3.2. Алгоритм разбора предложения по членам предложения
Еще сложнее для ЭВМ задача выделения в предложении подлежащего, сказуемого, второстепенных членов предложения. Такой анализ основан на выяснении классов слов (частей речи) и определении тех падежей, в которых стоят слова тех или иных классов слов.
Например, если задано предложение: НА ОПУШКЕ КОЛХОЗНИКИ ПОСТРОИЛИ КРАСИВЫЙ ДОМ, то существительное КОЛХОЗНИКИ является подлежащим, так как оно стоит в именительном падеже. Слово ДОМ - дополнение, так как оно стоит в винительном падеже. Сочетание слов НА ОПУШКЕ будет обстоятельством места, так как об этом свидетельствует пространственный предлог НА в сочетании с существительным в косвенном (предложном) падеже. Глагол ПО-СТРОИЛИ - сказуемое, так как он согласован с подлежащим КОЛХОЗНИКИ в числе. Наконец, прилагательное КРАСИВЫЙ будет определением при существительном ДОМ, так как это прилагательное стоит перед существительным и согласовано с ним в роде, числе и падеже.
Чтобы такой анализ могла провести машина, необходимо научить ее распознавать части речи, а также грамматические значения рода, числа, падежа, времени и т. д. По форме слова трудно, а для некоторых языков просто невозможно, определить ту часть речи, к которой относится конкретное слово предложения.
Есть различные подходы к формальному определению частей речи. Для нашей задачи принимаем, что для выделения членов предложения в машинной памяти хранится некоторый словарь, где при каждом слове указана определенная грамматическая информация.

Таблица 11
* ( Так как разрабатываемый на основе этой таблицы алгоритм носит чисто иллюстративный характер, то таблица не содержит всех возможных слов и словосочетаний, которые могут стоять до запятой и после нее.)
Например, пусть для ЭВМ задан такой словарь в виде основ слов:

В этом словаре стоящие сразу за основой буквы С, А, П, Г означают соответственно: существительное (С), прилагательное (А), предлог (П), глагол (Г). Далее для существительных указывается род (М - мужской, Ж - женский). Для предлога указывается тип предлога: П - пространственный. Вслед за этим между вертикальными линиями указываются падежные окончания существительных, прилагательных и глаголов. Для существительных падежные окончания сначала указываются в единственном числе (им., род., дат., вин., твор., предл.), затем - во множественном (им., род., дат., вин., твор., предл.). Для прилагательных указываются те же падежные окончания сначала для мужского рода, затем женского и среднего рода, и наконец, падежные окончания во множественном числе (все эти группы окончаний разделены двойной вертикальной линией ||). Суффиксы и окончания глаголов* представлены в такой последовательности: сначала указывается машинное окончание инфинитива (ИТЬ), затем подобные окончания личных форм в настоящем времени (для данной глагольной основы таких окончаний нет). Далее указываются глагольные окончания прошедшего и будущего времени.
* (Такие рядом расположенные суффиксы и окончания называются машинными окончаниями. Они могут не совпадать с окончаниями, выделенными в школьной грамме. Далее машинные окончаниями мы будем называть просто окончаниями.)
Учитывая сказанное выше о методе определения частей речи и опираясь на только что рассмотренный словарь, фрагмент алгоритма анализа предложения по членам предложения можно представить так, как показано на рисунке 16 (предполагаем, что анализируемое предложение НА ОПУШКЕ КОЛХОЗНИКИ ПОСТРОИЛИ КРАСИВЫЙ ДОМ) ЭВМ "прочла" в область GROUP памяти программой "Чтение предложения".
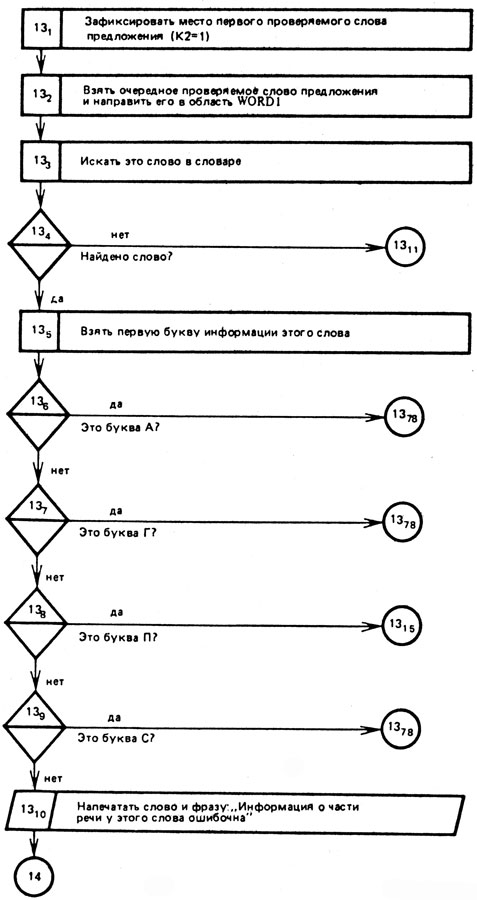
Рис. 16
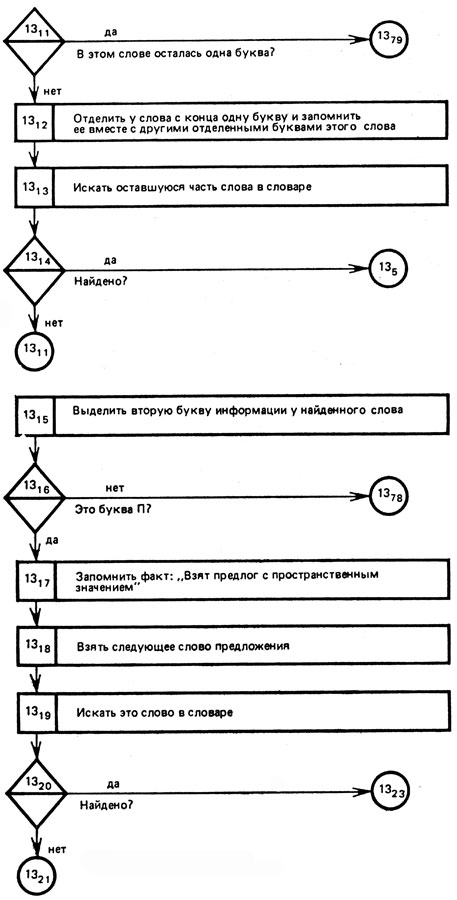
Рис. 16 (продолжение)
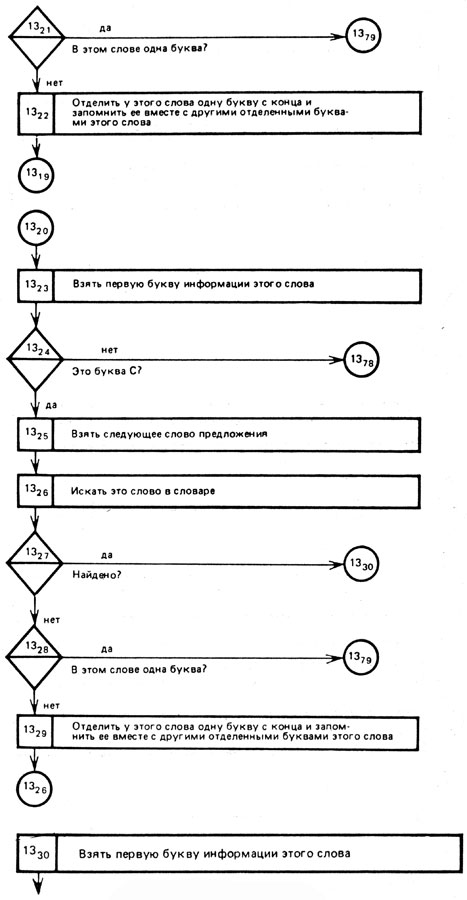
Рис. 16 (продолжение)
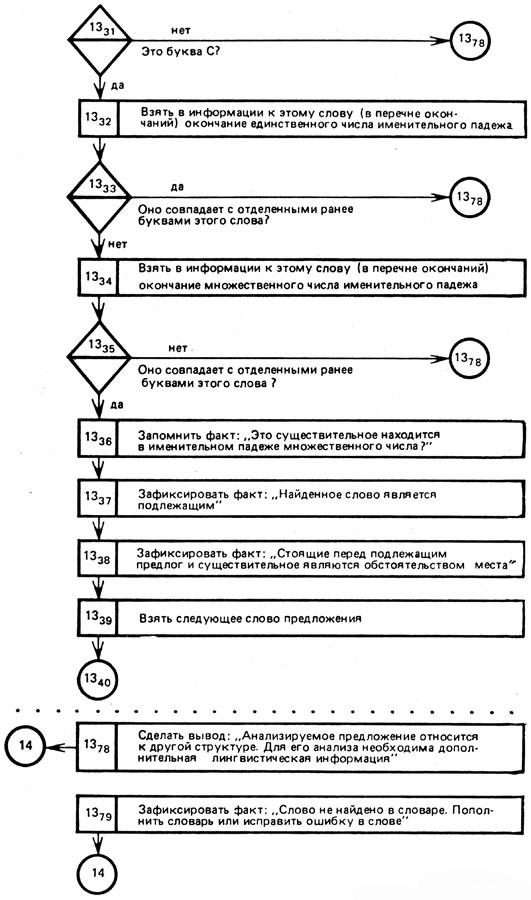
Рис. 16 (окончание)
Как видно из приведенного выше словаря, в нем указаны лишь основы слов*, поэтому в процессе поиска каждого слова из предложения в таком словаре сначала слово ищется в том виде, в котором оно встретилось в тексте. Так будут найдены слова НА и ДОМ (блоки 132-134, 1311 - 1314 и др.). Во всех других случаях при поиске текстового слова приходится у него последовательно "отнимать" с конца по одной букве. Например, если не будет найдено слово КОЛХОЗНИКИ, то, "отобрав" у этого слова с конца букву И (окончание), получим основу КОЛХОЗНИК, которая и будет найдена в словаре (блоки 1318-1322)- Блоки 1318-1322 отделяют у слова ОПУШКЕ окончание КЕ, а основу ОПУШ найдут в словаре на третьем шаге поиска.
* (Такие основы называются машинными основами. Они могут не совпадать с приводимыми в школьной грамматике основами слов.)
Обычно в подобных программах все перечисленные блоки поиска оформляются в виде отдельной маленькой программы - подпрограммы.
Так как приводимый алгоритм носит иллюстративный характер, то во всех случаях, когда встречаются отклонения от анализируемого предложения, мы направляем ЭВМ на блок 1378, фиксирующий факт отклонения.
Остальная процедура анализа достаточно четко представлена самим алгоритмом*.
* (Естественно, что, изучая этот алгоритм, необходимо постоянно обращаться к словарю, приведенному на с. 69, и к самому анализируемому предложению.)
|
ПОИСК:
|
При использовании материалов сайта активная ссылка обязательна:
http://informaticslib.ru/ 'Библиотека по информатике'