Анализ и синтез фоносемантики

Анализ и синтез фоносемантики
Как измерить впечатление от звука?
"Семантический дифференциал" одно время был очень популярным измерительным инструментом не только среди лингвистов, но и среди литературоведов, психологов, искусствоведов, среди всех, кто изучает человеческое восприятие, эмоции, мышление. Чего только с его помощью не мерили - литературных героев и целые литературные произведения, живопись (реалистическую и абстрактную), разные эмблемы, значки, знаки... И никто (странно, но это так), никто не догадался измерить звуки речи!
Далекий от филологии человек здесь, пожалуй, удивится восклицательному знаку. Подумаешь - звуки речи. Мало ли что еще "не догадались" измерить с помощью этого самого семантического дифференциала - шнурки от ботинок, например.
Но филолог... О, филолога здесь как током пронзит. Еще бы! Ведь это самый древний и, пожалуй, самый важный филологический (да и не только филологический) спор - значимы ли звуки речи, содержательны ли они сами по себе, вне слова, или это только безликий строительный материал слов, полностью безразличный, как говорят, "произвольный" по отношению к семантике? В первой главе мы уже беседовали об ореоле звуковой содержательности, и можно ручаться, что некоторые читатели безусловно соглашались с приведенными там примерами: для них фитюлька и тютелька действительно звучат как что-то маленькое, а хмырь - как что-то темное. Но столь же уверенно можно утверждать, что у целого ряда других читателей наши примеры не только не встретили понимания, а, наоборот, вызвали возражения: "Слово фитюлька обозначает что-то маленькое, неважное, несерьезное, вот автору и кажется, что звуки там какие-то "маленькие". На самом деле звуки сами по себе ничего обозначать не могут".
Вот так всегда и было еще со времен Гераклита, Демокрита и Платона, так продолжается и до сих пор: одни считают, что звуковая форма слова - только оболочка, в которую можно заключить любое содержание, другие полагают, что это кожа слова, часть его плоти, его сути, часть его содержания.
С первого взгляда спор может показаться схоластическим: считать ли звуки речи содержательными или нет, какая, собственно, разница. Но дело в том, что отношения между звучанием и значением слова - это одно из проявлений взаимодействий между формой и содержанием в языке. А диалектика взаимоотношений содержания и формы исключительно важна в жизни любого явления, в том числе, безусловно, и языка. Многие философские и филологические проблемы, связанные с возникновением, развитием и функционированием языка, получают различные решения в зависимости от того, признается звуковая форма языковых единиц содержательной или нет. Вот и спорили философы, языковеды, литературоведы, психологи на протяжении веков. Но веских и однозначных доказательств не могла привести ни одна сторона. В XX веке спор стал постепенно затухать и почти уже забылся, как вдруг вспыхнул с новой силой, получив пищу с совершенно неожиданной стороны - от кибернетики.
По некотором размышлении становится ясно, как это произошло. Выстроилась такая цепочка. Кибернетика упорно ищет пути овладения языковым содержанием, что пока ей плохо удается. А звучание - это форма языковых единиц, которая выражена материально, которая ощутима, измерима и потому несравненно легче доступна кибернетизации, чем содержание. Если же форма сама оказывается содержательной и является частью языкового содержания, то вот вам искомый путь к изучению, к постижению самого этого содержания.
Нет-нет, кибернетики не обольщались кажущейся легкостью пути. Понятное дело, заманчиво было бы найти такой способ манипуляций со звуковой формой слова, чтобы в результате постичь его содержание. Но чудес не бывает. Форма и содержание - вещи разные, они не могут заменить друг друга, не могут и полностью совпадать. Соответствовать др>1' другу - да, но не совпадать! Да и соответствовать-то не однозначно, не жестко, а сложно, диалектически. Содержание и форма стремятся к взаимному соответствию, могут его обрести, но подвижное содержание может вырваться из формы, перестать ей соответствовать или даже прийти в противоречие с ней. Да и языковая форма - не застывшая чугунная отливка, она тоже может измениться и нарушить гармонию.
Все это так. Но если есть хоть малейшая надежда "зацепиться" через форму за любой, пусть даже и не главный, аспект языкового содержания, кибернетики этой возможности не должны упускать. Слишком важна цель, чтобы отказываться от любых способов приближения к ней, Потому кибернетики и заинтересовались такой даже для лингвистов экзотической проблемой, как содержательность звуков речи.
И тут как нельзя кстати пришелся "семантический дифференциал". Он оказался как будто специально созданным для измерения звуковой содержательности. Здесь он сработал даже лучше, чем при измерении качественного ореола слов.
Первым увидел возможность измерения содержательности звуков речи психолог и математик Ю. Орлов. И не случайно: он сразу, раньше многих лингвистов, осознал важность "семантического дифференциала" для изучения языкового значения, правильно оценил силу и возможности этой необычной методики. Потому и решил попробовать ее на звуках речи. Под его руководством и автор начинал захватывающую и странную экспериментальную работу со звуками.
Странность экспериментов действительно бросалась в глаза. Представьте себе: информантам дают отдельные звуки речи - О, К, Д, Р, Ы, А, Ф и т. д. - и просят поставить им оценки по признаковым шкалам. Конечно, информанты недоумевают - как это "большой" звук? или "светлый"? или "тяжелый"? Не может быть у звуков таких характеристик! А экспериментатор продолжает удивлять: "Долго не размышляйте, ставьте отметки наугад". Некоторые информанты хитро улыбаются: "Знаем, мол, мы вас, экспериментаторов. Небось какие-нибудь наши качества выявляете, а звуки здесь ни при чем. Но нас не проведешь, мы вам сейчас наставим этих отметок кое-как, а вы потом разбирайтесь".
Как-то после одного из экспериментов я услышал в коридоре разговор информантов:
- Ну и придумают же какую-то чушь - "безопасные" звуки! Я ему от фонаря этих оценок наставил.
- А я тоже с потолка написал. Каков вопрос - таков ответ.
И не передать тому, кто этого не испытал, какой охватывает трепет, когда после утомительного суммирования многих и многих ответов выстраиваются средние оценки, указывающие на непреложные закономерности: поставленные "наугад", "от фонаря", "с потолка" цифры, усреднясь, показывают, что О - для большинства "светлый" звук, а Ы - "темный", Р - "устрашающий", а И - "безопасный", К - "быстрый", а "медленный", и так все звуки по многим шкалам-признакам, причем все это измерено, зафиксировано в числе!
В горячке увлеченности мы днем проводили эксперименты, а по ночам считали вручную. К ЭВМ тогда еще было не пробиться, о микрокалькуляторах никто и не помышлял, выручал только старенький арифмометр "Феликс". Юрий Михайлович даже выполнял вручную факторный анализ. Математики, знающие, что и для ЭВМ эта работа не из мелких, оценят сказанное.
Пространство, как и у Ч. Осгуда, получилось трехмерным, и меры те же - оценка, сила и активность. Расположив в семантическом кубе измеренные звуки, мы впервые получили русское фонетико-семантическое пространство. Оказалось, что все звуки русской речи обладают, в большей или меньшей степени, явно выраженной содержательностью, которую можно вполне строго измерить. Сомнения отпали - звуки речи содержательны!

Как измерить впечатление от звука?
Получив ошеломившие нас самих результаты, мы написали статью и направили ее в столичный лингвистический журнал. Как наивны мы были у себя в провинциальном Балашове, когда плавали на веслах по тогда еще тихому, безмоторному Хопру и горячо обсуждали возможные громоподобные последствия нашей публикации. Статью, как легко догадаться, не приняли. Тогда было огорчительно, а теперь понятно, что и не могли принять - слишком дискуссионна проблематика, необычен подход, непонятен метод, невероятны результаты. Редколлегии и рецензентам трудно работать с таким материалом. Ведь новое - значит не известное никому, в том числе и рецензентам. Правда, в то же время к той же цели шли, хотя и разными путями, другие исследователи - В. Галунов, В. Левицкий, И. Горелов, С. Воронин. Но их статьи, видимо, тоже отклонялись рецензентами, а сами они в редколлегии, увы, не входили.
Это теперь по фоносемантике защищаются диссертации, публикуются статьи и книги. Она поднялась до ранга самостоятельной теории, и практические приложения ее значительны и разнообразны. Есть и компьютерное приложение, а именно - имитация фоносемантиче-ских ореолов языковых значений.
И вот ведь как получилось: потаенный, подсознательный семантический ореол, в самом существовании которого сомневаются не только обычные носители языка, но даже многие профессионалы-лингвисты, оказался наиболее доступным компьютеру. Имея в своей памяти только средние оценки звуков по определенному набору шкал да сведения о том, как часто встречается каждый звук в русской речи, компьютер сам вычисляет фоносемантический ореол любого слова и вообще любого звукосочетания.
Если вдуматься - ничего странного в этом нет. Ведь компьютеру переданы (в доступной ему числовой форме) суждения носителей языка о содержательности звуков речи. И теперь машина стала представителем всех этих информантов, сама стала как бы усредненным или коллективным носителем языка со свойственными человеку суждениями о фоносемантике.
Правда, дальше компьютер уже действует сам, переходя от содержательности отдельных звуков к содержательности звукосочетаний и слов. Конечно, и здесь должен действовать принцип "доверяй, но проверяй". Прежде чем доверить самому компьютеру высказывать суждения о столь тонком явлении, как фоносемантический ореол слова, результаты компьютерных расчетов многократно проверялись, сравнивались с человеческими оценками и суждениями.
Заметим, кстати, что сделать это тоже непросто. С компьютером нет проблем - он значений слов не понимает и вычисляет только содержательность их звучания. А как быть с человеком? Ведь если попросить информантов оценить содержательность звучания слов, то они этого просто не смогут сделать, как бы ни старались. Люди четко осознают в первую очередь понятийную и отчасти качественно-признаковую семантику, потому на эти аспекты значений слов в основном и реагируют, а совсем не на смутную, скрытую, подсознательную фоносемантику. Это лишь дополнительный, третьестепенный аспект значения слова, почти незаметный на ярком фоне главных семантических аспектов.
Действительно, если человек описывает открывающийся перед ним вид, то прежде всего он будет называть предметы, а не воздух. И хотя воздух тоже здесь присутствует, он нужен, важен, без него нельзя, все же он "за кадром", он незаметен, внимание на нем не фиксируется. Можно специально обратить внимание созерцателя на воздух, и тогда он его сможет охарактеризовать, только все равно эта характеристика будет менее яркой и полной, чем характеристика четко осознаваемых предметов.
Так и со словами: предложите оценить по любой признаковой шкале любое слово - едва ли кто-нибудь станет оценивать его звучание, оцениваться будет качественно-признаковый ореол. Даже если вы специально попросите оценить именно звуковую форму слова, то понятийный и качественно-признаковый аспекты все-таки неизбежно "перетянут" на себя внимание информантов, а фоносемантика так и не будет измерена.
Как "отключить" человека от всех других аспектов значения слова, кроме фоносемантического? Как уравнять в этом плане человека и компьютер, чтобы проверить данные компьютера человеческим восприятием?
Кажется, у этой задачи нет решения, но все же оно есть. И не такое уж сложное, хотя и хитроумное. Нужно, чтобы у слов просто-напросто не было ни понятийного ядра, ни признакового ореола, а был бы только фоносемантический ореол. Только где взять такую лексику? "Безъядерные" слова, как мы видели в первой главе, еще можно найти, но чтобы без качественного ореола, это уж едва ли.
А почему бы не построить специально, почему бы не сконструировать звукосочетания, похожие на слова, но лишенные всех аспектов значения, кроме фоносемантического? Какие-нибудь лимень, букоф, вробар, урщух, незич, фрыш и т. п. Звуковая форма у них есть, значит, есть и фоносемантика. А "плоти" под формой нет. Как будто мундир надет на манекен. Вот это нам как раз и нужно.
Дальше все просто. Компьютер рассчитывает по всем шкалам теоретическое, "ожидаемое" воздействие звуковой формы этих "слов" на информантов, а настоящие информанты оценивают те же "слова" по тем же шкалам. Сходство результатов - критерий правильности компьютерных расчетов, а следовательно, правильности компьютерного моделирования фоносемантики.
С помощью примерки на десятках таких манекенов постепенно вырабатывался наиболее эффективный способ расчета суммарной фонетической содержательности звуковой формы слов, то есть компьютер постепенно учился все лучше и лучше "понимать" фоносемантику, все точнее имитировать человеческое восприятие этого аспекта значения слова.
Вычислитель, собеседник, советчик
В основном техника компьютерных расчетов сводится к вычислению оценки, усредненной по всем средним оценкам составляющих слово звуков. Но есть и кое-какие тонкости.
Прежде всего: в какой форме задавать слова компьютеру? Мы всё говорим - звуки, звучание, звуковая форма слова... Но компьютер звучащей речи пока не воспринимает. Общаться с ним приходится письменно. А буквенная и звуковая формы слова - это не одно и то же. Мы пишем яблоко, но произносим на месте буквы я два звука (j - йот, звук, близкий к й, плюс звук а), а на месте о вообще что-то непонятное - какой-то призвук, нечто среднее между а, о и ы. Пишем окно, а произносим почти акно, пишем солнце, а произносим солнце (опять-таки с непонятным звуком в конце), пишем любовь, а произносим льубофъ и т. д. и т. п. Как быть?
Для филолога неразличение звука и буквы - это смертный грех, даже вообразить себе такое немыслимо. Однако для обычного носителя русского языка между звуком и буквой нет такой уж непреодолимой пропасти. Например, в сознании (или подсознании) каждого грамотного человека звук и буква сливаются в единый психический образ. А формирует этот образ, фиксирует его, делает его более четким и определенным отнюдь не звук, а как раз буква. И сами отдельные звуки человек начинает осознавать только тогда, когда выучивает буквы. Неграмотный никаких звуков в слове не выделит. В лучшем случае выделит слоги. Спросите его, из каких звуков состоит слово мама, и он скажет: ма-ма. И только зная буквы, обычный носитель языка может указать звуки слова, но и тут будет постоянно сбиваться на буквы - они для него более реальны, более наглядны, определенны. Он обычно удивляется, если ему сказать, что в начале слова юг звучит вовсе не ю, а j+y. Запись jyk для него странна и непривычна. Спросите любого русского, какой звук звучит в конце слова любовь, и большинство скажет - въ, хотя совершенно явственно произносится фъ.
Конечно, в школе учат различать звук и букву, поэтому сознанием человек может уяснить, что ю это не ю, а j+y. Но подсознательно он все равно считает ю единым звуком, или, лучше сказать, единой звукобуквой. Так что же, давать компьютеру буквы, да и все?
Нет, это тоже крайность. Есть, оказывается, психологически чрезвычайно важные моменты звучащей речи, которые в буквах не отражены. Любопытно, что если, скажем, француз или англичанин, не знающие русского языка, услышат слова мел и мель, то они будут уверены, что это одно слово. Разницу в их звучании они просто не уловят. И очень удивятся, если им сказать, что русские совершенно четко и определенно слышат здесь два разных слова, которые никогда не спутают. Так же как француз не может перепутать разные звуки е - открытый и закрытый,- тогда как русскому разница в их звучании представляется почти неуловимой.
Дело здесь в том, что в разных языках особенно важными становятся разные характеристики звуков речи. Для русских мягкость согласных чрезвычайно важна - она является смыслоразличительной, то есть от замены в слове одного только твердого звука на парный ему мягкий резко меняется смысл. Замените л в слове угол на ль - получится совсем другое слово уголь, хотя звучание изменилось чуть-чуть, еле заметно.
Иногда носителю одного языка кажется просто странным, что носитель другого языка не замечает таких, казалось бы, явных различий в звучании. Например, узбеки, изучая русский язык, поначалу путают п и ф.
Учительница, преподающая русский язык в узбекской школе, рассказывала:
- Диктую слово "профессор", а Саид пишет на доске: "aропессор". Его дружок шипит с первой парты:
- Саид, первая n - не такая n (руки в бока кренделем), а такая n (свесил руки коромыслом).
Русские удивляются: как же не замечать такой разницы? А удивляться-то нечему: в узоекском языке эта разница не играет никакой роли, вот они ее и не замечают.
Со мной был случай, когда я поразился собственной языковой "тугоухости". На одной конференции в перерыве мы беседовали с англичанином, который неплохо знал русский язык, но учил его в Англии и разных русских говоров не слышал. И вдруг он меня спрашивает:
- Скажите, что такое по-русски "хайка"?
Я растерялся.
- Не знаю, - отвечаю, - такого слова. Где вы его слышали?
А рядом двое рабочих устанавливают к очередному докладу демонстрационную аппаратуру.
- Да вот же рабочий несколько раз сказал "хайка", - говорит англичанин.

Вычислитель, собеседник, советчик
И тут только меня осенило: рабочий произносил г-фрикативный на южнорусский манер. Получалось действительно вместо гайка почти что хайка. Говорящие по-русски замечают, конечно, эту черту произношения, но особенного значения ей не придают, потому что это изменение звучания хотя и очень резкое, но несмыслоразличительное, смысла слов оно не изменяет.
Зато уж если от произношения зависит смысл слова, то даже самые тонкие особенности звука становятся для носителя языка очень важными и заметными. Такова мягкость согласных для русских.
И в оценках содержательности звуков по измерительным шкалам разница твердых и мягких согласных проявляется совершенно определенно: твердые согласные "сильнее, мужественнее, грубее", тогда как мягкие - "слабее, женственнее, нежнее".
Что и говорить - компьютеру обязательно нужно учесть эту особенность восприятия звуков. Да только вот как получается - твердость и мягкость согласных, важнейшее свойство русских звуков речи, не отражено в буквах. В слове рад начальный согласный твердый, а в слове ряд - мягкий, но буква одна - р.
Пришлось обучать компьютер самостоятельно обнаруживать твердые и мягкие согласные. Правда, сделать это оказалось не так уж сложно, потому что согласные становятся мягкими в основном в определенных позициях, которые компьютер научился находить.
А что касается других различий звуков и букв, то они оказались либо практически несущественными для расчета фоносемантики слов, либо выбор пришлось сделать в пользу буквы, как то подсказала "примерка на манекенах". Для компьютера это большое удобство, так как слова можно вводить в обычном печатном виде. Компьютер сам устанавливает мягкость согласных и приступает к расчету содержательности "звукобуквенной" формы слов.
Да, форма не звуковая и не буквенная, а именно звукобуквенная. Например, слово любовь в таком виде и вводится в компьютер, но он преображает ее так: л'юбов' (апостроф - знак мягкости). Как видите, компьютер отметил мягкость звуков и в то же время сохранил букву ю. Но чтобы не вводить нового, непривычного термина, станем по-прежнему говорить "звук", и только там, где это необходимо для правильного понимания сказанного, будем употреблять термин "звукобуква".
В расчетах тоже есть свои особенности. Не все звуки в составе слова равноценны, не все вносят равный вклад в восприятие слова как единого звукобуквенного комплекса.
Ясно, что ударные гласные заметнее безударных. Они звучат четче, громче и дольше. Значит, их роль должна быть подчеркнута, вес их средних оценок при расчетах должен быть увеличен.
Но оказывается, первый звук слова информативно еще более важен, чем ударный. Действительно, все первое ново и свежо, особенно заметно, сразу бросается в глаза,выделяется, запоминается. Все последующее блекнет, становится обычным, теряет свою информативность. Так и в жизни, так и в слове. Первый звук слова своей содержательностью как бы задает тон, окраску всем последующим звукам, будто включает регистр, в котором будет звучать слово. Замените "красивый" звук мъ на "отталкивающий" хь, и получится вместо красивого слова милый отталкивающее хилый. А ведь поменялись только первые звуки, остальные остались теми же. Или прочитайте наоборот нейтральное, не вызывающее никаких особых эмоций слово мах - получите "грубое" слово хам. Это "грубый" х, став первым, окрасил своей содержательностью всю звуковую форму слова. Следовательно, вес средней оценки первого звука тоже должен быть увеличен, и еще больше, чем ударного.
Однако самая большая разница в информативности звуков слова вызвана обстоятельством, которое мы, казалось бы, не замечаем, а именно - разницей в частотности, или встречаемости, звукобукв в речи. Опять-таки, как и часто повторяющиеся события становятся обычными, теряют информативность, как слова от частого повторения "в привычку входят, ветшают, как платье", так и часто встречающиеся в речи звуки тоже оказываются малоинформативными, не задерживают на себе внимания, а значит, и незначительно влияют на восприятие слова, на формирование его фоносемантического ореола.
Редкие события высокоинформативны, они останавливают на себе внимание, выделяются из общего потока. И если в слове встречается редкий звук, он переключает на себя внимание воспринимающего, его содержательность становится доминирующей. И чем больше разница в частоте встречаемости между частыми и редкими звуками слова, тем выше информативность редких звуков, тем больше нужно увеличивать вес их средних оценок по сравнению со средними оценками остальных звуков.
Все эти расчеты компьютер выполнит легко, но ему для этого нужны данные об употребительности звукобукв. Те сведения, которые имелись в печати, не совсем подходили - ведь нужны данные именно о вукобуквах, а не о звуках или о буквах, да еще и отдельно по ударным и безударным гласным, да еще в какой-то нейтральной "усредненной" речи. Пришлось вести подсчеты по разным текстам, записывать на диктофоны разговорную речь в разных ситуациях. Работа большая, однообразная, изнурительная. Но что делать, других путей не было.
Забегая вперед, следует сказать, что теперь и эту работу смог бы выполнить сам компьютер. Когда мы перешли от отдельных слов к целым текстам (о чем будет рассказано ниже), компьютер все равно подсчитывал вероятности звукобукв. Не удержусь и похвастаю: компьютерные подсчеты, проведенные на гигантском материале, мало что изменили в наших данных, полученных вручную тяжелым трудом на выборках несравненно более скромного размера. Но это так, к слову, и не в укор машине. Ведь сколько времени и сил пришлось потратить на эту в общем-то подсобную, подготовительную работу! А компьютер выполнил ее походя, играючи.
Но наконец готово все. Многократно выверена, уточнена и перепроверена основная таблица, содержащая средние оценки всех русских звукобукв по 20 признаковым шкалам. Готова и таблица вероятностей звукобукв. Теперь слово за компьютером. Вот тут уж с ним вручную не потягаешься. Ручной расчет фоносемантического ореола даже для одного слова по всем шкалам - дело длинное, а печать машины стрекочет безостановочно, успевай только перфокарты загружать. А если работать с дисплеем, то время расчета - это фактически время набора слова на алфавитной клавиатуре. Иначе говоря, компьютер, как и человек, моментально "схватывает" фо-носемантику слова.
Для тех, кому нравится более строгое изложение схемы вычислений, приведем формулы, по которым работает компьютер.
Если частотность (вероятность) любого (i-того) звука слова обозначить как Рi, а максимальную частотность звука в данном слове как Рmах, то коэффициент, учитывающий разницу частотностей звуков слова k1, можно вычислить как отношение:
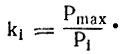
Теперь нужно учесть место каждого звука в слове. Для этого коэффициент первого звука слова (k1) увеличим в четыре раза:
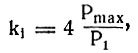
а для ударного (kуд) - в два раза:
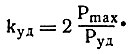
После этих приготовлений напишем основную формулу:
где F - фонетическая содержательность слова (его фоносемантика);
fi - фонетическая содержательность очередного (итого) звука слова;
ki - коэффициент для очередного (i-того) звука слова;
Σ - знак суммы.
Последняя "примерка на манекенах" показывает, что все в порядке - схема расчета в общем верна. Информанты считают, что "слово" незич звучит как нечто "маленькое" и "нежное", а фрыш - как нечто "плохое, грубое, страшное", и компьютер дает примерно те же характеристики. По мнению информантов, хифелъ и уршух страшное, а лименъ и нитис - безопасное; компьютер того же мнения. Вробар и вакам кажутся информантам сильными, и компьютер выдал для них тот же признак.
Значит, способ расчета можно переносить и на настоящие слова. Конечно, спасительная оглядка на информантов теперь невозможна, но компьютер уже научился правильно имитировать человеческое восприятие фоносемантического ореола слов. Использовать эти свои умения он может разнообразно, и некоторые из возможностей мы ниже обсудим.
В результате вычислений слово по каждой шкале получает суммарную оценку фоносемантики, выраженную в единицах пятиранговой измерительной шкалы, то есть такую же оценку, как и средняя оценка содержательности отдельного звука. По суммарной оценке, опять-таки точно так же, как и по средней оценке для отдельного звука, слово получает характеристику в терминах шкалы. Например, для слова дом - по шкале "хороший - плохой" компьютер получил суммарную оценку 2,3. Оценка находится в левой ("хорошей") значимой зоне шкалы "хороший- плохой", поэтому компьютер выбирает для характеристики фоносемантического ореола этого слова признак "хорошее". Другими словами, по "мнению" компьютера, имитирующего наше с вами восприятие фоносемантики, звучание этого слова (точнее, его звукобуквенная форма) производит впечатление чего-то "хорошего". А для слова хам вычислена суммарная оценка 3,8. Она располагается в правой ("плохой") значимой зоне шкалы, поэтому компьютер "полагает", что звучание этого слова производит впечатление чего-то "плохого". И так по всем 20 шкалам.
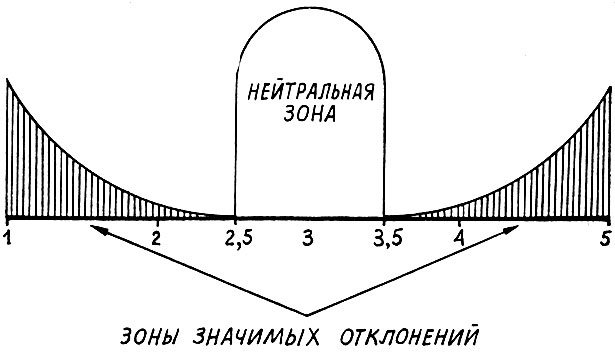
Значимые зоны школы определяются так, как показано на рисунке:
Вычислитель, собеседник, советчик
Если слово получает среднюю оценку от 1 до 2,5, то для характеристики качественного ореола слова выбирается левый признак шкалы (например, "хорошее"); если средняя оценка от 3,5 до 5, то в качестве характеристики выбирается правый признак (например, "плохое"); если оценка от 2,6 до 3,4, то никакого признака по данной шкале слово не получает.
На печать или на экран дисплея информацию можно вывести по-разному. Если нужно побольше информации, то лучше всего вывести и суммарные оценки, и выбранные характеристики. Можно также для наглядности изобразить величину отклонений суммарных оценок от среднего (нейтрального) деления шкал.
Вся эта информация на экране дисплея имеет следующий вид:

Здесь слева указаны первые признаки каждой шкалы. Вторые (антонимичные) признаки для экономии места не приводятся, хотя в памяти компьютера все они есть. Эти 40 прилагательных, заданных компьютеру, и составляют его лексикон, с помощью которого он может охарактеризовать фоносемантический ореол слова. Далее следует столбец вычисленных компьютером суммарных оценок фоносемантики слова по каждой шкале. Еще правее - выбранные компьютером значимые признаки, которые и являются словесной характеристикой фоносемантического ореола заданного слова.
В данном случае компьютер выбрал для характеристики фоносемантики слова робот признаки с оценками от 1 до 2,5 и от 3,5 до 5. Остальные признаки в описании звуковой содержательности слова не участвуют. Заметьте, что если оценка признака помещается в пределах от 1 до 2,5, то компьютер выбирает тот признак, который указан в списке шкал, например, "большое". Если же оценка попадает в зону от 3,5 до 5, то компьютер выдает признак, противоположный тому, который указан в списке шкал (например, "грубое").
Такой вывод результатов информативен, экономичен, но рассчитан скорее на специалистов. Если же мы в каких-либо прикладных целях хотим создать эффект общения с компьютером, то можно вывести результаты менее строго, зато более доступно и занимательно. Вместо того чтобы просто вводить в компьютер слово и получать сухие выжимки вычислений, можно организовать довольно содержательный диалог с машиной.
Например, будущий папаша решил подойти к решению извечной проблемы выбора имени для ребенка во всеоружии самой современной техники:
- Я хотел бы подобрать имя для ребенка. Что вы посоветуете?
Все понятно - момент ответственный, человек волнуется и забывает уточнить существеннейшую деталь. Но компьютер ему помогает:
- Вам для мальчика или для девочки?
- Пока не знаю. Но давайте сначала попробуем для девочки. Может быть, Юля?
- Прекрасное имя, - отвечает компьютер. - Оно нежное, женственное, красивое - как раз для девочки. Только оно лучше подойдет тоненькой, невысокой и подвижной девушке. Ваша дочь будет такой, когда вырастет?
- Трудно сказать. Но я довольно высокий и крупный, жена тоже среднего роста и... не такая уж худенькая.
- В таком случае, может быть, поищем другое имя?
- Да, да. Только обязательно нежное и женственное.
- Вы брюнет или блондин?
- Какое это имеет значение?
- Имеет, имеет.
- Скорее шатен.
- А ваша жена?
- Это еще зачем?
- Сейчас все станет ясно.
- Жена - блондинка.
- Значит, девочка скорее всего будет светленькая.
- Надеюсь.
- Тогда имя ей тоже нужно подыскать светлое. Не так ли?
- Конечно. Может быть, Таня?
- Прекрасное имя. Но скорее как раз для темненькой девочки.
- А если что-нибудь редкое, необычное? Вот я читал, что Харита по-древнегречески значит "прелесть".
- Ну что вы! Вам, конечно, виднее, только звучит это имя темно, грубо и даже страшно. Думаю, дочь вас за такое имя не поблагодарит.
- Вот как? Тогда, нечего и говорить, не подходит. А возможно, что-то старорусское, Марфа, например, или Глафира
- Графира - имя древнегреческое, Марфа - тоже не совсем русское, но на Руси действительно эти имена были распространены. Однако по звучанию их ни нежными, ни женственными, ни светлыми ни назовешь. И красоты в их звучании тоже нет.
- Тогда что же вы посоветуете?
- Думаю, подходящим было бы имя Ольга. Оно звучит как нежной, светлое, сильное, величественное.
- Вот тебе и раз!
- В чем дело?
- Жена сказала: "Если будет девочка - назовем Олей".
- Значит, так и называйте.
- Спасибо за совет. А теперь для мальчика. 1олько учтите, что он наверняка будет в меня.
- Тогда назовите Андреем. Звучит как активное, сильное, красивое.
- Ура! Я же говорил! А жена хотела назвать Игорем.

Вычислитель, собеседник, советчик
Не беда что и без компьютера будущие родители вполне справились бы с подбором имен. Для нас важно, что в беседе машина была не пассивным ответчиком на вопросы, а активно вела разговор, не только имитируя владение семантикой, но и предлагая человеку новую информацию. А ведь она опиралась только на анализ содержательности звучания. Хотя, как можно заметить, в эту программу вполне органично входят и дополнительные сведения (например, о происхождении, распространенности, первоначальном значении имен).
Все трафареты реплик компьютера опять-таки подготовлены заранее, но основную информацию об именах, ради которой и идет беседа, компьютер получает и вставляет в схемы своих реплик сам. И беседа получилась не такой тривиальной, как относительно поездки из Ленинграда в Таллин, не правда ли? Его "суждения", а точнее, имитация суждений человека уже не столь банальны. Напротив, они содержат сведения, которые путем логических рассуждений человек получить не может или логика его подводит (как это случилось в ситуации с именами Харита, Марфа, Глафира). Тонкие аспекты фоносемантики не поддаются рациональному истолкованию, поэтому человеку в этом вопросе вовсе не лишне будет посоветоваться с компьютером. Ведь для человека фоносемантика - неявный ореол. Он его хоть и чувствует, но далеко не всегда может полностью осознать и четко истолковать. А компьютер, наоборот, ничего не чувствует, зато легко "вычислит" фоносемантику любого слова и охотно сообщит результаты человеку. Как видим, здесь компьютер выступает не только как имитатор - он помощник человека, его сотрудник и даже советчик. Разговор с ним становится интересным и нужным.
Сейчас закончено составление на компьютере фоносемантического словаря, включающего 10 тысяч существительных. Когда он будет опубликован, то пригодится самым разным специалистам.
"Суждения" компьютера, зафиксированные в словаре (а фактически, суждения сотен тысяч носителей русского языка, представителем которых выступает компьютер), окажутся и практически полезными. Скажем, тем специалистам, которым нужно придумывать названия новым товарам, профессиям, учреждениям, кинотеатрам, ансамблям, да мало ли чему еще. Ведь звуковая форма имен и названий играет важную роль в их функционировании.
Взять хотя бы пример с названием аппаратов для автоматической переработки информации. Инженеры наверняка не посоветовались с лингвистами, когда придумывали имя своему детищу, поэтому имя получилось невыразительным и неуклюжим - электронно-вычислительная машина. Нормально функционировать в речи такое название, конечно, не могло, и появилось сокращение - ЭВМ. Но и оно не лучше: произносить неудобно, формы образовать невозможно. Как скажешь - эвээмы? эвээмный? эвээмизация? эвээмизовать? Помучились, помучились с этим словом, да и заменили его на компьютер. И сразу как плотину прорвало - зазвучало в речи: компьютеры, компьютерный, компьютеризация... Конечно, дело тут не столько в слове, сколько в самом процессе начавшейся широкой компьютеризации всех "информационных" областей нашей жизни. Но и название как бы помогает этому процессу.
В тех случаях, когда нужно придумать слово, для которого неважно понятийное ядро (например, в рекламных текстах или в фантастических произведениях для обозначения новых, придуманных автором предметов), компьютер может выступать не только анализатором, но и синтезатором фоносемантического ореола. Иначе говоря, он сам сможет придумывать "слова", которые чаще всего окажутся лишенными понятийного ядра, но будут обладать фоносемантикой с заданными параметрами.
Например, нужно придумать "слово", которое звучало бы как нечто сильное, красивое, активное. Эти характеристики задаются компьютеру, и он, соблюдая правила сочетания звуков, действующие в русском языке, строит "слова" только с такими параметрами фоносемантики. В большинстве случаев синтез даст звукосочетания, похожие на русские слова, но лишенные понятийного значения. Однако случайно в "творчестве" компьютера попадутся и нормальные слова русского языка с заданной фонетической содержательностью. Человеку останется только выбрать те из "творений" компьютера, которые он посчитает наиболее подходящими для своих целей.
В компьютерных программах, основанных на анализе фоносемантики, достигается высокий уровень эффекта общения с машиной. Человек даже эмоционально реагирует на высказывания компьютера о содержательности звучания слов, имен, названий, не соглашаясь с ним или радуясь подтверждению своих догадок. Он как бы даже забывает, что перед ним - электронное устройство. А когда компьютер будет оснащен синтезатором речи, то есть заговорит, эффект общения с ним станет еще более полным.
|
ПОИСК:
|
При использовании материалов сайта активная ссылка обязательна:
http://informaticslib.ru/ 'Библиотека по информатике'