5. Как машина "читает" слово
В компьютерной лингвистике четко различают такие понятия: 1) словоупотребление; 2) словоформа; 3) слово (лексема).
Словоупотреблением называется цепочка букв в тексте, находящаяся между двумя пробелами. В тексте, подготовленном для обработки на ЭВМ, все знаки препинания отделяются от слов пробелами. Значит, и они (точка, запятая и т. п.) считаются слово-употреблениями.
Словоформой называют полностью совпадающие текстовые словоупотребления (в число словоформ не входят знаки препинания).
Слово - это совокупность словоформ, выражающих одно и то же лексическое значение (но разное грамматическое)*.
Например в тексте:
СКОРО _ ПРИДЕТ _ ВЕСНА _ _ВЕСНА _ ЛУЧШЕЕ _ ВРЕМЯ _ ГОДА _ _ ПРИДЕТ _ ВЕСНА _ , _ И _ ЗАЗЕЛЕНЕЮТ _ ТРАВАМИ-ДЕРЕВЬЯ _ . _ ВЕСНОЙ _ ЛЕГЧЕ _ ДЫШИТСЯ _ _ ПРИХОДИ _, _ ВЕСНА _ ! _
* (Слова обычно записываются в канонической форме, т. е. существительное в единственном числе, именительном падеже; прилагательное в мужском роде, единственном числе, именительном падеже и т. д.)
27 словоупотреблений (из них текстовых - 19, знаковых- 8), 15 разных словоформ (причем, словоформа ВЕСНА повторяется 4 раза, словоформа И - 2 раза), 13 слов (словоформы ВЕСНА и ВЕСНОЙ относятся к одному слову ВЕСНА, словоформы ПРИДЕТ и ПРИХОДИ можно отнести к слову ПРИХОДИТЬ).
Учитывая сказанное, рассмотрим детальнее вопрос о том, как машина, "читает" словоупотребление.
Первоначально задача формулируется следующим образом: "Задан текст. Вводя в память машины по определенной порции текста, выделять поочередно все словоупотребления текста и направлять их в одно и то же место памяти. Считать общее число прочитанных словоупотреблений".
Анализируя условие этой задачи, выделяем в ней следующие переменные: "исходный текст", "порция текста", "место в памяти для отдельного словоупотребления", "счетчик числа прочитанных словоупотреблений", которым даем соответственно следующие имена*: TEXT(T1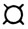 ), STROKA (S1
), STROKA (S1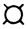 ), WORD(W1
), WORD(W1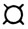 ), К (К).
), К (К).
* (Без скобок - на языке ПЛ/1, в скобках - на языке БЕЙСИК.)
Выясняя пределы изменения этих переменных, условимся, что "исходный текст" может содержать любое количество словоупотреблений (только в этом случае можно построить универсальный алгоритм). "Порция текста", в принципе, может содержать любое количество словоупотреблений. Но чаще всего ее принимают равной количеству знаков на перфокарте (80 знаков) или числу знаков в строке дисплея (60 знаков). Для задания "размера" переменной "место в памяти для отдельного словоупотребления" необходимо учитывать тип языка. Например, для немецкого и русского языков "размер" этой переменной должен быть больше (он принимается равным длине в буквах самого длинного немецкого или русского слова), а для английского и французского языков эта зона может быть короче. Для "счетчика числа прочитанных словоупотреблений" (как и вообще для всех "промежуточных переменных") отводится определенный размер, зависящий от типа используемого машинного языка.
После этого переменные с именами TEXT(T1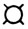 ), STROKA(S1
), STROKA(S1 ) и WORD(W1
) и WORD(W1 ) получают атрибуты на соответствующем машинном языке (в нашем случае - на ПЛ/1 или БЕЙСИК). Далее пишется первая (объявляющая) часть программы "Чтение слова" и начинается поиск алгоритма для чтения из текста любого слова.
) получают атрибуты на соответствующем машинном языке (в нашем случае - на ПЛ/1 или БЕЙСИК). Далее пишется первая (объявляющая) часть программы "Чтение слова" и начинается поиск алгоритма для чтения из текста любого слова.
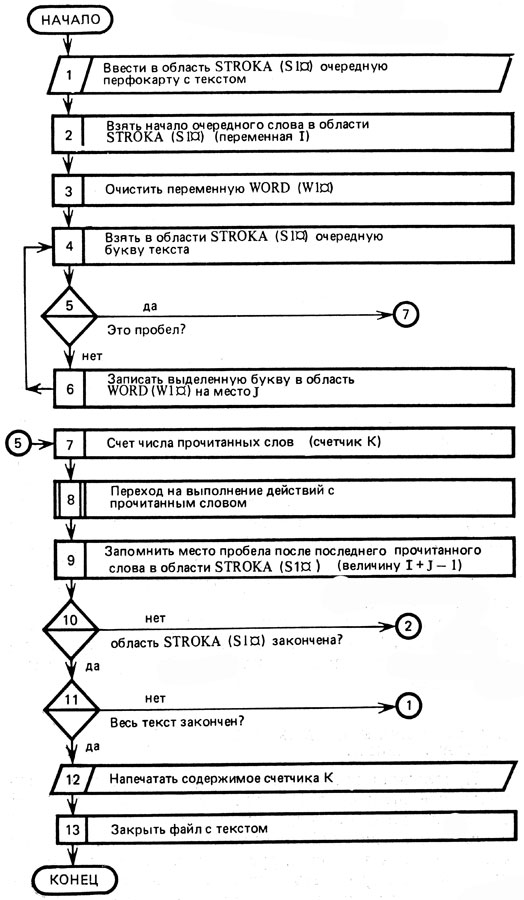
Рис. 10
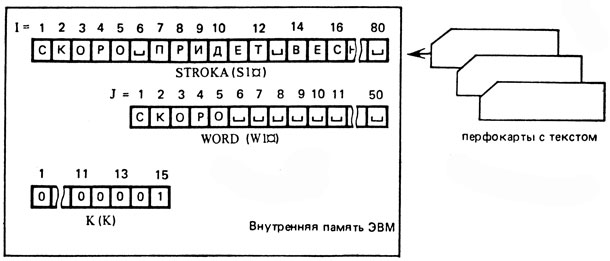
Рис. 11
В самом общем виде этот алгоритм может быть представлен в виде блок-схемы (рис. 10). Работу этого алгоритма легко понять, если ориентироваться на рисунок 11, показывающий размещение в памяти ЭВМ выделенных ранее переменных.
Промежуточная переменная I здесь показывает, с какого места переменной "порция текста" берется очередная буква, а промежуточная переменная J фиксирует, на какое место в переменную "вместо в памяти для отдельного словоупотребления" записывается эта выделенная буква текста. Как можно заметить из рисунка 11, описываемый алгоритм "читает" текст, приведенный выше.
Этот алгоритм затем программируется на языках ПЛ/1 или БЕЙСИК. Полученная программа составляет вторую (исполняющую) часть всей программы "Чтение слова".
|
ПОИСК:
|
При использовании материалов сайта активная ссылка обязательна:
http://informaticslib.ru/ 'Библиотека по информатике'