Приложение
Программа изменения длины строк текста (пример использования записей с вариантами)
Задача. Составить программу, вводящую текстовую информацию со строками длиной до 80 символов и выдающую этот же текст со строками длиной до 60 символов (без разбиения слов при переносе).
В тексте могут присутствовать пустые строки; абзац начинается с нескольких пробелов. Абзацем будем считать любую непустую строку, имеющую три и более пробелов в начале. Конец всего текста пусть будет отмечен специальным символом EOT, конец строки - символом EOL.
Тогда любой текст можно представить в виде последовательности эле'*- ментов: слов, знаков препинания и сим волов EOL и EOT. Все элементы разделяются пробелами. Простейшая схема программы приводится на рис. 12.
Напомним, что слова не разбиваются для переноса: если слово умещается, оно записывается в данную выходную строку; если не умещается, то слово целиком записывается в следующую строку OUTPUT. Элемент "слово" и элемент "знак" неравнозначны: знак обязательно должен стоять в той же строке, что и слово, за которым он поставлен, а последовательные слова можно писать в разных строках.
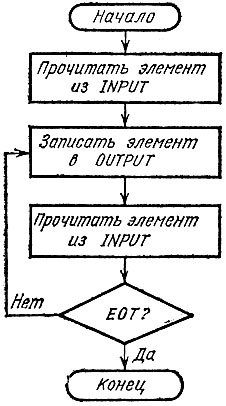
Рис. 12
Поэтому программа после ввода каждого элемента должна ввести еще один элемент и только после его анализа обрабатывать предыдущий (оставлять на текущей строке либо переносить на следующую).
Усложненная схема программы, имя которой INOUT, приводится на рис. 13.
Пусть чтение элемента выполняется процедурой RNEXT и запись - процедурой WTHIS.
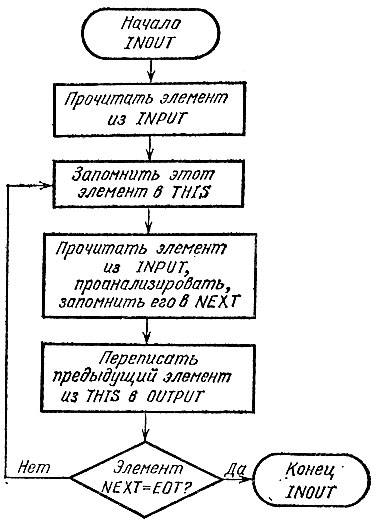
Рис. 13
Если в исходном тексте есть абзац или пустая строка, то будем считать, что в соответствующем месте текста есть некоторый элемент, играющий роль управляющего символа (CONTR).
Тогда весь текст можно себе представить состоящим из следующих элементов: слов (WORD), знаков препинания (PUNCT), управляющих символов (CONTR) и признака "конец текста" (EOT).
Будем считать, что слово состоит не более чем из 16 символов.
В этих предположениях произвольный элемент (ITEM) текста описывается как запись с вариантами:

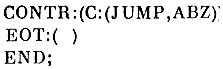
Если текущий элемент есть "слово" (WORD), то задается его длина L и массив SP на 16 символов, где размещаются буквы этого слова j если элемент - "знак" (PUNCT), то в Р находится соответствующий символ; если элемент - "управляющий символ" (CONTR), то в С находится признак "пустая строка" (JUMP) либо "абзац" (ABZ), Символ "конец текста" (EOT) служит только признаком конца я в выходной текст не попадает.
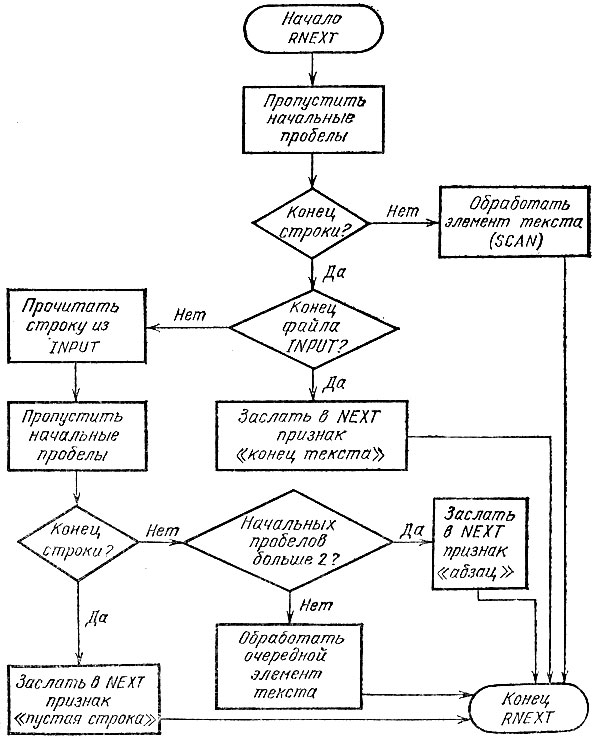
Рис. 14
Введем две переменные THIS и NEXT для хранения элемента текста
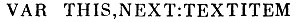
Процедура RNEXT должна прочитать символы, составляющие следующий элемент входного текста, проанализировать и поместить информацию в переменную NEXT, т. е. заполнить соответствующее поле записи типа TEXTITEM для переменной NEXT.
Удобнее вводить из INPUT не по одному элементу текста, а по целой строке. Для этого заведем массив LINE длиной от 1 до IN МАХ символов по числу символов во входной строке:
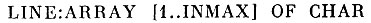
В нашем конкретном случае входная строка содержит до 80 символов. Для упрощения алгоритма программы будем отмечать конец входной строки каким-либо специальным символом, например "!". Этот символ поместим в LINE после последнего отличного от пробела символа введенной строки. Таким образом, длина массива LINE должна быть на 1 больше длины входной строки, т. е. для входной строки в 80 символов INMAX=81.
Элементы строки процедура выбирает из массива LINE. Схема RNEXT приводится на рис. 14.
Задачу "обработать элемент текста" можно оформить в виде процедуры SCAN (рис. 15).
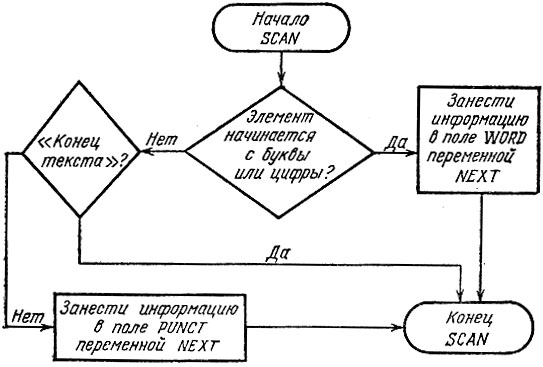
Рис. 15
На последнем этапе работы программы потребуется формировать выходные строки текста в файле OUTPUT. Запись элемента текста в выходную строку можно осуществить следующей процедурой WTHIS (рис. 16).
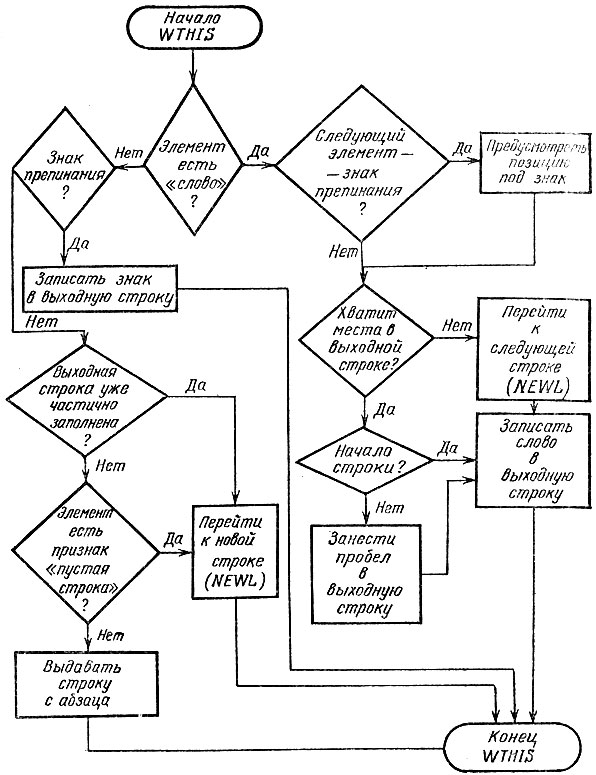
Рис. 16
Приведем полный текст программы. Здесь INMAX - максимальная длина входной строки плюс единица; OUTMAX - максимальная длина выходной строки;
EOT - признак конца текста;
EOL - признак конца строки;
LLINE - длина текущей входной строки;
THIS - предыдущий элемент текста;
NEXT - последующий элемент текста;
LiiNE - массив для хранения входной строки;?
POS - номер текущей позиции в строке;
FREE - количество оставшихся свободных позиций в строке; К - номер символа в слове;
SP - массив для хранения слова;
SPACE - число позиций, требуемое под очередное слово в выходной строке.




|
ПОИСК:
|
При использовании материалов сайта активная ссылка обязательна:
http://informaticslib.ru/ 'Библиотека по информатике'