Раздел II. Применение ЭВМ в филологии
1. Построение с помощью ЭВМ частотных словарей
Частотным словарем называется пронумерованный список слов какого-либо текста (или множества текстов), при каждом из которых указана абсолютная частота (F) употребления этого слова во всем исследуемом тексте.
Такие словари могут быть составлены по иностранным текстам какой-либо научной предметной области (например, по геологии, физике, химии и т. п.). Верхняя часть таких словарей включает наиболее употребительные слова соответствующей предметной области. Эти слова могут стать основой лексических минимумов для изучения соответствующих иностранных текстов.
Частотные словари составляются по всем текстам отдельных авторов (например, составлены такие словари по произведениям А. С. Пушкина, С. Есенина) и по отдельным произведениям авторов (так, известны частотные словари по "Капитанской дочке" А. С. Пушкина, "Незнакомке" А. Блока). Такие словари дают возможность изучать стилистические особенности авторов в сравнении с другими авторами, а также позволяют проследить за эволюцией стилистических особенностей отдельных авторов в разные периоды их жизни.
Частотные словари являются также основой для создания машинных словарей, широко используемых при машинном переводе, автоматическом аннотировании, реферировании и поиске текстов.
Надежные выводы по словарям о лексике определенной предметной области, об авторских особенностях можно получить лишь в том случае, если соответствующий частотный словарь построен на текстах достаточно большой длины. Однако процедура построения частотных словарей очень трудоемка и однообразна. То, что человек делает в течение двух-трех лет, машина может сделать за один-два месяца (с учетом кодирования текстов на машинные носители информации).
Выше мы ввели различия между такими понятиями, как "словоупотребление", "словоформа" и "слово". Так как ЭВМ не может объединять различные словоформы одного слова в канонической (словарной) форме, то с помощью ЭВМ строят лишь частотные словари словоформ. Алгоритм построения такого частотного словаря может быть представлен так, как показано на рисунке 14. Такой алгоритм называется принципиальным алгоритмом в отличие от всех рассмотренных ранее детальных алгоритмов решения конкретных простых задач. В принципиальном алгоритме указываются не конкретные действия, заменяемые операторами какого-либо алгоритмического языка, а наименования и суть простых задач, входящих в состав какой-то сложной решаемой задачи. Как видно из рисунка 14, сложная задача построения частотного словаря состоит из пяти более простых задач (А, Б, В, Г, Д).
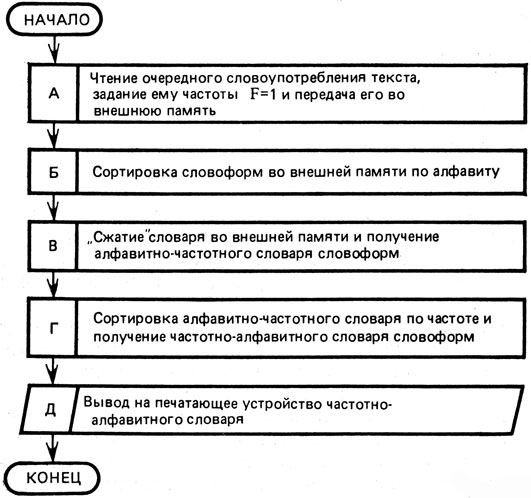
Рис. 14
Рассмотрим принцип решения этих отдельных задач на ЭВМ на конкретном примере. Пусть дан следующий текст, в котором отмеченные вертикальными линиями части текста составляют отдельные порции, вводимые в ЭВМ:
СКОРО ПРИДЕТ ВЕСНА _ _ ВЕСНА _-_ ЛУЧШЕЕ ВРЕМЯ ГОДА _ _ НАСТУПИТ ЭТО ВРЕМЯ._,_И_| ЗАЗЕЛЕНЕЮТ ТРАВА И ДЕРЕВЬЯ ._| ВЕСНОЙ БОЛЬШЕ СОЛНЦА И СВЕТА _ _ ВЕСНОЙ ЛЕГЧЕ ДЫШИТСЯ _ | _ ПРИХОДИ _,_ ВЕСНА _!
В основе блока А лежит рассмотренный ранее алгоритм "Чтение слова". В нем вместо блока 8 во вторую часть программы вставляются несколько новых операторов, в итоге выполнения которых каждое прочитанное в область WORD словоупотребление получит частоту F = 1 и оно вместе с частотой будет записано во внешнюю память (на магнитный диск или магнитную ленту). В результате выполнения этого блока для нашего текста во внешней памяти получим последовательность словоформ*, показанную в таблице 5. Все эти порции записаны во внешней памяти друг за другом.
* ( Рассматриваем только текстовые словоформы.)
С каждой ЭВМ продается целая библиотека стандартных программ, кем-то уже сделанных и проверенных. К числу их относится и программа "Сортировка". Эту программу использует блок Б, приказав ей расположить единый массив словоформ всех порций по алфавиту. В результате этого перечень словоформ во внешней памяти приводится к виду, показанному в таблице 6.
Как видно, этот перечень содержит одинаковые словоформы (ВЕСНА, ВЕСНОЙ, ВРЕМЯ, И). Чтобы сократить такой список, используют блок В принципиального алгоритма. Он суммирует частоты одинаковых словоформ и вместо многократного упоминания одной и той же словоформы записывает такую словоформу однажды, но с суммарной частотой (табл. 7).
Блок Г имеет в своей основе программу "Сортировка". Только теперь ЭВМ дается задание рассортировать список словоформ, полученных в блоке В, по частоте и по алфавиту. Это означает следующее: поставить на первое место в списке наших словоформ такую словоформу, которая имеет наибольшую частоту, на второе место - словоформу с частотой, на единицу меньшей, и т. д. Если несколько словоформ имеют одинаковую частоту, то они располагаются по алфавиту. В итоге работы блока Г во внешней памяти ЭВМ получается перечень словоформ, данный в таблице 8.

Таблица 5

Таблица 6

Таблица 7
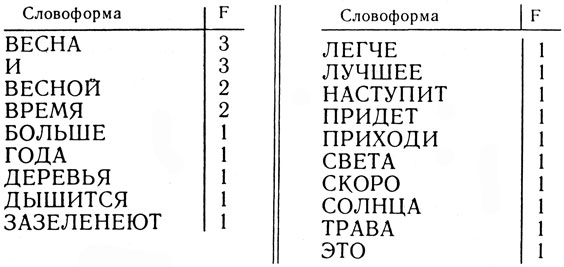
Таблица 8
И наконец, блок Д осуществляет вывод на бумагу (на печать) полученного списка словоформ. При этом каждой словоформе присваивается порядковый номер и, кроме абсолютной частоты, для каждой словоформы указывается относительная частота употребления (f), которая вычисляется по формуле f=F/N где F - абсолютная частота употребления конкретной словоформы, а N - общая длина текста в слово-употреблениях (она получится, если сложить все абсолютные частоты словоформ нашего списка, N = 25). В итоге получается частотно-алфавитный список словоформ или просто частотный словарь словоформ (табл. 9).
Аналогичным способом с помощью ЭВМ можно получить частотные списки n-буквенных сочетаний (2 буквенных, 3-буквенных и т. д.) и n-словных словосочетаний. Первые весьма полезны при изучении употребительности приставок, суффиксов, окончаний, при поиске рифмующихся слов. Частотные списки словосочетаний используются при отборе терминологических словосочетаний, фразеологизмов, при изучении окружений в текстах различных слов и групп слов.
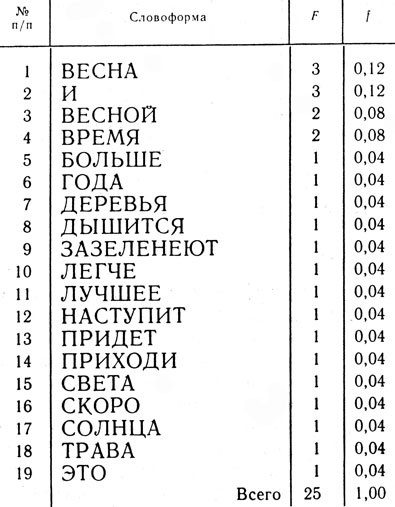
Таблица 9
|
ПОИСК:
|
При использовании материалов сайта активная ссылка обязательна:
http://informaticslib.ru/ 'Библиотека по информатике'