4. Общий порядок решения задачи на ЭВМ
Рассмотренные выше алгоритм, алгоритмический язык, программа - это хотя и главные, но только от-дельные части всего процесса решения задачи с по-мощью ЭВМ. В школьном учебнике по информатике и вычислительной технике хорошо представлены основные этапы решения математической задачи с использованием ЭВМ.
Несколько детализируем эти этапы и покажем, что задачи всех наук (физики, математики, филологии, истории и т. п.) можно решить с помощью ЭВМ, выполняя одну и ту же нижеследующую последовательность действий.
- Сформулировать условие задачи на естественном языке (русском, белорусском, английском и т. п.). Рассмотрим две задачи (математическую и филологическую) : а) перемножить однозначное и трехзначное числа и напечатать результат их перемножения; б) взять последовательно три русских глагола, путем анализа двух последних букв* выделить среди них инфинитивные формы и напечатать результат анализа.
- Читая условие задачи, выделить участвующие в ее решении переменные величины и дать им имена.
* (Предполагается, что автор задачи знает сформулированное выше лингвистическое правило: глагол является инфинитивом, если он оканчивается на -ть, -чь, -ти.)
Переменные величины - это такие величины, значения которых меняются в процессе решения задачи.
Очевидно, что для первой задачи переменными величинами будут: "однозначное число" (эта величина может принимать значения 0, 1, 2, ... , 9), "трехзначное число" (это могут быть 100, 101, 755, ... , 999), "результат перемножения этих чисел" (эта величина является переменной, так как ее значение зависит от значений двух первых переменных величин).
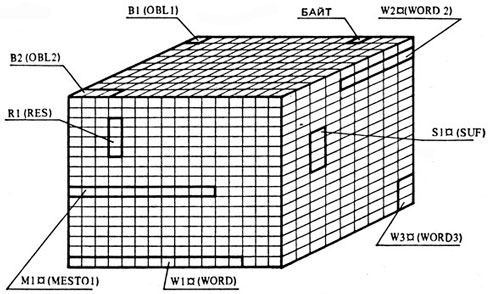
Рис. 5
Несколько сложнее выделить переменные величины второй задачи. Естественно, что прежде всего ими здесь будут: "первый анализируемый глагол", "второй анализируемый глагол", "третий анализируемый глагол". Они являются переменными потому, что мы можем в качестве глаголов взять любые русские глаголы (ХОДИТЬ, ПЕЛ, СТОЮ, УЧУСЬ и т. д.). По аналогии со сказанным переменной будет и величина "две последние буквы глагола", так как в качестве таких букв могут быть: -ть, -чь, -ти, -ел, -сь и т. д. Наконец, рассмотрим начало первой фразы условия второй задачи: "Взять последовательно три русских глагола". Как понимать слово "взять"? Человек может мысленно взять написанное на бумаге первое слово, затем второе и т. д. Если задача решается с помощью ЭВМ, то, чтобы она могла "взять" слово, она должна его "запомнить", расположить в некоторой области своей памяти. Поэтому при решении нашей второй задачи вводится некоторая новая переменная величина "место для очередного анализируемого глагола". В эту новую переменную и будут по очереди передаваться для анализа три отобранных глагола.
Для чего же всем этим и им подобным переменным надо давать имена? Чтобы это выяснить, рассмотрим устройство внутренней (оперативной) памяти ЭВМ. Условно ее можно представить в виде куба, разделенного на мельчайшие частички - байты (рис. 5). Байты определенным образом пронумерованы. Чтобы решить какую-то задачу, необходимо все переменные этой задачи предварительно разместить во внутренней памяти ЭВМ. Иными словами, во внутренней памяти ЭВМ необходимо выделить "квартиры" (определенные области памяти) для переменных каждой из решаемых задач: "однозначное число", "трехзначное число", "результат перемножения этих чисел" (первая наша задача), "первый анализируемый глагол", "второй анализируемый глагол", "третий анализируемый глагол", "две последние буквы глагола", "место для очередного анализируемого глагола" (вторая наша задача). Если при распределении реальных квартир жильцам указывается название улицы, номер дома и номер квартиры, то области памяти также должны быть как-то обозначены, поименованы. Такое задание имен областям памяти осуществляется по-разному*. Например, в первых версиях (вариантах) машинного языка БЕЙСИК для этих целей используются: латинские буквы А, В, ..., Z, латинские буквы с одной из десятичных цифр 0,1, ..., 9 или латинские буквы, одна из десятичных цифр и знак 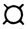 (последний знак используется для наименования переменных, содержащих текст). Таким образом, имена переменных могут включать в языке БЕЙСИК максимально три знака**: А, X, А2, Х4, Z9, A4
(последний знак используется для наименования переменных, содержащих текст). Таким образом, имена переменных могут включать в языке БЕЙСИК максимально три знака**: А, X, А2, Х4, Z9, A4 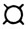 , У9
, У9
и т. п. В машинном языке ПЛ/1 имя переменной может содержать до 44 знаков и включает латинские буквы и десятичные цифры: DOK, XI4, OBL1, TEXT, ТЕХТ96 и т. п. Все подобные имена даются произвольно. На рисунке 5 показано возможное распределение памяти для упомянутых выше двух задач в соответствии с требованиями языков БЕЙСИК и ПЛ/1. Пусть назначение этих переменных таково***:
область В1 (OBL1) предназначена для размещения однозначного числа (например, числа 2);
область В2 (OBL2) должна вместить любое трехзначное число (например, число 550);
область Rl (RES) служит для размещения результата перемножения однозначного и трехзначного чисел: в области WlQ (WORD1) разместим первый исходный глагол;
в области W2Q (WORD2) будем хранить второй исходный глагол;
область W3Q (WORD3) отведем для третьего русского глагола;
в области S1& (SUF) будем хранить две последние буквы, выделяемые у глаголов;
область M1J3 (MEST01) предназначим для переменной "место для очередного анализируемого глагола".
* (Здесь и далее приводятся данные об использовании языков БЕЙСИК и ПЛ/1. БЕЙСИК является основным машинным языком для школьных микро-ЭВМ. На языке ПЛ/1 сейчас созданы и работают большинство программ по переработке текстов - программы машинного перевода, автоматического реферирования, аннотирования, поиска, порождения текстов и т. п.)
** (Последние версии языка БЕЙСИК допускают и большее число знаков в имени переменной. См.: Основы информатики и вычислительной техники: Проб. учеб. пособие для средн. учеб. заведений: В 2ч/ А. П. Ершов, В. М. Монахов, А. А. Кузнецов и др.; Под ред. А. П. Ершова, В. М. Монахова.- М.: Просвещение, 1986. Ч. 2.- С. 70-76; Пул Л. Работа на персональном компьютере.- М.: Наука, 1986.- С. 139-162.)
*** (Без скобок указаны имена переменных в языке БЕЙСИК. В скобках- имена тех же переменных в языке ПЛ/1.)
Конкретные количества байтов для каждой переменной и участки таких байтов для выделенных областей памяти распределяет автоматически сама ЭВМ. Это зависит, в частности, от результата выполнения следующего, третьего шага перечисляемых действий.
3. Определить пределы изменения выделенных переменных*.
* (При выполнении этого шага будем использовать имена переменных, взятые по правилам языка ПЛ/1. Все сказанное ниже справедливо и по отношению к именам, построенным по правилам любого другого машинного языка.)
Как можно было заметить, в процессе выполнения второго (предыдущего) шага мы не определяли размер выделяемых "квартир" (областей памяти). Мы не определяли, из какого количества байтов будет состоять область OBL1, сколько байтов должно быть в области RES для результата перемножения и т. п. Чтобы это сделать, необходимо договориться (определить из каких-то условий) о тех пределах, в которых будут изменяться выделенные переменные. Рассмотрим, как это делается на примере двух наших задач.
В задаче перемножения однозначного и трехзначного целых чисел уже сами слова "однозначный" и "трехзначный" говорят о том, сколько байтов будет в зонах памяти OBL1 и OBL2, предназначенных для хранения этих чисел. Соответственно будем иметь в зоне OBL1 - один байт, а в зоне OBL2 - три байта.
Итак, в области OBL1 может быть размещена любая цифра от 0 (минимальное значение) до 9 (максимальное значение). Диапазон чисел, которые может содержать область OBL2, гораздо шире - от 0 (минимальное значение: там, где сможет разместиться 3 знака, без сомнения, разместится и один знак) до 999 (максимальное трехзначное число). Далее следует найти минимальное и максимальное значение произведения однозначного и трехзначного чисел.
Минимальное значение произведения определится путем перемножения минимальных значений сомножителей:
Максимальное - аналогично, путем перемножения максимальных значений сомножителей:
Таким образом, область RES для результата перемножения однозначного и трехзначного чисел будет содержать в себе числа от 0 до 8991, т. е. ей надо отвести максимум 4 знака (ибо в числе 8991 4 цифры).
Для определения пределов изменения переменных, выделенных во второй задаче, можно использовать два приема.
Во-первых, конкретно задать три глагола, которые будут анализироваться. Например, пусть инфинитивная форма будет выделяться среди глаголов УЧИЛАСЬ, ХОДИТЬ, ПЕЛ. Тогда ясно, что области памяти WORD1, в которой будет храниться переменная "первый анализируемый глагол", необходимо дать 7 байтов (так как в слове УЧИЛАСЬ 7 букв). Аналогично области памяти WORD2 и WORD3 получат соответственно 6 байтов и 3 байта. Область памяти с именем SUF по-лучит 2 байта, так как в ней всегда будут размещаться переменная "две последние буквы глагола". В соответствии со сказанным выше в область памяти MEST01 будут по очереди передаваться все три анализируемые глагола. Значит, эта область должна "вместить" любой из выбранных для анализа глаголов. Поэтому ее "размер" берется равным длине самого большого из трех взятых слов, т. е. 7 байтам. Для возможности проведения различных действий с буквами области MEST01 дают на 1 байт больше, т. е. 8 байтов.
Однако описанный подход не позволяет построить универсальную программу анализа любых русских глаголов. Ведь в соответствии со сказанным в качестве первого анализируемого глагола может быть глагол, содержащий не более 7 букв, в качестве второго - не более 6 букв и в качестве третьего - не более 3 букв. Это, во-первых, не позволяет анализировать глаголы, состоящие более чем из 7 букв, а, во-вторых, требует проверки каждого глагола, который мы должны задать ЭВМ, на наличие в нем определенного числа букв, чтобы разместить такой глагол в одной из областей WORD1, WORD2 или WORD3.
При решении филологических задач к проблеме распределения памяти, т. е. задании переменным необходимого числа байтов, подходят иначе. Обычно исходят из предположения, что программа должна уметь анализировать любой русский глагол, т. е. в областях памяти WORD1, WORD2 и WORD3 может со-держаться любой глагол. Но ЭВМ требует конкретизации слова "любой". Она должна знать, какое максимальное число букв будет в таком "любом" глаголе. Привлекая свои филологические знания или просматривая словари, находят русский глагол, который имеет в своем составе наибольшее количество букв. Пусть такой глагол содержит 25 букв. Тогда областям памяти WORD1, WORD2 и WORD3 мы должны дать по 25 байтов (помня, что в каждой из них может разместиться любой русский глагол). Области памяти MEST01 дадим 26 байтов (так как один дополнительный байт нужен для проведения анализа буквенного состава глагола). Области памяти SUF, как и ранее, дадим 2 байта.
4. Дать атрибуты (описатели) всем выделенным переменным.
Все, что сделано в предыдущем пункте, понятно лишь человеку, который знает, что такое "число", "цифра", "буква", "слово", "суффикс". Поэтому выводы, полученные на предыдущем шаге, должны быть переведены на какой-либо язык для ЭВМ, именно на тот язык, на котором будет решаться задача на машине.
Это делается путем описания каждого имени с помощью специальных атрибутов. Такое описание отличается для разных языков общения с ЭВМ.
Например, в языке ПЛ/1 для описания переменных используются два типа атрибутов: атрибут способа представления и атрибут разрядности.
Первый из них описывает то, что хранит область памяти, имеющая определенное имя (например, RES, SUF и т. п.): числа или текст. Если в этой области памяти хранится число, то атрибут способа представления записывается в виде двух английских слов:
DECIMAL FIXED
Если же в области памяти хранится текст (буква, слово, предложение и т. д.), то для характеристики этой зоны используется атрибут CHARACTER. Атрибут разрядности указывает, сколько цифр (или букв) содержится в числе (или слове). Он выражается обычным десятичным числом.
Заданию какому-то имени атрибутов предшествует слово DECLARE - "объявляю", после которого ставятся последовательно имя переменной, атрибут способа представления, атрибут разрядности и знак ";" ("точка с запятой") как конец описания конкретной переменной.
Выделенные нами ранее переменные в языке ПЛ/1 получат следующие атрибуты*.
* (В языке ПЛ/1 разрешаются следующие сокращения: вместо слова DECLARE - DEC, вместо CHARATER - CHAR, вместо DECLARE - DCL. )
Для первой задачи:
DECLARE OBL1 DECIMAL FIXED (1); DECLARE OBL2 DECIMAL FIXED (3); DECLARE RES DECIMAL FIXED (4)*;
* (Если бы, например, результат перемножения получался в виде дробного числа типа 8991,127. то область RES для такого числа была бы объявлена так: DECLARE RES DECIMAL FIXED (7, 3); Первая цифра (7) здесь указывает общее число цифр в числе 8991,127, а вторая цифра (3) указывает, сколько цифр стоит после запятой.)
Для второй задачи:
DECLARE WORD 1 CHARACTER (25); DECLARE WORD2 CHARACTER (25); DECLARE WORD3 CHARACTER (25); DECLARE MESTOl CHARACTER (26); DECLARE SUF CHARACTER (2);
В языке БЕЙСИК атрибуты способа представления явно не указываются. Как мы уже отмечали выше, переменная, в которой содержится текст, в конце своего имени имеет знак "?}". Вслед за именем переменной обязательно указывается атрибут разрядности. Он задается с помощью слова DIM ("размерность"). Например, имена переменных для второй из рассматриваемых задач, представленные на рисунке 5, будут на языке БЕЙСИК описаны так:
DIM W1 (25), W2
(25), W2 (25), W3
(25), W3 (25), M1
(25), M1 (26), S1
(26), S1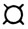 (2)
(2)
Переменные вместе с их атрибутами, полученными на этом шаге решения задачи, служат основой для написания первой части программы.
5. Написать первую (объявляющую) часть программы.
Условно каждую программу, написанную на каком- либо языке общения с ЭВМ, можно разделить на две части.
В первой части программы объявляется, с чем про-грамма будет иметь дело - с числами или текстом, перечисляются имена переменных с их атрибутами, сообщается программе целый ряд других данных.
Вторая часть программы (исполняющая) -это непосредственно часть, реализующая алгоритм решения задачи. В ней указывается, какие действия выполняются с теми переменными, которые описаны (объявлены) в первой части программы. Как правило, первая часть программы в разных языках общения с ЭВМ как- то выделяется. Например, в языке ПЛ/1 для этой цели указывается имя программы и стандартная фраза PROCEDURE OPTIONS (MAIN);. При этом имя программы должно содержать не более 6 знаков и обязательно начинаться с латинской буквы. Например, если программе перемножения однозначного и трехзначного чисел присвоить имя PROGR1, то первая часть этой программы будет такой*:
PROGR1: PROC OPTIONS (MAIN); DCL OBL1 DEC FIXED(l), OBL2 DEC FIXED (3), RES DEC FIXED (4);
Если второй нашей программе, программе выделения инфинитивной формы русского глагола, дать, на-пример, имя PROGR2, то ее начало будет таким:
PROGR2: PROC OPTIONS (MAIN); DCL WORD 1 CHAR (25), WORD2 CHAR (25), WORD3 CHAR (25), MESTOl CHAR (26), SUF CHAR (2);
* (Вместо слов PROCEDURE и DECLARE разрешается использовать соответственно сокращения PROC и DCL.)
В языке БЕЙСИК начало каждой программы за-дается словом NEW.
Программа перемножения однозначного и трехзначного чисел на языке БЕЙСИК начинается так*:
NEW 10 DIM В1 (1), В2(3), R1 (4)
* (Цифра 10 перед DIM показывает порядковый номер оператора. Его максимальное значение равно 9999.)
Первая часть программы задачи морфологического анализа слов на языке БЕЙСИК записывается в таком виде:
NEW 10 DIM W 10(25), W2U(25), W3H(25), Ml Q(26), 20DIM SlU(2)
6. Найти алгоритм решения задачи и представить его в виде блок-схемы.
Как уже отмечали выше, поиск алгоритма решения задачи является основным этапом решения с помощью ЭВМ любой задачи. Нет единых правил и принципов составления алгоритмов. Суть этой процедуры заключается в делении всего процесса решения на отдельные шаги, действия, которые потом можно было бы заменить командами (операторами) какого-либо языка общения с ЭВМ. При этом такие выделяемые действия в связи с принципом работы современных ЭВМ должны быть только двух типов.
1) Безусловные действия типа "Сделай то-то" (умножь, сложи, выдели, соедини и т. п.) и типа "Перейди туда-то" (к участку программы, имеющему имя KON, к оператору, имеющему номер 30, и т. д.).
2) Условные действия типа: а) если какое-то условие выполнено, сделай действие такое-то, если оно не выполнено, сделай действие другое; б) если какое-то условие выполнено, перейди к выполнению оператора такого-то, если оно не выполнено, перейди к выполнению оператора другого.
Рассмотрим детальнее алгоритмы решения двух рассматриваемых нами задач.
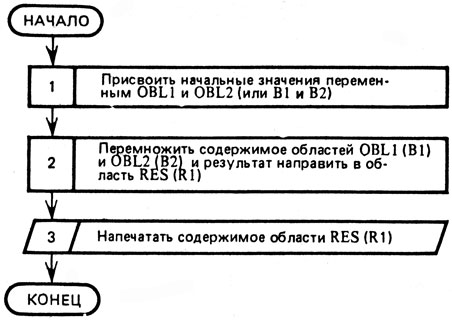
Рис. 6
Алгоритм задачи перемножения однозначного и трехзначного чисел может быть представлен так*, как показано на рисунке 6.
* (Напомним, что без скобок указаны имена переменных (областей памяти ЭВМ), объявленные на с. 28 на языке ПЛ/1. В скобках приведены имена тех же переменных в языке БЕЙСИК.)
На рисунке 4 приведен алгоритм задачи выделения из группы русских глаголов инфинитивной формы глагола. Условия нашей второй задачи требуют напечатать результат анализа глаголов и ограничивают группу глаголов тремя глаголами. Поэтому мы несколько уточним приведенный на рисунке 4 алгоритм и представим его так, как показано на рисунке 7. При большом числе глаголов блоки 10-14 строятся иначе.
7. Написать вторую (исполняющую) часть программы.
Суть этого шага или этапа решения задачи заключается в том, чтобы каждый блок алгоритма решения задачи заменить одним или несколькими операторами (командами) какого-либо языка общения с ЭВМ. Последовательность таких операторов, точно соответствующая алгоритму, и составит вторую часть программы, часть, которая непосредственно осуществляет какие-то действия с переменными, объявленными в первой части программы.
Естественно, что и первая, и вторая части программы должны быть написаны на одном и том же языке общения с ЭВМ.
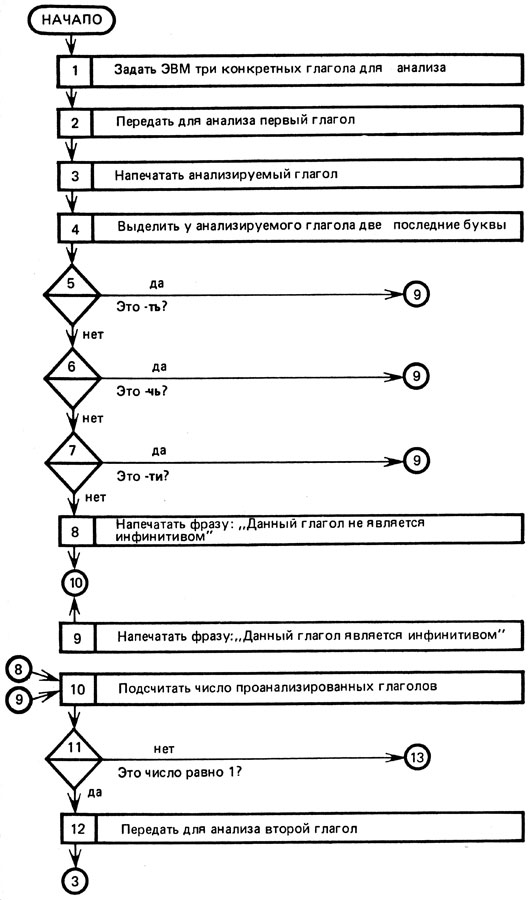
Рис. 7
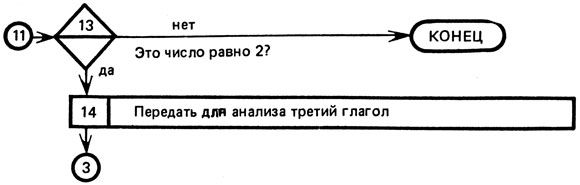
Рис. 7
Продемонстрируем процесс написания второй части программы на примерах двух алгоритмов, приведенных на рисунках 6 и 7.
Напишем вторую часть программы для перемножения однозначного и трехзначного чисел (например, 2 и 550) на языке БЕЙСИК (см. Приложение 1). Чтобы теснее увязать алгоритм (рис. 6) с программой, выделим в процессе написания программы на листе бумаги четыре части (табл. 1): номера блоков алгоритма, номера операторов (команд), операторы (команды) языка БЕЙСИК и пояснения.
В таблице 2 записан тот же алгоритм на языке ПЛ/1 (см. Приложение 2). Напомним, что первая часть этой программы приведена на с. 28.

Таблица 1
* (В языке БЕЙСИК все операторы нумеруются числами от 1 до 9999. Номера можно брать и не подряд, а через определенный интервал, например 10, 20, 30 и т. д. )

Таблица 2
Рассмотрим более сложный алгоритм выделения инфинитивной формы русского глагола (рис. 7). Заменяя каждый его блок соответствующими операторами языка БЕЙСИК, получим вторую часть этой программы (табл. 3). Так как каждая программа, в отличие от алгоритма, имеет дело с конкретным обрабатываемым материалом, то мы должны задать ей три конкретных русских глагола. Пусть это будут слова УЧИТЬ, СТАРАЛСЯ, ПЕЛ. С такого задания упомянутая программа и начинает свою работу (см. операторы 20, 30 и 40 в табл. 3).

Таблица 3
Сделаем некоторые пояснения к этой программе.
Как видно из начала программы, блок 4 алгоритма анализа слова программируется с помощью двух операторов языка БЕЙСИК. По существу здесь решаются две задачи:
1) Оператор 70 находит в анализируемом слове конец слова (для этого используется специальная функция LEN). Порядковый номер последней буквы этого слова (начиная от начала слова) фиксируется в промежуточном счетчике с именем I.
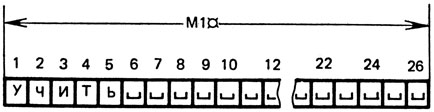
Рис. 8
2) Оператор 80, используя содержимое счетчика I, проводит действие по выделению из слова двух последних букв.
Пусть, например, для анализа в область памяти M1 поступило слово УЧИТЬ. В памяти ЭВМ оно будет выглядеть так*, как показано на рисунке 8 (цифрами пронумерованы байты области M1
поступило слово УЧИТЬ. В памяти ЭВМ оно будет выглядеть так*, как показано на рисунке 8 (цифрами пронумерованы байты области M1 ).
).
* (Знаком "-" здесь и далее обозначается знак "пробел".)
Оператор 70 фиксирует вначале номер последней буквы этого слова (1 = 5). Оператор 80 "забирает" у слова, находящегося в области M1 , начиная с позиции 1 - 1 (т. е. с позиции I - 1 = 5 - 1 = 4), две последние буквы -ть.
, начиная с позиции 1 - 1 (т. е. с позиции I - 1 = 5 - 1 = 4), две последние буквы -ть.
В программу введена также специальная переменная - счетчик К для подсчета числа проанализированных глаголов. Такие "промежуточные" переменные, как вышеупомянутые I и К, обычно заранее не объявляются. Имя этим переменным в языке БЕЙСИК дается произвольно. Действие других операторов этой программы легко понять из пояснений к ней (колонка 4 программы) .
Тот же алгоритм выделения инфинитивной формы глагола на языке ПЛ/1 будет выглядеть так, как показано в таблице 4. Надо помнить, что имена переменных здесь взяты из рисунка 5. Первая, объявляющая, часть этой программы приведена выше.
Сделаем некоторые пояснения к этой программе*. Здесь блок 4 алгоритма также программируется двумя операторами:
1 = INDEX (MEST01, "_"); SUF = SUBSTR (MESTOl, 1-2, 2);
* (В языке ПЛ/1 слово END, обозначающее конец работы программы, пишется вместе с именем этой программы. Имя это мы придумали выше при написании первой части программы)
Однако принцип их работы несколько иной, чем в программе на языке БЕЙСИК. Так, если в область памяти с именем MEST01 передан первый глагол УЧИТЬ (рис. 9), то в результате работы первого из двух приведенных выше операторов в рабочей переменной I окажется число 6 (место первого пробела после буквы -ь). Второй оператор выделяет у этого слова, начиная с позиции 4 (так как I - 2 = 6 - 2 = 4), две последние буквы -ть.
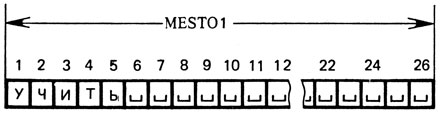
Рис. 9

Таблица 4
Счетчики I и К в этой программе имеют такое же назначение, что и в программе на языке БЕЙСИК. Однако имена таким "промежуточным" переменным даются не совсем произвольно - такое имя в языке ПЛ/1 обязательно должно начинаться на буквы I, J, К, L, М, N.
8. Написать управляющие операторы, связывающие всю написанную программу с операционной системой ЭВМ.
Две части программы (первая и вторая), написанные друг за другом, и составляют единую полную программу. Однако, на каком бы языке общения с ЭВМ эта программа ни была написана, она все равно ей непонятна. ЭВМ понимает язык единиц (1) и нулей (0). С чем бы ЭВМ ни имела дела, все это должно быть переведено в такой двоичный язык, который и является внутренним языком любой ЭВМ.
Чтобы перевести программу с какого-либо языка общения с ЭВМ во внутренний язык и выполнить ее, необходимо написанную программу:
1. Оттранслировать. 2. Отредактировать. 3. Непосредственно выполнить.
Все это осуществляют специальные операционные системы, которые продаются вместе с ЭВМ. Одна и та же ЭВМ иногда может использовать различные операционные системы.
Программа на языке БЕЙСИК, как правило, набирается непосредственно с клавиатуры дисплея. Для того чтобы такую программу оттранслировать, отредактировать и выполнить, в конце программы без номера ставится слово RUN.
Сложнее обстоит дело, когда используется какой- либо более сильный язык, например язык ПЛ/1. В таком случае для каждого из упомянутых трех действий (трансляция, редактирование и выполнение) используются специальные управляющие операторы. Например, если написанная выше на языке ПЛ/1 программа (см. табл. 5) выполняется в дисковой операционной системе (ДОС)*, то перед первой частью программы обязательно пишутся следующие управляющие операторы:
//JOB имя задания //OPTION LINK //UPSI 01 //EXEC PL/1
* (В машинах серии ЕС ЭВМ она может быть выполнена и в операционной системе (ОС).)
Первый из этих операторов дает задаче какое-либо индивидуальное имя ("имя задания"). Это имя не должно превышать 8 знаков и должно начинаться с латинской буквы.
Второй оператор приказывает машине выделить в памяти специальное место для последующего редактирования программы.
Третий оператор приказывает ЭВМ, в случае появления ошибок в процессе непосредственного выполнения программы, указать, в каком операторе обнаружена ошибка и причину этой ошибки.
Четвертый оператор приказывает машине вызвать системную программу ТРАНСЛЯТОР и начать трансляцию написанной программы, т. е. перевод ее во внутренний язык машины (в язык "1" и "О"). Сразу за этим оператором ставится первая часть программы.
В конце второй части программы обязательно ставятся следующие управляющие операторы:
I* // EXEC LNKEDT //ЕХЕС I* /&
Первый оператор /* называется оператором конца программы.
Второй оператор приказывает машине начать редактирование оттранслированной ранее программы. При этом отдельные части программы на внутреннем языке машины объединяются в единое целое.
Третий оператор приказывает ЭВМ начать непосредственное выполнение оттранслированной и отредактированной программы с теми исходными данными (числами или текстом), которые ставятся сразу за этим оператором //ЕХЕС.
Следующий оператор /* называют "конец данных".
И наконец, последний оператор /& называется "концом задания".
9. Написать программу и управляющие операторы на специальные бланки.
Этот шаг заключается в том, что на специальных бланках последовательно пишутся управляющие операторы, первая и вторая части программы и оставшаяся часть управляющих операторов.
На с. 40 приводится пример записи на бланке языка БЕЙСИК программы выделения инфинитивной формы из трех русских глаголов.
10. Отперфорировать программу вместе с управляющими операторами с бланков на перфокарты.
Программа вместе с управляющими операторами должна быть с бланков каким-нибудь образом передана во внутреннюю память машины. Это можно сделать либо с помощью клавиатуры дисплея, либо закодировав программу на перфокарты, перфоленты, магнитные ленты или магнитные диски. Первый путь используется, как правило, для микро-ЭВМ, а также для небольших программ в других типах электронных машин. Сложные программы обычно перфорируются на внешние носители информации. Для определенности программа и управляющие операторы нашей задачи закодированы на перфокарты.

11. Выявить синтаксические и другие ошибки программы.
Во время написания программы, ее перенесения на бланки и на перфокарты могли быть сделаны раз-личные синтаксические ошибки (например, не поставлен пробел между двумя ключевыми словами оператора, пропущена скобка или запятая и т. д.). Все эти ошибки выявляются во время трансляции программы. Для этого колода перфокарт с программой и управляющими операторами устанавливается на устройство ввода ЭВМ, которое приводится в действие. В итоге на бумажной ленте АЦПУ (алфавитно-цифрового печатающего устройства) появляется вся программа с указанием всех обнаруженных в ней синтаксических ошибок. При этом также указывается номер оператора, в котором обнаружена ошибка, и суть этой ошибки.
12. Исправить в колоде перфокарт с программой все обнаруженные синтаксические ошибки.
Этот шаг выполняется путем внесения в колоду перфокарт с программой вместо перфокарт с ошибками верных перфокарт, полученных путем исправления на устройствах подготовки данных обнаруженных ошибок.
13. Выявить логические, лингвистические и другие типы ошибок, допущенных в процессе создания алгоритма и написания программы.
Эти типы ошибок выявляются на двух шагах реализации программы - редактировании и непосредственном выполнении программы. Чтобы обнаружить ошибки этих типов, необходимо установить на устройство ввода исправленную колоду перфокарт с управляющими операторами и обрабатываемыми данными (это могут быть или числа, или обрабатываемый текст) и пустить в действие это устройство ввода. При этом, если в программе есть ошибки указанных типов, на бумаге АЦПУ будут указаны номера операторов, в которых обнаружены эти ошибки, и причины появления этих ошибок.
Но чаще всего логические, лингвистические и другие ошибки находятся человеком, автором программы, в результате тщательного анализа выданных ЭВМ итогов решения задачи.
Например, если была написана программа перевода на русский язык английских предложений, то в результате реализации этого этапа решения задачи для каждого английского предложения будет получен русский перевод. Просматривая эти переводные предложения, можно обнаружить, например, не переведенное английское слово. Это может быть в трех случаях:
1) в англо-русском словаре, вложенном в машину (см. с. 78) нет соответствующего английского слова;
2) в переводимом английском предложении это слово "написано" с ошибкой; 3) в англо-русском словаре это английское слово есть, но оно там "написано" с ошибкой.
В другом русском предложении, полученном в качестве переводного эквивалента, например, неверно согласовано подлежащее и сказуемое (типа "оператор включило"). Здесь возможны такие причины:
1) в информации к слову ОПЕРАТОР в русской части словаря вместо мужского рода ошибочно поставлен средний род;
2) в таблице формообразования глагола ВКЛЮЧАТЬ (см. с. 78) для прошедшего времени единственного числа мужского рода в конце слова вместо -л ошибочно поставлено -ло.
Таким же образом анализируются все другие переведенные предложения и находятся возможные причины ошибок. Затем, просматривая внимательно англо-русский словарь и обрабатываемый текст, находят истинную причину ошибок.
Иногда в процессе такого анализа оказывается, что необходимо перестроить алгоритм выполняемых действий, что какое-то одно действие обязательно должно быть выполнено ранее другого и т. п.
14. На основании результатов предыдущего анализа внести исправления в алгоритм, программу, исходные данные и обрабатываемые данные.
В итоге тщательного анализа полученных на предыдущем шаге результатов решения задачи будут выявлены причины логических, лингвистических и других ошибок. Логические ошибки, как правило, требуют изменений в алгоритме, а затем и в программе (в соответствии с исправленным алгоритмом должна быть заново написана вторая часть программы). Лингвистические ошибки требуют исправлений в программе и исходных данных (например, англо-русском словаре). Орфографические ошибки также требуют исправлений в программе, исходных данных и в обрабатываемом материале (например, английском тексте).
Все эти ошибки исправляются путем внесения в колоду перфокарт с программой, исходными данными и обрабатываемыми данными верных перфокарт вместо неверных. Исправления в программе могут быть сделаны и с экрана дисплея.
15. Получить окончательный результат решения задачи.
Для этого исправленная программа вместе с управляющими операторами и обрабатываемыми данными устанавливается на устройство ввода, и это устройство пускается в действие. На бумажной ленте АЦПУ при этом получается окончательный результат решения задачи.
Так описанный процесс решения задачи в основном верен лишь для задач научно-технических и экономических. Творческие задачи с текстом (перевод с иностранного языка, синтаксический, морфологический, семантический анализ, реферирование и аннотирование текстов, поиск текстов, составление текстов и т. п.) требуют многократного повторения действий 11 -14. Известно, что в любом языке гораздо больше исключений, чем правил. Поэтому, например, в рассмотрен-ной выше задаче перевода текстов с английского языка на русский приходится многократно повторять этапы 14 и 15, так как среди предложений, переводимых на ЭВМ, могут встретиться такие, которые не были проанализированы в процессе составления алгоритма. Значит, необходимо вносить новые исправления в алгоритм и т. д.
Рассмотрим теперь, пользуясь приведенной последовательностью действий, как машина "читает" слово и предложение из целого текста.
|
ПОИСК:
|
При использовании материалов сайта активная ссылка обязательна:
http://informaticslib.ru/ 'Библиотека по информатике'