6. Как машина "читает" предложение связного текста
Предложения естественных языков могут содержать различное число слов. И если пытаться решать на ЭВМ такие сложные задачи, как распознавание значений слов, синтаксический анализ предложений, перевод с иностранных языков на русский и т. п., то необходимо научить машину читать в свою память любое предложение из текста независимо от того, какой номер оно занимает от начала, сколько в нем слов, какие предложения стояли до нужного предложения и после него.
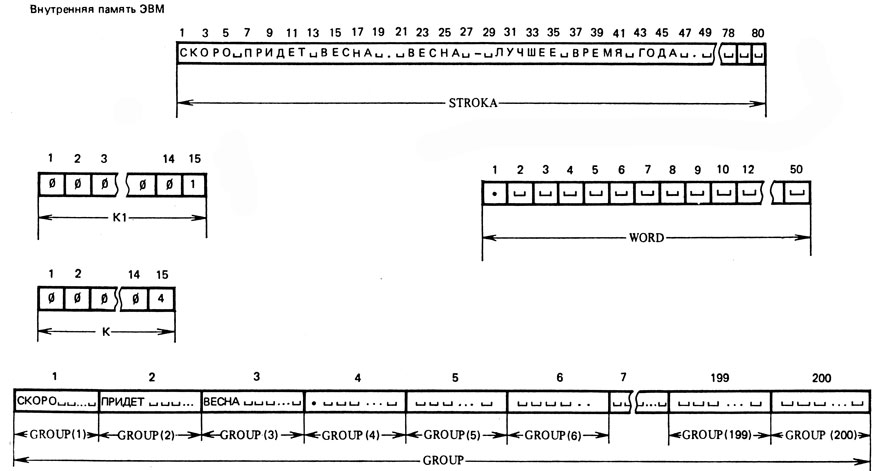
Рис. 12
Задача эта достаточно сложна и может быть решена двумя способами. Первый способ в основе алгоритма чтения предложения имеет алгоритм задачи "Чтение слова", рассмотренный выше. Для этого во внутренней памяти ЭВМ выделяется специальная область памяти с именем GROUP (имя дано произвольно), в которой и будет формироваться предложение. Вводится также промежуточная переменная К1, в которой будет подсчитываться количество прочитанных предложений. На рисунке 12 представлено распределение памяти ЭВМ для задачи "Чтение предложения" и результаты чтения 1-го из предложений текста СКОРО ПРИДЕТ ВЕС-НА-- ВЕСНА - ЛУЧШЕЕ ВРЕМЯ ГОДА , находящегося на перфокарте и введенного в область STROKA.
Суть алгоритма чтения предложения заключается в том, что, как только в область WORD прочитано очередное слово и подсчитан в счетчике К порядковый номер этого слова, прочитанное слово из области WORD передается в область GROUP на место К. Таким образом, первое слово будет передано в область GROUP (1), второе - в область GROUP (2) и т. д. При каждой такой передаче проверяется, передана ли в область GROUP точка. Если передана, то предложение считается прочитанным и в счетчик числа прочитанных предложений К1 прибавляется 1. После этого могут быть подключены любые программы работы с прочитанным предложением (например, программа синтаксического анализа предложения, программа перевода предложения на другой язык и т. д.).
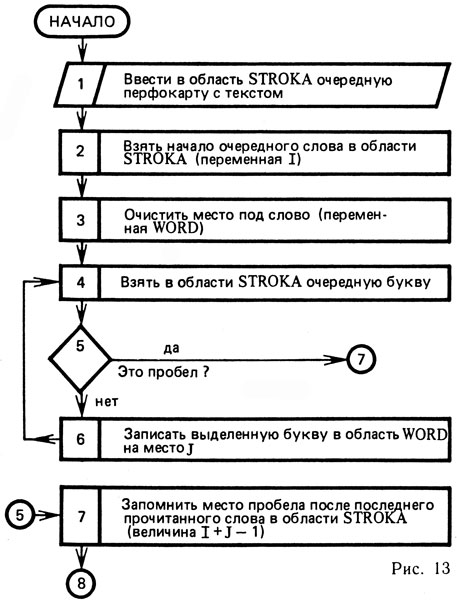
Рис. 13
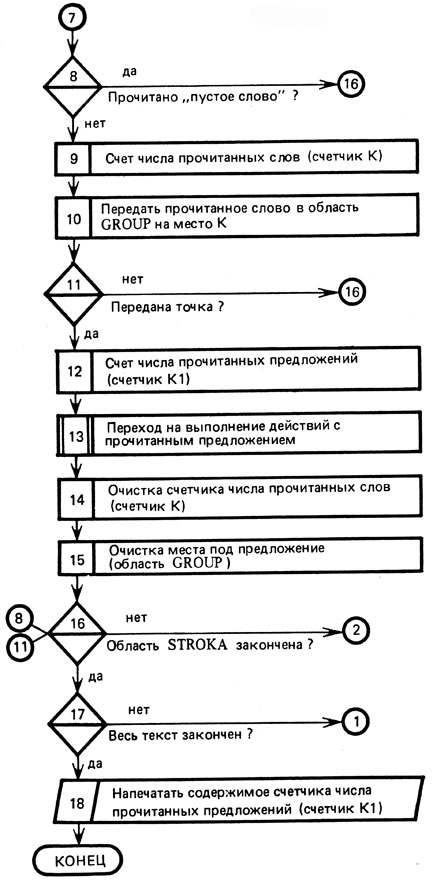
Рис. 13 (окончание)
Как только с предложением выполнены определенные действия, в программе необходима подготовка к чтению нового предложения. Для этого нужно очистить место для нового предложения (область GROUP) и счетчик числа слов (К) в новом предложении. После этого осуществляется возврат в область STROKA для взятия первого слова нового предложения и т. д. (см. рис. 13).
Представление предложения в машинной памяти именно в таком виде, как это делает описываемый алгоритм, удобно тем, что всегда известно, где начинается любое слово предложения и где заканчивается все предложение (каждое слово предложения при этом занимает одно и то же фиксированное число байтов независимо от того, сколько в нем букв). Но такое представление предложения в машинной памяти нерационально. Например, на рисунке 12 слово СКОРО состоит из пяти букв, а область GROUP(1), где содержится это слово, занимает 50 байтов. Таким образом, 45 бай-тов памяти не используются. Поэтому программа по только что описанному алгоритму может быть создана лишь для больших ЭВМ, обладающих большой внутренней памятью и имеющих языки программирования, ориентированные на решение информационно-логических и лингвистических задач.
Для микро-ЭВМ используется второй способ чтения предложения. При этом слово в машинной памяти занимает ровно столько байтов, сколько оно имеет букв. Такие предложения заносятся побуквенно с клавиатуры дисплея на его экран, а потом с него записываются во внешнюю память микро-ЭВМ на мини-диски. Они И вызываются затем на экран дисплея для работы.
|
ПОИСК:
|
При использовании материалов сайта активная ссылка обязательна:
http://informaticslib.ru/ 'Библиотека по информатике'