Компьютер изучает основы семантики
Компьютер изучает основы семантики
Первые шаги в освоении понятийного ядра

Первые шаги в освоении понятийного ядра
Не так давно, в 1982 году, вышел из печати "Русский семантический словарь", составленный... компьютером. Авторы-то у словаря есть. Это даже целая группа под руководством члена-корреспондента АН СССР Ю. Караулова. Но они скорее авторы программы для ЭВМ. А составляла словарь и даже писала его все же машина. И добро бы это был обратный словарь, или частотный, или по длине слов, а то ведь семантический!
Немудрено, что вокруг словаря сразу разгорелись страсти. Одни считали, что это новое слово в семантике, первый шаг к постижению языкового значения компьютером, другие были шокированы и даже возмущены тем, что машине доверили такое тонкое и сложное дело, как обнаружение семантических сходств и различий между словами.
Многие посмеивались над компьютером - кто добродушно, кто злорадно - вот, мол, смотрите-ка, в одной группе оказались слова зерно и женщина. Ничего себе, семантическое сходство - в огороде бузина, а в Киеве дядька. Но других те же самые результаты восхищали: ай да компьютер - собрал в одну группу все злаковые, сюда же включил и овощи, да не все, а только с зернышками (огурец, помидор, тыква), про хлеб не забыл, глагол кормить тоже здесь оказался, и даже женщину вспомнил. А как же - она ведь кормилица! И снова споры, снова дискуссии.
Что ж, новое должно доказать свою жизнеспособность в борьбе мнений, должно пробить себе дорогу. А это было не просто новое, это было никогда раньше не виданное и не слыханное: компьютер делал первые шаги к постижению понятийного ядра значения. Пусть даже, как и положено на первых шагах, его вел за руку человек: компьютер, разумеется, значений слов не понимал, он сравнивал по разным словарям описания значений слов людьми - составителями словарей, а найдя сходство в описаниях, относил слова к одной группе, то есть считал слова сходными по значению.
Пока еще не все у компьютера получается гладко, не со всеми его решениями можно согласиться, но главное в том, что оказалось принципиально возможным обучить машину имитации понимания понятийного ядра - основы значения слова.
Скажем, в одну группу со словом бабочка компьютер отнес и слово хоккей. Что-либо общего в значениях этих слов трудно отыскать, не правда ли? Они оказались в одной группе на том основании, что в словарных описаниях и того и другого значений есть слово поле, а откуда машине знать, что хоккейное поле вовсе не тот лужок, над которым порхают мотыльки. Зато другие слова в соседи к бабочке компьютер подобрал с явным "пониманием" их значения: цветок, пыльца, пестик, крыло, птица и т. п.
Получается, что программа, по которой составлялся "Русский семантический словарь", является как бы автоматическим понятийным классификатором слов, распределяющим слова по группам в зависимости от сходств их понятийных ядер.
В целом машина неплохо освоила понятийную семантику почти десяти тысяч русских слов, распределив их по семантическим группам так, что непосвященному человеку и в голову не придет подозревать в этой явно интеллектуальной работе компьютер.
Вот, к примеру, такая группа: архитектура, архитектор, кремль, крепость, башня, пирамида, колокольня, дворец, здание, портал и т. п. Можно ли сомневаться в семантической общности этих слов? Конечно, нет. А ведь их подобрал компьютер, который действительно не понимает их значений. Просто трудно поверить, что машина не знает смысла слов, когда объединяет такую "театральную" лексику: спектакль, актер, балкон, кукла, отделение, премьера, самодеятельность, темп, афиша, кино, oпepa, постановка, программа, сцена, уборная, балет, кинотеатр, оркестр, представление, пьеса, театр, цирк.
Работа машины особенно поражает в тех случаях, когда семантика сформированных ею групп и человеку-то не всякому доступна. Например: альтруизм, самопожертвование, уступка, польза, делиться, ближайший, сосед.
Электронный языковед настолько правдоподобно имитировал понимание значений слов, что даже критиков словаря ввел в заблуждение. Ведь, подмечая семантические неточности в работе компьютера, они как бы спорили с ним на равных.
Разумеется, "Русский семантический словарь" - лишь первый приступ к машинному оперированию с самым важным, но и с самым сложным аспектом значения слова, с его понятийным ядром. Сейчас еще рано говорить о перспективах развития этого направления и конкретных приложениях его результатов, одно несомненно - принципиальная новизна направления приведет к принципиально новым решениям и результатам в этой важнейшей области обучения компьютера человеческому языку.
Работа эта чрезвычайно сложна, она только в популярном описании выглядит так просто. На самом деле предстоит еще долгий путь, пройдет еще немало времени, прежде чем компьютер сможет разнообразно оперировать понятийной семантикой, хотя человека он в этом не сможет ни заменить, ни даже повторить никогда.
А мы с вами вспомним, что понятийное ядро - только один (пусть и главный) аспект значения слова. И если компьютер добился успехов в постижении языковой семантики, опираясь даже на один этот аспект, то подключение к рассмотрению и других сторон семантики должно привести к еще более глубокому проникновению в сущность языкового значения. Поэтому перейдем к следующему семантическому аспекту - к качественно-признаковому ореолу слова.
Поиски, находки, потери
Тридцать лет назад группа американских исследователей под руководством Ч. Осгуда опубликовала сенсационную книгу под вызывающим заглавием "Измерение значения". Для языковедов само сочетание этих слов было бессмыслицей: каждому ясно, что значение слова, его смысл невозможно как-то там измерить - это ведь не отрез на платье. И добро бы еще Ч. Осгуд выражался метафорически, просто для большей завлекательности употребил бы слово "измерение" в каком-нибудь переносном смысле. Тогда можно было бы упрекнуть его в стремлении к саморекламе, да и все тут. Так ведь нет - в книге рассказывалось именно об измерении значений слов буквально с помощью линеек, с помощью числа и даже (!) с помощью еще таинственных тогда ЭВМ! Это было непостижимо для солидных языковедов, которые в глубине души были уверены, что научно-техническая революция с ее числами и машинами касается физики, химии и других "прикладных" наук, что она не затронет их любимых членов предложения и уж, конечно, никогда не посмеет коснуться святая святых языка, его семантики.
Книга, понятно, была поначалу встречена в штыки и в Америке, и в других странах. Объявлялось, что Ч. Осгуд вообще ничего не измерил, а если измерил, то совсем не так, как надо бы, а если и так, то совсем не то, что следовало бы измерять. Появилась даже расхожая шутка: мол, Ч. Осгуд хотел открыть неведомую Америку, а приплыл в хорошо известную Индию. А чтобы уж не совсем обижать энтузиастов, к этой шутке снисходительно добавлялось, что опыт незадачливых мореплавателей все же, мол, оказался полезным. Правда, осталось непонятным, в каком смысле этот опыт признавался полезным: то ли в том, что группа Ч. Осгуда все же получила какие-то результаты, то ли в том, что убедилась в невозможности выполнить поставленную задачу.
Теперь, по прошествии времени, видно, сколь несправедлива была критика. И еще видно, как трудно, как невозможно трудно новой идее пробить стереотипы мышления. Ведь Ч. Осгуд действительно открыл для языкознания новые земли.
Прежде всего он доказал, что в области семантики возможны измерения. И не только доказал, но и показал, как их можно выполнить. Это принципиально важно вообще для науки, а сегодня особенно важно, потому что возможность семантических измерений открывает дорогу к семантике для компьютера. И как оказалось - дорогу к самым тонким и неуловимым аспектам значения, к которым пока никакими другими путями компьютеру прийти невозможно.
А кроме того, если уж проводить сравнение с Колумбом, то "экипаж" Ч. Осгуда скорее повторил открытие и заблуждение первооткрывателя Америки. Ч. Осгуд считал, что измеряет значение слова, тогда как на самом деле он открыл и измерил новый аспект семантики. Те, кто критиковал Ч. Осгуда, ставили ему в упрек то, что он не измерил значения, имея в виду понятийное ядро. Да, это так - понятийное ядро с помощью методики Осгуда не измеряется. Измеряется другое - качественный аспект, качественный ореол значения. Но кто знал тогда, что значение слова - не монолит, что оно само по себе сложное, многоаспектное явление?! Кто четко представлял себе, что у слова имеется понятийное ядро и семантические ореолы?! Это теперь ясно, что Ч. Осгуд впервые выделил и измерил качественно-признаковый аспект значения слова.
Как же удалось группе Осгуда сделать то, что казалось явно невозможным? Представьте себе, в принципе достаточно просто. Свой "измерительный инструмент" Ч. Осгуд назвал весьма внушительно - "семантический дифференциал", видимо, стараясь весомостью терминов как-то затушевать предельную простоту, можно даже сказать, примитивность самого этого инструмента. По сути дела, это просто линейка, а посолиднев говоря, шкала, которая у Ч. Осгуда еще выглядела довольно замысловато, а теперь, после многих лет "обкатки", оказалась и совсем простой: очень хорошее - 1, хорошее - 2, никакое - 3, плохое - 4, очень плохое - 5. Вот и все. Трудно поверить, но действительно все.
А дальше - измерения с помощью этого "инструмента". Этап трудоемок, но тоже в общем-то прост. Измерительная шкала дается носителям языка. Это те, кто говорит на данном языке и для кого язык является родным. Их называют информантами, потому что они дают исследователю нужную информацию. Так вот, информантам дается шкала и предъявляются слова (в произношении и написании или только в написании). Предъявляются как угодно: просто диктуются и записываются на доске или с помощью каких-либо технических средств - неважно. Задача информантов несложна - нужно поставить очередному слову "оценку", то есть цифру по данной шкале. Например, предъявлено слово дом. Если информант почему-либо считает, что это "что-то очень хорошее", он поставит слову оценку 1, если, по его мнению, это "нечто очень плохое" - оценку 5 и так далее. Если возникают затруднения с оценкой, или слово для информанта не обозначает ничего - ни хорошего, ни плохого, или информант вообще почему-либо не желает оценивать слово, он всегда может поставить тройку ("никакое").
Оценки, понятно, индивидуальные. Один информант ответил так, другой может ответить иначе. Поэтому на мнение одного носителя языка опираться нельзя. Нужно опросить побольше информантов. Существуют различные способы определения надежности такого измерения, которые показывают, что нужно получить ответы не менее чем 50-60 человек, чтобы выявить "усредненное", коллективное мнение об оценке данного слова. При этом в группу должны входить самые разные носители языка - разного пола, возраста, уровня образования, разных профессий. По их ответам вычисляется средняя арифметическая, которая и является средней оценкой, отражающей коллективное суждение носителей языка о том, насколько "хорош" или "плох" дом.
Средняя оценка для слова дом по шкале "хорошее - плохое" получилась 2,2. Значит, в общем дом - "нечто хорошее".
Все же вас, читатель, наверное, одолевают сомнения. Ведь не только информанты все разные, но и дома-то всякие бывают: красивое, добротное здание - это, понятно, хороший дом, а какая-нибудь покосившаяся развалюха - что же в ней хорошего? Да и вообще слово дом может не обозначать никаких зданий. Скажем, отчий дом - это может быть и родная деревня, и город, и целая страна. Что же тогда оценивается?
В том-то и дело, что измеряется не конкретный предмет и не конкретное понятийное ядро определенного узкого значения слова, измерением как раз и улавливается некий общий оценочный ореол вокруг обобщенного понятия или представления, связанного в сознании "коллективного носителя русского языка" со словом дом.
Допустим, что каждый информант имел в виду какой-то свой дом, и оценки были самые разные - примерно одинаковое количество единиц, двоек, троек, четверок и пятерок. Тогда средняя арифметическая была бы приблизительно 3,0. Это означало бы, что никакой единой оценки этого обобщенного понятия не существует, и измерительная шкала не работает, оказывается бесполезной. В таком случае пришлось бы распроститься и с идеей измерить качественные ореолы слов, и с надеждой обучить компьютер оперированию этими ореолами.
Но при реальном измерении все оказалось иначе. Средняя оценка явно отклонилась от нейтрального деления шкалы в значимую (в данном случае в "хорошую") сторону. Так случилось потому, что информанты в подавляющем большинстве ставили слову дом оценки 1 и 2. Были и тройки и четверки, и даже пятерки, но эти "плохие" оценки просто потонули среди "хороших".
- Вот видите, - можете вы снова возразить, - ведь кто-то думает иначе, чем все, а оценка выводится усредненная. Зачем же всех стричь под одну гребенку?
Вообще-то можно было бы получить оценки какого-либо одного информанта, к примеру, некоего Иванова, и на их основании моделировать на компьютере языковое сознание именно Иванова. Другой компьютер моделировал бы Сидорова, третий - Петрова и т. д. Может быть, в каких-то случаях такой подход и имел бы смысл. Скажем, любопытно было бы получить индивидуальные оценки качественных ореолов слов какого-либо поэта или писателя, с тем чтобы в дальнейшем наблюдать за проявлением этих оценок в их произведениях. Наверняка можно разработать специальные методы тестирования, чтобы определять индивидуальные особенности языкового сознания, например, для профориентации, в психиатрии, да и везде, где требуется "моделировать" конкретную личность.
Но, обучая языковой семантике компьютер, нужно моделировать именно усредненное языковое сознание некоего коллективного, среднего, типичного, "говорящего по-русски". Так что для нас усреднение оценок не недостаток, а выгодное преимущество "семантического дифференциала".
И вот еще что возьмите в расчет. Хоть мы все и личности, и индивидуальности, но в языке особенно-то не посвоевольничаешь. Оказывается, наши языковые сознания в общем довольно единообразны. А как же иначе? Иначе мы бы просто не понимали друг друга. Это в моде все дозволено - женщины могут носить брюки, а мужчины навивать себе девичьи локоны. А попробуйте в своей речи заменить мужской род женским. Можно, конечно, но никто этого делать не будет, потому что его просто-напросто не поймут. И значение слова во всех его аспектах не может быть слишком индивидуальным в языковых сознаниях разных носителей языка - для взаимопонимания важны не различия, а сходства.
Вот и получается, что значения одних и тех же слов в сознании разных носителей одного языка при всех индивидуальных различиях должны быть в основном единообразными. И если слова постройка или строение на шкале "хорошее - плохое" расположены ближе к нейтральному делению (они "никакие"), то дом расположится ближе к отметке "хорошее", дворец будет еще лучше, а хибара, халупа или хижина расположатся на "плохой" стороне шкалы. И это "нормально", "типично" для говорящих по-русски.
Разумеется, можно намеренно придать этим словам противоположный ореольный смысл. Скажем, некто может назвать свою роскошную квартиру хибарой или развалюху дворцом. Но это будет игра на ореолах, это ореольные маски на словах. А если вы на новогоднем маскараде наденете маску волка, то ведь никому и отдаленно в голову не придет, что вы настоящий волк.
Бывают и "коллективные отклонения" от типичных средних оценок слов. Например, для моряков (а точнее, для "усредненного моряка") все "морские слова", связанные с берегом - причал, бухта, маяк, берег,- гораздо "лучше", чем для "сухопутных" носителей языка. Само собой разумеется, что и вся сугубо профессиональная лексика по-разному оценивается профессионалами и "непосвященными". Скажем, для тех же моряков слово лоцман обозначает "нечто хорошее", а для всех прочих русских оно нейтрально. Факт вполне объяснимый: моряк прекрасно знает, что лоцман - очень нужный, важный, а потому и "хороший" человек, опять же с берегом связан. И в любой профессии так - слова своей профессии известны точнее, понимаются глубже, полнее, чем всеми остальными.
Так что при желании можно смоделировать на компьютере ореольные языковые сознания моряков, астрономов, летчиков, механизаторов и т. д.
Но еще раз нужно подчеркнуть, что представители разных профессий специфически воспринимают лишь свои профессиональные слова, а всю общеязыковую лексику, которая составляет основу языка, они оценивают так же, как и все остальные.
До сих пор речь шла лишь об оценочной измерительной шкале, как будто качественный ореол состоит только из оценки. Несомненно, оценка составляет основу качественного ореола, но для его характеристики можно ис-нользовать и многие другие признаки. Ну что же, почему бы не построить по образцу оценочной любые другие признаковые шкалы? Например:
очень большое - 1 большое - 2 никакое - 3 маленькое - 4 очень маленькое - 5
очень подвижное - 1 подвижное - 2 никакое - 3 статичное - 4 очень статичное - 5
очень женственное - 1 женственное - 2 никакое - 3 мужественное - 4 очень мужественное - 5
Тогда дом будет не только "хорошим", но и "большим", "статичным" и т. д.
Но огонь - это "нечто горячее", вода - "нечто мокрое", да и каждое из имеющихся в языке качественных прилагательных обязательно описывает какие-либо признаки предметов, явлений, состояний. Как же быть? Строить шкалы из всех прилагательных и мерить по ним все остальные слова языка?
В принципе да. Это было бы самое полное, исчерпывающее описание качественно-признаковой ореольной семантики языка. Но такая работа - на много лет для нескольких крупных научно-исследовательских центров. А у Ч. Осгуда все же была небольшая группа исследователей, хотя ему активно помогали многие энтузиасты-студенты. Этот коллектив провел огромную работу - измерил несколько тысяч английских слов по 75 шкалам.
Затем весь этот гигантский материал был обработан на ЭВМ, и тут оказалось, что исследователи даже перестарались. Вот так всегда достается первопроходцам - сколько пустой породы приходится перелопатить, прежде чем откроются заветные алмазные трубки. Знать бы заранее, где они есть!
Так вот, оказалось... Впрочем, то, что оказалось, поначалу ошеломило и самих исследователей. Они отказывались верить в этот результат и все перепроверяли расчеты. Однако ошибки не было - выявилось всего три(!) основных шкалы, вокруг которых группировались все остальные. Неужели так просто, так примитивно устроено значение?
Ну, во-первых, как мы теперь знаем, с помощью шкалирования измеряется не все значение, а только один его аспект. А во-вторых, это только основных шкал-признаков три, а их оттенков великое множество. Ведь цветная палитра кино, фотографии и телевидения богата и разнообразна, тогда как все богатство цветов и оттенков создается комбинацией всего трех основных цветов.
Результаты осгудовских экспериментов многократно перепроверялись в разных странах и на разных языках, но (с небольшими вариациями) вывод всегда был один и тот же: существует три основных аспекта, три фактора в восприятии качественно-признакового ореола слов. И как ни обидно было филологам расставаться с мнением о невероятной сложности, непостижимости и тем более неизмеримости каких бы то ни было аспектов языкового значения, деваться некуда: факты - вещь упрямая.
Какие же это факторы, составляющие, по сути дела, основу нашего мировосприятия?

Поиски, находки, потери
Первый и главный из них - фактор оценки. Он объединяет шкалы-признаки "хорошее - плохое", "полезное - вредное", "безопасное - страшное", "светлое -темное", "радостное -- печальное", "красивое - безобразное" и т. д.
Второй - фактор силы. Сюда входят шкалы "сильное - слабое", "легкое - тяжелое", "большое - маленькое" и т. п.
Наконец, третий - фактор активности, объединяющий шкалы "подвижное - статичное", "быстрое - медленное", "активное - пассивное" и т. п.
Можно представить себе, как формировалась эта трехмерная структура восприятия у нашего предка - дочеловека. Ясно, что весь окружающий мир прежде всего делился для него на безопасное, полезное, съедобное - с одной стороны, и на страшное, бесполезное, несъедобное - с другой. Все, что способствовало его выживанию, было хорошим, все, что угрожало его существованию - плохим. В этой связи понятно, почему шкала "светлый - темный" входит в оценочный фактор: темное время суток было для предчеловека наиболее опасным. Так что если бы нашим предком был филин, то, вероятно, дело обстояло бы иначе - хорошим считалось бы темное. Оценка - самый главный, жизненно важный аспект восприятия, который долгое время был единственным.
С этим аспектом тесно был связан и второй фактор - силы. Было важно - некто сильнее меня или слабее. Если сильнее, то этот некто может угрожать моему благополучию, если слабее - бояться его нечего. Следы единства и последующего разделения факторов прослеживаются довольно явственно и сейчас во всех языках и особенно при сравнении языков, стоящих на разных ступенях развития. В "первобытных" языках, как правило, есть слова, обозначающие одновременно и "хорошее" и "сильное". Такие следы есть и в русском языке. Мы можем сказать слабый фильм, и это будет означать "плохой". А вместо "хорошее" в разговоре можно услышать: "Ух, сила!"
В фактор силы входит и шкала "большое - маленькое". Интересно, что она довольно долгое время была связана с оценкой, в частности со шкалой "красивое - безобразное". Вспомните, как в сказке П. Ершова "Конек-горбунок" Царь-девица разочаровала Ивана:
Хм! Так вот та Царь-девица! Как же в сказках говорится,- Рассуждает стремянной,- Что куда красна собой Царь-девица, так что диво! Эта вовсе не красива: И бледна-то, и тонка, Чай, в обхват-то три вершка; А ножонка-то, ножонка! Тьфу ты! словно у цыпленка! Пусть полюбится кому, Я и даром не возьму.
Но, поварившись в котлах и поднявшись на новую ступень, Иван меняет эстетические взгляды и охотно женится на "тоненькой" царице.
Теперь в развитых языках факторы обособились, и мы знаем, что сильное и большое - это вовсе не обязательно хорошее, а, может быть, даже и наоборот. Вот фашизм был силен, но это, вне всяких сомнений, нечто
крайне отвратительное. А ребенок слаб и мал, но очарователен.
Фактор активности также изначально был связан с оценкой, чему тоже есть объяснение: неподвижное менее опасно, чем движущееся. Интересно, что в русских сказках счастливая жизнь часто связывается с покоем, возможностью спать, валяться на теплой лежанке, как это делает Емеля, который вообще не слезает с печки, или Иван, попавший с Коньком-горбунком в царский дворец:
Ест он сладко, спит он столько, Что раздолье, да и только!
Понятно, что замученному постоянной тяжелой работой труженику пассивное времяпрепровождение, неограниченный отдых могли представляться только в сказке и были доступны, по его разумению, не меньше как царям. Недаром в "Коньке-горбунке" царь все "государственные" дела вершит в спальне, не слезая с кровати.

Поиски, находки, потери
Но в настоящее время фактор активности так отдалился от оценки, что начинается их "обратное" сближение, как при все большем и большем расхождении часовых стрелок: они наконец начинают сближаться "с другой стороны". Теперь уже активность сближается с положительной оценкой, и если мы говорим "активный человек", то это положительная оценка, а если "пассивный" - то отрицательная.
Такое "более цивилизованное" сближение факторов прекрасно обыгрывают в сказках П. Ершов и А. Пушкин. В "Коньке-горбунке" постоянное местопребывание царя в кровати звучит как издевательская насмешка над бездельником, явно выраженная Пушкиным в "Сказке о золотом петушке":
Царствуй, лежа на боку!
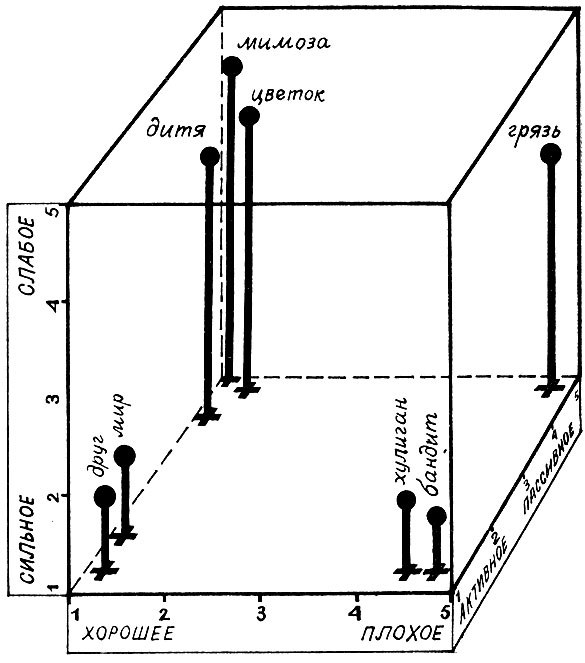
Итак, три фактора, три меры восприятия, три основных компонента качественного семантического ореола. Три меры - это куб. Шкалы могут быть изображены в виде линеек, и тогда три основных шкалы ("хорошее - плохое", "сильное - слабое", "подвижное - статичное") образуют трехмерное пространство, которое называют семантическим пространством, или семантическим кубом Осгуда, но точнее нужно бы сказать пространство качественно-ореолъной семантики.
А дальше легко догадаться: если по всем трем шкалам взять средние оценки какого-либо слова, то в семантическом кубе по трем координатам определяется его местоположение. Теперь, пожалуйста, измеряйте любое слово и располагайте его в ореолъном пространстве. Можете воочию наблюдать группировки слов, их взаимное расположение, можете буквально линейкой измерять расстояние между их качественными ореолами.
Если ореолы сходны, слова расположатся компактно, этаким ореольным облачком, если резко различны, они разбегутся в противоположные углы куба, и можно точно сказать, насколько велики ореольные сходства и различия.
Можно нарисовать пространство и расположить в нем слова, можно и модель сделать. Кто до Ч. Осгуда хотя бы отдаленно предполагал, что с неуловимыми и тонкими оттенками значений слов будут проделывать такие "материальные", зримые и ощутимые манипуляции? И если тридцать лет назад трудновато было решить, для чего нужно (и нужно ли) так необычно и странно измерять значение, то теперь-то мы это хорошо себе представляем: такое описание качественных ореолов слов легкодоступно и "понятно" компьютеру. Теперь ему очень просто объяснить, "что такое хорошо и что такое плохо", как сказал поэт. Теперь компьютер свободно разберется, что сильное, а что слабое, что быстрое, а что медленное, что горячее, а что холодное или, как сказал тот же поэт, "который москит и который мускат, кто персюки и персики".
Схема измерения качественных семантических ореолов, как видите, в принципе проста. Но только схема и только в принципе. Далеко не все так легко и просто, не все решено до конца, не все ясно.
Сначала о проблемах непринципиальных, но все же о проблемах.
Легко манипулировать со словами в ореольно-семантическом кубе, если слов два-три десятка. А если их десятки тысяч? Такого куба ни нарисовать, ни построить. Правда, группа Ч. Осгуда в какой-то мере справилась с этой задачей довольно остроумно. Был издан "Атлас семантических профилей" - книга, где страницы представляют как бы срезы куба с попавшими на эти срезы словами. Конечно, наглядность уже не та, но все же в таком атласе заключена большая и уникальная информация.
Поиски, находки, потери
Сложнее обстоит дело с самим кубом. Для его построения взяты три шкалы, а ведь измерение проводилось по десяткам признаков. И каждый фактор - это не одна шкала, а их пучок. Значит, ребра куба можно строить не из линеек, а из "веников", и тогда очертания куба размываются, теряют определенность. Причем прутья-шкалы веников расходятся очень значительно: веник не связан плотно, а основательно растрепан. Например, шкала "активный - пассивный" входит в фактор активности, но она так отклоняется от шкалы "быстрый - медленный" в сторону фактора оценки, что занимает, по сути дела, промежуточное положение между этими двумя факторами. Как же тогда рисовать пространство? Куб начинает вибрировать, менять очертания, деформироваться, расплываться.
Но это бы еще не беда: не столь важно, форму какого геометрического тела примет семантическое пространство. Хуже, что точки слов тоже начинают "плавать" в меняющемся пространстве и из точек превращаются в размытые "облака", которые пересекаются и смешиваются.
Размыванию точек способствует еще одно важное обстоятельство. Вычисленные, казалось бы, точно координаты слов в пространстве на самом деле точны лишь относительно, поскольку вычисление средних оценок носит не абсолютный, а вероятностный характер. Скажем, мы опросили группу в 50 информантов и вычислили по их ответам средние оценки слов. Будут ли эти оценки точно такими же, если мы те же слова предложим другой группе в 50 человек? Вовсе не обязательно. Отдельные средние оценки могут совпадать, но в большинстве полученные числа будут близки к прежним, однако будут от них более или менее отличаться. Другими словами, средние оценки могут колебаться от эксперимента к эксперименту в каких-то пределах. Значит, в пространстве это опять-таки не точки, а "облачка".
Вот и получается, что в результате и куб не куб, и точки не точки, а некая бесформенная емкость, наполненная космами тумана или клубами дыма.
Но даже и это еще не все соображения, разрушающие осгудовский "семантический куб". Главное - впереди.
Работая с "семантическим дифференциалом" на материале русского языка, советские исследователи В. Петренко и Н. Павлюк независимо друг от друга обнаружили, что в нашем языке упрямо выделяется еще один фактор, еще одно измерение пространства, которого не было у Ч. Осгуда. Эта мера объединяет пучок таких шкал, как "женственное - мужественное", "нежное - грубое", "мягкое - твердое", "удобное - неудобное", "округлое - угловатое" и т. п. Фактор получил название родокомфортности и стало ясно, что качественно-признаковое пространство не обязательно трехмерно. Четвертая мера обнаружилась и в английском языке, только гораздо менее явно, поэтому-то Ч. Осгуд и не выделил ее.
Этот факт вполне объясним, если вспомнить, что в русском языке есть грамматическая категория рода, а в английском ее нет. То, что мы, русские, все предметы и явления грамматически делим на "мужчин" и "женщин", не могло не отразиться на наших признаковых оценках слов. Разумеется, мы не считаем, что дубовый стол - мужчина, а рябиновая трость - женщина. Но ведь поем: "Как бы мне, рябине, к дубу перебраться". В переводе на английский язык содержание этой песни покажется англичанину весьма странным: он не сможет взять в толк, с чего это одно дерево воспылало страстью к другому - ведь в английском и дуб и рябина одинаково "никакого" рода. Разумеется, в английском переводе можно объяснить, что дуб - это мужчина, а рябина - девушка, но эффект будет совсем не тот: логическое объяснение в художественном отношении ни в какое сравнение не идет с непосредственным воздействием самой ткани, самой плоти языка.
Наше "языковое поведение" все насквозь пронизано "родовой окраской". Мы говорим: "Нож упал - мужчина придет, упала ложка - женщина в гости спешит". В английском такая примета невозможна - ни нож, ни ложка рода не имеют. Мы можем обругать старым пнем только мужчину и никак не женщину, зато выдрой - только женщину, хотя звери-выдры есть и самцы.
Игрой на родокомфортном факторе в нашем языке выражаются тончайшие оттенки смысла, совершенно не переводимые на "безродовые" языки. Например, А. Вознесенский пишет:
Ты кричишь, что я твой изувер, и, от ненависти хорошея, изгибаешь, как дерзкая зверь, голубой позвоночник и шею.
Обратите внимание, каким удивительным способом открывается в этом четверостишии, что "ты" - это женщина: только формой прилагательного дерзкая, неправильно согласованной с существительным мужского рода зверь. Неправильное словосочетание кажется тем не менее естественным, поскольку существительные такой формы могут иметь и женский род (например, дверь). Но оригинальное соединение разнородовых форм создает необычный эффект, перевести который на язык без грамматической категории рода никак нельзя.

Поиски, находки, потери
Итак, пространство может быть и четырехмерным, а тогда геометрическая интерпретация отпадает и возможность вычисления расстояний между словами-точками становится проблематичной.
И еще одно, не менее убийственное для "семантического пространства" обстоятельство.
Оказывается, при измерении некоторых слов обнаруживается неожиданная картина - слово располагается не в одной точке шкалы, а сразу в двух противоположных точках. К примеру, слово регби по шкале "хорошее - плохое" получает среднюю оценку 2,9, то есть оценивается большинством информантов как бы "никаким". Но это вовсе не так. На самом деле примерно половина отвечающих единодушно считает, что регби - это что-то "хорошее" (видимо, им нравится эта игра), а другая половина столь же единодушно полагает, что это нечто "плохое" ("это не игра, а свалка какая-то"). Но почти никто, заметьте, не посчитал регби "никаким". Значит, средняя оценка фиктивна, за усреднением она скрывает разнонаправленные тенденции. И таких слов множество: бокс, хоккей, пушка, огонь, суд, холостяк, женщина - это только несколько примеров слов "двойной оценки".
А вот слово дождь расположилось буквально на всей шкале, что и понятно: если вас спросят: "Дождь - это что-то хорошее или плохое?" - вы наверняка скажете - смотря какой, смотря где, смотря когда. У этого слова нет постоянного качественного ореола, он меняется в зависимости от ореолов слов-соседей.
Вот теперь и прикиньте, как можно расположить слова с двойными или меняющимися ореолами в любом пространстве - хоть трех-, хоть четырехмерном? Трудно что-нибудь придумать. Во всяком случае, "облака" таких слов вытягиваются почти на все пространство, как Млечный Путь.
Автоматический качественный классификатор
Создается впечатление, что в рассказе об осгудовском измерении значения получилось, как в известном анекдоте:
- Правда ли, что Том выиграл в лотерею "понтиак"?
- Да, правда. Только не Том, а Тим. И не "понтиак", а "кадиллак". И не в лотерею, а в карты. И не выиграл, а проиграл.
Но все-таки это не совсем так. Качественный ореол значения слова Ч. Осгуд действительно измерил, только геометрическое представление результатов измерений оказалось не совсем удачным. Во всяком случае, для компьютера.
Поэтому Н. Павлюк, обнаружив четвертую меру семантического пространства и убедившись в невозможности его графической интерпретации, стал искать новые пути семантических измерений. И поиски привели его к разработке простого (а значит, вполне доступного "пониманию" компьютера) и в то же время весьма эффективного способа автоматического оперирования с качественно-признаковыми ореолами слов.
Есть такая настольная игра. На игровом поле установлены разные отражатели, стенки, барьерчики, ловушки. Один или несколько шариков выскакивают на поле и движутся по нему, отражаясь от препятствий, застревая в ловушках. В конце концов шарики собираются в разных частях поля, в зависимости от чего играющими начисляются очки. Придуманный Н. Павлюком автоматический классификатор похож на эту игру. Посмотрите на рисунок.
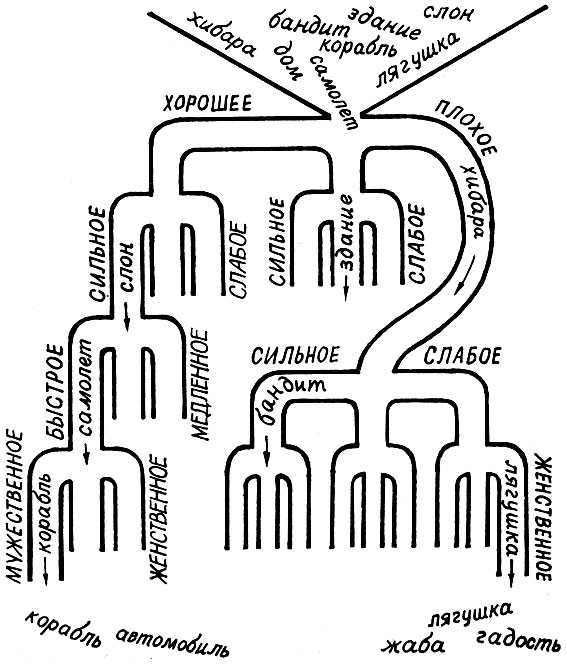
Автоматический качественный классификатор
Представьте себе, что в верхнюю воронку засыпаются слова, которые распределяются по трубам этого сортировочного устройства в зависимости от наличия тех или иных характеристик. Сначала они попадают на первый уровень, где "хорошие" слова направляются налево, "плохие" - направо, а "никакие" - прямо. Теперь каждая из трех групп попадает на второй уровень. Там снова происходит сортировка: "хорошие и сильные" - направо, "хорошие и слабые" - налево, "хорошие и никакие" - прямо. Поскольку каждая из трех групп первого уровня делится еще на три группы, то групп уже получается 9. Затем третий уровень, где каждая из 9 групп делится еще на 3 в зависимости от "активности" слов. Групп уже 27. Четвертый уровень делит слова по признакам "мужественное - женственное", и групп становится 81.
Если остановиться на этих четырех уровнях, то в "осгудовских представлениях" мы получим группировку слов в четырехмерном качественно-признаковом пространстве, то есть как бы разрежем облака тумана на четко разграниченные зоны.
А компьютеру только того и нужно. Теперь он легко разложит по полочкам наши зыбкие и неопределенные представления о качественных ореолах слов. Скажем, попадают в компьютерный классификатор слова автомобиль и лягушка. Компьютер проверяет их оценки по шкале "хорошее - плохое": автомобиль - 1,9, лягушка - 4,2. Компьютеру ясно - автомобиль нужно направить в "хорошую" группу, а лягушку в "плохую". Далее проверяются оценки по шкале "сильное - слабое", и автомобиль попадает в "хорошую и сильную" группу, лягушка - в "плохую и слабую", так как по этой шкале автомобиль имеет оценку 1,8, а лягушка - 4,3. Затем, пройдя шкалы третьего и четвертого уровней ("быстрое - медленное", "мужественное - женственное"), автомобиль оказывается в "хорошей, сильной, быстрой, мужественной" группе, лягушка - в "плохой, слабой, медленной, женственной".
Четыре уровня сортировки минимально необходимы, иначе качественный ореол не будет охвачен полностью. Но останавливаться на четвертом уровне не обязательно. Добавляя к автоматическому классификатору все новые и новые шкалы-уровни, мы обучаем компьютер все более тонким оттенкам качественно-ореольной семантики. Понятно, что с увеличением числа уровней сортировки будет увеличиваться число групп "на выходе" классификатора и группы будут все более дробными. А слова, в них попавшие, будут все теснее объединяться по качественно-ореольным характеристикам.
Четырехуровневый компьютерный классификатор исправно работает и формирует группы слов на удивление "осмысленно". Ничто не мешает подключить к нему новые шкалы и сортировать новые порции слов. Но вот беда: лингвисты уже 30 лет гадают, куда "приплыл" Ч. Осгуд - в Индию или в Америку, да все прикидывают, нужны ли нам такие измерения. А словаря качественных ореолов русских слов все нет. Классификатор есть, и работает хорошо, а классифицировать нечего. До сих пор всего несколько исследователей ведут измерения русских слов - это в основном А. Клименко, В. Петренко, А. Павлюк. Измерено несколько сотен слов, но главным образом по трем-четырем основным шкалам. А ведь нужно измерить десятки тысяч слов, да и шкал набрать побольше. Работа эта ведется, но столь малыми силами, что результатов придется ждать еще долго.
Многоуровневый классификатор будет иметь огромное число выходов. Так, при десяти уровнях количество классификационных групп приближается к 20 тысячам. Но это лишь теоретически возможные группы. На практике большое число выходов окажутся пустыми, то есть на этих выходах не будет не только групп, но и ни одного слова. А на других выходах классификатора соберутся группы, включающие множество слов. Кстати сказать, интересен и сам этот результат. Ведь если на каком-то выходе образовалась большая группа слов, значит, такая комбинация признаков очень важна для нас, а если выход пустой - это свидетельство несовместимости признаков или ненужности такой их комбинации.
Возникает еще вот какой вопрос: как быть со словами внутри групп, как разобраться в них компьютеру? Не окажутся ли они для него все на одно лицо? Ведь на первый взгляд кажется, что в группах слова перемешаны без какой-либо системы, как бы свалены в какую-то ячейку пространства "навалом". Это впечатление обманчиво. Во-первых, для более дробного деления групп компьютер всегда может подключать новые шкалы-уровни. Во-вторых, если некая группа слов не будет поддаваться такому способу дробления, а компьютеру все же нужно как-то упорядочить слова внутри ее, он всегда может обратиться к исходным данным - к средним оценкам слов по любому из нужных в данный момент признаков.
Например, если в четырехуровневом классификаторе слова корабль, автомобиль, самолет объединились в группу, оказавшись "хорошими, сильными, быстрыми, мужественными", то легко можно сравнить их между собой по какому-либо признаку, ранжируя их средние оценки. Скажем, по признаку "быстрое" они располагаются в зависимости от средних оценок так: самолет (1,8), автомобиль (2,2), корабль (2,4). Отсюда компьютер сделает вывод, что "нечто самое быстрое" среди этих слов - самолет, а "самое медленное" - корабль. По признаку "большое" расположение будет другим: корабль, самолет, автомобиль. Такое сравнение можно провести и по любому другому признаку, включенному в классификатор.
Качественный классификатор справляется и со словами, имеющими двойную оценку, и даже с "размытыми" по всей шкале - такие слова просто попадут одновременно на несколько выходов классификатора.
Например, слово регби по шкале "хорошее - плохое" имеет двойную оценку (и "хорошее" и "плохое"). Для классификатора не нужно вычислять среднюю оценку (все равно она будет фиктивной), вместо этого слову приписывается индекс (например, Д), который будет означать, что слово необходимо направить и на "хороший", и на "плохой" выходы. Попав на "хороший" выход, регби окажется в одной группе со словами игра, футбол, забава, спорт и т. п. На "плохом" выходе у того же слова окажутся другие соседи: грубость, драка, свалка, потасовка и т. п.
Слово женщина тоже имеет двойную оценку. Пройдя классификатор, "хорошая женщина" попадет в одну группу со словами мать, невеста, ласка, забота, любовь, нежность и т. п. Ну а "плохая женщина" будет окружена словами зависть, глупость, карга, выдра и т. п.
"Размытые" слова, такие, как дождь, попадут не на-два, а на несколько выходов. "Слабый и хороший" дождь окажется в группе со словами лето, радуга, свежесть; "сильный и плохой" - со словами гроза, буря; "слабый и плохой" будет соседствовать со слякотью, осенью, моросью, гнилью; "сильный и хороший" - с урожаем, добром и т. д.
Как видим, классификатор работает гораздо лучше, чем пространство. Но особое его удобство заключается еще и в том, что он легко может быть объединен с понятийным классификатором, то есть с автоматизированной системой анализа понятийной семантики. Для этого нужно просто пропускать через качественный классификатор те группы слов, которые образовались после работы понятийного.
Опора на два семантических аспекта - на понятийное ядро и качественный ореол - позволяет компьютеру неплохо ориентироваться в семантике текста и вести вполне "человеческую" беседу, хотя на самом первом, "понятийном" этапе компьютеру придется основательно помогать.
Например, вы спрашиваете компьютер:
- Как можно добраться из Ленинграда в Таллин?
В этом вопросе компьютер, увы, ничего не поймет. Ему тут просто не за что зацепиться. Глагол добираться слишком многозначен, его понятийное ядро размыто, неопределенно. Будем великодушными, снизойдем к непонятливости компьютера и переформулируем вопрос:
- На каком транспорте можно доехать от Ленинграда до Таллина?
Казалось бы, теперь все предельно ясно. Но это нам ясно. А компьютеру все еще не по силам разобраться в понятийной семантике вопроса. Слово транспорт объединяет слишком много самых разных понятийных групп. Скажем, городской транспорт - трамвай, троллейбус, метро - здесь не годится. Грузовой транспорт - тоже. А есть ведь еще транспорт как тип морского судна. Да и с Ленинградом и Таллином тоже все не просто. Компьютеру нужно знать, что это города, а не районы одного города, не разные страны или материки, что оба города расположены на берегах одного моря. И много еще чего нужно. Короче говоря, чтобы понять смысл даже такого простенького вопроса, необходимо сознавать ситуацию, чего компьютер сделать не в состоянии.
Допустим, мы как-то оградили нашего, мягко говоря, несообразительного собеседника от излишних семантических трудностей и задаем ему донельзя "разжеванный" вопрос:
- На каком пассажирском транспорте можно доехать от города Ленинграда до города Таллина?
Компьютер включает "понятийный классификатор", обнаруживает в группе "междугородный пассажирский транспорт" слова поезд, самолет, корабль, автобус, автомобиль и, наконец отвечает:
- Поездом, самолетом, на корабле, автобусе или на автомобиле.
Вы говорите:
- Только мне хотелось бы побыстрей.
Если бы компьютер обладал эмоциями, то здесь он бы облегченно вздохнул - кончилась непосильная для него работа с понятийными ядрами, он вырвался в область семантических ореолов, где чувствует себя гораздо более уверенно. Пробежав оценки этих ореолов по шкале "быстрое - медленное" и установив, что самое быстрое - самолет, а самое медленное - корабль, он уверенно отвечает:
- Быстрее всего, конечно, самолетом.
Вы сомневаетесь:
- Самолетом - это риск: вдруг дождь.
Компьютер не понял причины ваших колебаний, но уловил "размытое" слово дождь и спешит получить уточнения:
- Дожди бывают разные. Вы имеете ввиду с грозой и бурей?
- Да, в бурю самолет не полетит.
- Конечно, дождь с грозой и бурей - это плохо.
Но если слабый дождь, если свежесть, радуга - тогда все прекрасно.
Электронный собеседник взял реванш за тугодумие в начале беседы - он уже не только отвечает, но и сам спрашивает, рассуждает.
Вам понравилась его сообразительность, и вы пытаетесь установить, как далеко она простирается:
- А вам какой транспорт больше всего нравится?
Такой вопрос компьютеру нипочем. Увидев, что лучшая оценка по шкале "хорошее - плохое" у автомобиля, он безапелляционно заявляет:
- Я считаю, что лучше всего автомобиль.
Беседа наладилась, и вы позволяете себе попривередничать:
- Но мне хотелось бы отдохнуть в дороге, чтобы было тихо и спокойно.
До сих пор компьютер беседовал, обходясь основными качественными уровнями (были использованы факторы активности, силы и оценки). Теперь этой информации не хватает. Он ищет подходящие признаки и, обнаружив в вашей реплике слово тихо останавливается на шкале "громкое - тихое". На ней самым "громким" оказывается самолет, а самым "тихим" корабль, поэтому компьютер, поразмыслив, резонно советует:
- В таком случае, самолетом лететь не следует, отправляйтесь на корабле.
- А как насчет безопасности путешествия?
Компьютер подключает шкалу "безопасное - устрашающее":
- В общем-то все эти виды транспорта достаточно надежны, но если вы особенно осторожны, то ехать автомобилем я вам не посоветую, ну а корабль - это самое безопасное.
Хотя компьютер оказался упрямым и настоял-таки на своем первоначальном "замысле" - отправить вас в плавание на корабле, ясно, что разговор вели вы, заранее предвидя реплики машины. Но все же заметим, что выбор видов транспорта не был запрограммирован в ответах компьютера, он "сам" находил решения, исходя из запросов собеседника.
Понятно, что трафареты ответов машины составлены человеком и заложены в ее память. Но заполнял пустые места трафаретов компьютер самостоятельно: опираясь на анализ качественно-признаковых ореолов слов, он высказывал собственное мнение, давал оценки и советы. Иначе говоря, довольно убедительно имитировал понимание смысла вопросов и ответов, и особенно способным проявил себя не в постижении их логики (чего, казалось бы, следовало ожидать от бездушной машины в первую очередь), а как раз в овладении человеческими - эмоциональными, оценочными, личностными - сторонами речи.
|
ПОИСК:
|
При использовании материалов сайта активная ссылка обязательна:
http://informaticslib.ru/ 'Библиотека по информатике'