Кроме искусственно вводимой избыточности, есть и естественная, например в человеческом языке. Какую роль играет избыточность в языке?
Искусственно вводимая в сигнал избыточность снижает скорость передачи информации, но дает защиту от помех. Есть и естественная избыточность в передаче сообщений. Человек использует ее с незапамятных времен, не подозревая об этом. Речь идет о нашем языке, об информационном канале, который связывает нас с сотнями тысяч ушедших поколений и свяжет грядущие поколения с нами.
Оперируя только двумя различными кирпичиками - "да" и "нет", 0 и 1, " + " и "-", - мы уже научились передавать и простые, и сложные сообщения. Эти два элемента или две буквы, составляющие весь наш алфавит, можно сделать хорошо различимыми и обеспечить надежную передачу информации.

В связи с этим возникает вопрос: почему человечество в процессе своей длительной эволюции не приняло этот простейший и надежный алфавит, а использует во много раз более сложные? Так, русский алфавит содержит 32 буквы, или 32 различных кирпичика вместо двух минимально необходимых.
Попробуем заменить 32 кирпичика только двумя. Для этого каждую из 32 запишем в виде группы из нулей и единиц.
Легко подсчитать, что если принять равное число двоичных кирпичиков, из которых мы складываем каждую букву, то наша группа должна состоять ровно из пяти нулей и единиц. Следовательно, новая азбука будет выглядеть, например, так:
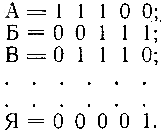
Такого типа кодирование используется в настоящее время при передаче телеграмм.
Малыши с восторгом, наверное, встретили бы замену 32 букв двумя, но потом взвыли бы от заучивания длиннющих слов. Кстати, на телеграфе поданная телеграмма тут же переводится в двоичную азбуку типа нашей (код Бодо) и в таком уже виде бежит по каналу связи к адресату.
Теперь попробуем воспользоваться нашей азбукой в разговоре. Вы попали в беду и пытаетесь прокричать "Помогите!". Каждую букву вам придется произнести пять раз, а всего этих сигналов "да - нет" потребуется сорок.
Далее, мы построили новую азбуку без всякой избыточности. Превращение по каким-либо причинам 1 в 0 или 0 в 1 сразу превращает истинную букву в ложную, Значит, для защиты речи от всяческих помех, надо ввести избыточные "да - нет". Например, к каждому биту информации приставить по два "телохранителя". Тогда крик о помощи потребовал бы цепочку из 120 "да - Гнет!". Думаю, что может не хватить ни сил, ни времени.
Отсюда следует вывод: упрощение алфавита приводит к удлинению сообщения и, соответственно, сигнала в канале связи.
Поэтому в сложном и еще далеко не раскрытом пути эволюции языка человек подсознательно использовал не двоичный алфавит, а с большим числом элементов. Возможно, что на ранних этапах имел хождение, конечно, двоичный алфавит.
Как мы видели, информация, сообщаемая одним элементом (одной буквой), зависит от общего числа букв в алфавите, из которых он выбирается, то есть от числа возможных исходов (помните?). При двоичном алфавите это будет 1 бит информации, а при 32-ичном (log 32 = log 25 = 5 бит) в пять раз больше! (При условии, что все буквы этих алфавитов одинаково часто встречаются в словах.)
В этом и состоит чудо перехода на большой алфавит: за одно и то же время разговора или за одно и то. же время передачи по каналу связи вы передаете значительно больше информации.
Можно приближенно считать, что в русском языке употребляется 50 тысяч слов. Люди пользуются этим богатым наследием предыдущих поколений по-разному. Александр Сергеевич Пушкин, как показывает анализ, использовал в своих сочинениях около 20 тысяч слов. "Героиня" из "Двенадцати стульев" И. Ильфа и Е. Петрова Людоедка Эллочка "легко и свободно обходилась тридцатью". Иногда, проходя по коридорам института, слышишь, как студенты щеголяют "универсальными" словечками-заменителями типа "железно", "клево", "в элементе", скатываясь в компанию Людоедки Эллочки.
Одна из причин бессмертия А. Пушкина в том, что он находил самое точное слово, несущее тончайшие оттенки мыслей и чувств человеческих. Находил из огромного запаса в 20 тысяч слов, и потому каждое его слово насыщено богатейшей информацией.
А сколько слов всего можно образовать из нашего русского алфавита? Если не ограничивать их длину, то из любого алфавита, включая и двоичный, можно образовать бесконечное количество слов или бесконечное число комбинаций. Но очень длинные слова непригодны для языка. Умрешь от тоски, дожидаясь окончания слова, или забудешь его начало. Да в этом удлинении и нет необходимости. В самом деле, из алфавита в 32 буквы мы можем образовать 32 однобуквенных слова, некоторые из них используются: Я, А? О! У!; двухбуквенных 1024 = 322 (типа мы, вы, да, ты, ба, фи), трехбуквенных 32768 = 323; четырехбуквенных 1048576 = 324 и т. д. Следовательно, мы вполне могли бы ограничить длину слов четырьмя буквами для составления всех 50 тысяч слов.
Средняя длина слова в нашем языке составляет, однако, около семи букв. Значит, четырехбуквенный язык был бы приблизительно в два раза "короче". И это не так мало: речи ораторов, даже самых нудных, были бы в два раза короче, учебники стали бы в два раза тоньше, расход бумаги в государстве в два раза меньше. Но... Разберем это очередное "но".
Используя все или почти* все возможные комбинации для составления слов, мы лишаем слова избыточности, лишаем запасов, лишаем их живучести.
В самом деле, если учесть максимальную длину используемых слов, то общее их число, которое можно при этом составить, превысит используемое более чем в 100 тысяч раз! Вот какую колоссальную избыточность заложила природа в язык людей, нащупав ее без всякой теории, простым перебором вариантов и отбрасыванием непригодных.
Составляя телеграммы, мы выбрасываем предлоги, союзы и даже некоторые слова из полного текста, зная, что адресат сам легко их восстановит. Это удается сделать только благодаря тому, что слова в тексте не независимы (как было бы при отсутствии избыточности), а между ними существуют вероятностные связи, определяемые статистической структурой языка. Эти связи, пусть подсознательно, нам известны, и мы ими пользуемся.
Более того, аналогичные связи есть и между буквами в словах. Например, если первая буква слова "ч", то из гласных за ней не могут следовать "ы" или "я", а из согласных "с", "ц", "ф" и т. п. Весьма вероятна буква "т". Если первые две буквы "чт", то весьма вероятно, что третья буква будет "о" (что). Но может быть и "е" (чтение) и "и" (чтица). Маловероятна третья буква "у", гак как образует редкие и "немодные" слова (чту, чтут).
Такие связи могут быть только при наличии избыточности и позволяют нам во многих случаях восстанавливать искаженные помехами, неисправностью аппаратуры небрежностью работы операторов слова в телеграммах.
Но не только в телеграммах используется избыточность. Она верно служит человеку на каждом шагу.
Если бы мы жили в идеальном сказочном мире без, всяких помех и шумов, без дефектов речи, слуха и зрения, если бы нам удавалось всегда предельно четко и точно выражать свои мысли, если бы... то, возможно, мы могли бы обходиться без избыточности в языке. Но даже в этом сказочном мире нам было бы не так уж легко жить: безызбыточный язык требовал бы напряженной концентрации внимания при восприятии информации.
Некоторые милые женщины ухитряются готовить вкуснейшие блюда, непрерывно ведя активный разговор по телефону (при этом обе руки заняты приготовлением пищи, а трубка таинственным способом удерживается в районе уха). Такое совмещение деятельности, конечно, немыслимо при отсутствии избыточности, а может, и сверхизбыточности в нашем языке.
Эта же избыточность позволяет понимать чужой почерк при почти полной неразборчивости отдельных слов и букв, прочитывать стертые древнейшие манускрипты и даже составлять мини-шпаргалки.
Бывают случаи, когда с избыточностью языка все же приходится вести борьбу, например при передаче речи по каналам связи. Дело в том, что спектр человеческой речи, если передавать его со всеми оттенками и нюансами, занимает довольно широкую полосу частот - порядка 5 тысяч герц. Для экономии полосы частот и размещения большего числа каналов используют меньшую полосу - 3 тысячи герц: таков международный стандарт, которым мы ежедневно пользуемся, звоня по телефону. При этом мы теряем очень мало - несущественную окраску речи.
Но и это не предел. Если речевой сигнал подвергнуть сложной обработке, то удается уменьшить полосу его еще в 20-30 раз и передавать речь в канале с полосой порядка 100 герц. Устройство, осуществляющее такую обработку сигнала, называется вокодером. Как ни удивительно, при этом еще не полностью теряется индивидуальная окраска, и по голосу можно узнать собеседника.
Наконец, если воспользоваться предельными оценками емкости канала связи по формуле К. Шеннона, которую мы разбирали, то получим совсем удивительный результат: информация, содержащаяся в речевом сигнале, принципиально может быть "упакована" в полосу порядка нескольких герц. Для этого надо полностью избавить ее от избыточности. Пути приближения к этому пределу, по-видимому, будут найдены.
Вспоминаю, как несколько лет назад в Москве предполагалось открытие конференции по изгнанию избыточности из речевых, телевизионных и других сигналов.
А в это время в Ленинграде стартовал симпозиум по введению избыточности в сигналы для повышения помехоустойчивости. Перед специалистами встала серьезная дилемма: куда податься, что важнее? И каждый решал не по-своему, то есть в зависимости от вида избыточности, которой он занимался. Наибольшие муки испытывали те исследователи, которые избыточность и вводили и изгоняли.
Идеи теории информации, связанные с количественной оценкой информации в языке, с изучением статистики языка, стремительно ворвались в лингвистику. До этого она была чисто описательной наукой, ничего не измерявшей. Теперь же возникла новая математическая дисциплина - математическая лингвистика. Эта интереснейшая наука в последние. годы привлекает к себе все большее внимание молодых пытливых умов. В течение нескольких лет в МГУ наибольшее число абитуриентов стремится именно на факультет этой специальности.
Оказалось, что каждый язык имеет свои закономерности, которые можно записать с помощью формул, а грамматические правила, так трудно заучиваемые в школе, переложить на язык математики. В таком виде им можно обучить машину.
Но зачем все это? Просто ради любопытства? Отнюдь нет. Установив закономерности языка, можно моделировать на электронно-вычислительной машине и язык, и те операции, которые человек осуществляет над ним. Сюда входят: машинный перевод с одного языка на другой, разгадка древних письменностей, вскрытие связей между разными языками, создание читающих автоматов и т. д.
Более того, записав в машину правила языка и введя в ее память некоторый запас слов, можно научить ее писать стихи.
Вот один из образцов пока белых стихов, сочиненных машиной при запасе всего в 130 слов (имея значительно больший запас слов, иногда из кожи вон лезешь, чтобы составить поздравительный вирш).
Пока жизнь создает ошибочные, совершенно пустые образы, Пока время медленно течет мимо полезных дел, А звезды уныло кружат в небе, Люди не могут смеяться.
Эта машина пишет 150 подобных четверостиший в минуту. Названия к ним она еще не умеет сочинять, но зато четко их нумерует. Пока это упражнения, игра, но она принесет много "вкусных плодов" людям.
Выстукивая эти строчки на машинке, я узнал о печальном событии - умер поэт Ярослав Васильевич Сме-ляков. Сразу вспомнились самые любимые мною строчки из его стихов-песен:
...постелите мне степь, занавесьте мне окна туманом, в изголовье поставьте упавшую с неба звезду.
Да, так никогда не напишут машины!
|
ПОИСК:
|
При использовании материалов сайта активная ссылка обязательна:
http://informaticslib.ru/ 'Библиотека по информатике'