кто желает ознакомиться с этими уравнениями, мы рекомендуем обратиться к книгам по ЛПК-синтезу речи, указанным в списке литературы.
Процесс, который происходит в ЛПК-синтезаторе при выводе речи, трудно смоделировать посредством любого из существующих персональных компьютеров. Во время синтеза речи каждый предикторный коэффициент, используемый в цифровом фильтре, обновляется с частотой подачи управляющих кадров примерно 50 кадров в секунду. При каждом очередном обновлении, или перенастройке, фильтра (производимом каждые 20 мс), схема ЛПК-синтезатора выполняет 4000 умножений 10-разрядных чисел на 14-разрядные и 4000 сложений 14-разрядных чисел. Попробуйте-ка повторить все это на персональном компьютере!
Системы, используемые для выполнения вычислений со столь огромной скоростью, представляют собой довольно сложные схемы реализации математических алгоритмов умножения и деления. Если же производить эквивалентные вычисления с помощью программы на Бейсике средствами персонального компьютера, то частота поступления кадров управления речью составит, вероятнее всего, не 50 кадр/с, а лишь 1 кадр в 5-10 мин. Следовательно, решающее значение для успешного практического синтеза по ЛПК-методу имеет его аппаратная реализация. Каждый изготовитель располагает своими собственными методами выполнения вычислений, связанных с ЛПК-синтезом, а также способами изготовления соответствующих интегральных микросхем. Независимо от того, как это в конечном счете достигается, в будущем метод ЛПК синтеза речи, несомненно, станет одним из самых распространенных. Говорящие изделия, построенные по этому методу, появились сравнительно недавно и быстро завоевывают успех у потребителей. Линейное предиктивное кодирование обеспечивает синтез речи, которая близка по качеству к естественной человеческой речи, при относительно низкой скорости передачи данных. Стоимость этих изделий также сравнительно невысока, что объясняется простотой их воплощения в виде интегральных схем. Все это позволяет создавать довольно дешевые синтезаторы.
Естественно, что здесь (как и в случае прямого кодирования-восстановления речевого сигнала) остается нерешенной одна весьма важная проблема. Необходимо иметь в виду, что речевой выход компьютера, работающего с такими системами, ограничен предварительно наговоренным словарем. Чтобы несколько дослать это ограничение, некоторые изобретательные изготовители ввели в синтезаторы фонетические и аллонические звуки, записанные в прямом ЛПК-коде. Это предоставляет пользователю неограниченный словарь, который он сам должен строить путем последовательного фонетического соединения ЛПК-звуков речи. По принципу использования эти системы весьма сходны с синтезаторами формантных частот с фонемным возбуждением, описанными в предыдущем разделе. Сочетание ЛПК-метода с фонемным синтезом дает исключительно мощную систему синтеза речи. Однако речь, генерируемая такой системой, произносится голосом робота, что обусловлено объединением отдельных фонем э цепочки. Вместе с тем качество такой речи не хуже, 1ем у любого синтезатора с фонемным возбуждением. Естественно, пользователь всегда должен идти на компромисс, выбирая между неограниченным словарем, который будет воспроизводиться голосом робота, и предоставляемым изготовителем ограниченным словам, который будет звучать, как естественная речь человека. Конечно, при наличии средств можно попро-1ть изготовителя ЛПК-схем закодировать в ЛПК-речь есть желательный для пользователя словарь. Так часто вступают крупные фирмы, которые затем выпускают миллионы изделий с синтезированной речью и одинаковым словарем, компенсируя таким образом затраты по кодированию заказного неограниченного словаря.
В ближайшем будущем устройства синтеза речи по методу ЛПК начнут в ограниченных количествах поступать в продажу. По мере повышения эффективности их производства стоимость изделий будет понижаться, что позволит энтузиастам-любителям генерировать собственный словарь, наговаривая слова своим голосом.
|
ПОИСК:
|
При использовании материалов сайта активная ссылка обязательна:
http://informaticslib.ru/ 'Библиотека по информатике'