4. Перевод текстов с иностранных языков на русский с помощью ЭВМ
Первые эксперименты по переводу текстов с по-мощью ЭВМ были проведены в 1954 году. При этом в Нью-Йорке одна из первых машин перевела на английский язык несколько специально подготовленных русских предложений.
С этого времени в истории развития машинного перевода выделяют три этапа.
Первый этап (1954-1957 гг.) характерен тем,
что зародилась сама идея машинного перевода. В разных странах при этом создаются коллективы исследователей, которые с большим энтузиазмом берутся за решение проблемы перевода с помощью ЭВМ.
В период с 1957 по 1968 годы произошло некоторое охлаждение энтузиазма. Оказалось, что выдаваемые ЭВМ переводы далеки от переводов, выполняемых человеком. Выяснилось, что многие аспекты языковой деятельности человека при переводе трудно формализовать, т. е. представить в виде таких алгоритмов, которые мы рассматривали выше. В этот период возникает идея использования так называемого языка- посредника. Суть ее заключается в том, что вначале информация с какого-то языка (например, английского) переводится на некоторый язык-посредник, который постоянно находится в памяти ЭВМ, а с него уже можно переводить на какой угодно язык (русский, французский, немецкий и т. д.). Кульминационным моментом этого периода считается 1968 год, когда был опубликован доклад Комиссии Национального научного фонда США, в котором утверждалось, что перевод с помощью ЭВМ очень дорог, невыгоден для промышленного использования и что такой перевод не сопоставим по качеству с переводами, выполняемыми человеком.
В течение третьего периода (с 1968 года по настоящее время) происходит новое наращивание интереса к машинному переводу. Это связано с тем, что появились ЭВМ с огромным быстродействием и огромной внутренней памятью и проблема стоимости машинного перевода отошла на задний план. Вторая особенность этого периода - стремление строить не полностью автоматический перевод, а перевод на ЭВМ с некоторым вмешательством человека. Такое вмешательство может быть, например, на этапе, предшествующем вводу переводимого текста в ЭВМ (в работу включается предредактор). При этом предложения любого текста приводятся человеком к некоторому упрощенному стандартному виду, который ЭВМ легко переводит. Можно корректировать процедуру машинного перевода и в процессе работы ЭВМ, когда непонятные конструкции и слова ЭВМ печатает на бумаге или высвечивает на дисплее, а человек, владеющий соответствующим естественным языком и умеющий общаться с машиной (его называют "интерредактор"), дает ЭВМ соответствующие подсказки и расшифровки. Наконец, человек-постредактор может редактировать текст после его выдачи машиной. Таким образом, наиболее жизненными являются не полностью автоматические системы перевода, а автоматизированные системы.
Наиболее известной в мире системой машинного перевода является система СИСТРАН (System of Translation - система перевода), являющаяся собственностью компании "Уорлд транслейшн оф Канада". Эта система осуществляет перевод текстов по сельскому хозяйству, автомобильной и пищевой промышленности, вычислительной технике, связи, аэронавтике, электронике и т. д. Используются следующие пары языков: англо-русский, русско-английский, англо-испанский, французско-английский, англо-арабский. Перевод в этой системе осуществляется с помощью постредактора. Скорость перевода составляет 200-300 тысяч слов в час. Скорость редактирования 10 тысяч слов в час. Стоимость перевода одного слова 1,4 цента при одновременном вводе в машину 40-50 тысяч слов.
Чтобы можно было оценить эффективность работы такой системы, напомним, что опытный переводчик переводит в день 1200-1500 слов, а редактирует 4000-5000 слов.
Системы машинного перевода созданы также в ФРГ, Японии, Китае, Франции и в некоторых других странах.
В нашей стране наиболее успешно работает система англо-русского перевода АМПАР (автоматизированный перевод англо-русский), созданная во Всесоюзном центре переводов (Москва). Ежегодно с помощью этой системы переводится несколько тысяч страниц английского текста по теме "Вычислительная техника и программирование". После перевода текст корректируется постредактором. Приведем образец англо-русского перевода, выполненного системой АМПАР:
Английский текст
Full duplex and 20 milliampere operation are selected by wiring. Figure 3-2 illustrates the wiring for the various modes of operation. Also illustrated is how an internal current source can be used in half duplex mode. Four wire twisted pairs are recommended for full duplex.
Полный дуплекс и 20-миллиамперная операция выбираются посредством монтажа электропроводки. Рисунок 3-2 показывает монтаж электропроводки для различных режимов операции. Также показанный есть как внутренний текущий источник может быть использован в половине дуплексном режиме. Четыре проводные скрученные пары рекомендуются для полного дуплекса.
В ВЦП (Всесоюзном центре переводов) разработаны также машинные системы франко-русского (ФРАП) и немецко-русского переводов (НЕРПА).
Чтобы понять суть процедуры машинного перевода и возникающие при этом трудности, рассмотрим алгоритм перевода на русский язык английского предложения:
On the glade the workers built a nice house.
Прежде чем переводить тексты определенной тематики с английского языка на русский, необходимо составить и "вложить" в память ЭВМ англо-русский словарь по текстам соответствующей тематики.
Допустим, что мы построили англо-русский словарь для машинного перевода. Фрагмент его дан в таблице 12. Рассмотрим его подробнее.
В колонке 1 расположены английские словоформы, т. е. английский словарь включает текстовые единицы. Такое представление английских слов связано с тем, что английский язык не содержит падежей и в нем мало различных форм одного и того же слова. Поэтому выгоднее для ЭВМ (она будет быстрее работать) задать все формы английских слов, чем восстанавливать такие формы по основам английских слов, как это сделано в предыдущей задаче и в русской части рассматриваемого англо-русского словаря (колонки 4 и 5).
Колонка 2 таблицы 12 содержит грамматическую информацию к соответствующей английской словоформе и адрес русского перевода (переводного эквивалента) этого слова. Причем, так как большинство английских слов могут быть по своей форме отнесены к разным частям речи, в грамматической информации предусмотрена фиксация двух частей речи для каждой словоформы (коды этих частей речи разделены знаком "/"). Первая буква информации означает первую часть речи, к которой может относиться словоформа (Р - артикль, Н - наречие, С - существительное, Г - глагол, А - прилагательное, П предлог). Вторая буква (за знаком "/") означает вторую часть речи, к которой может относиться эта же словоформа (коды те же). Далее указывается грамматическая характеристика первой части речи (для существительного единственное (Е) и множественное (М) число, для артикля - неопределенный (Н) или определенный (О), для глагола время (Н - настоящее, П - прошедшее), для предлога - его тип (П - пространственный). Следующий знак в информации обозначает грамматическую информацию второй части речи (коды те же). Стоящие далее три знака представляют коды семантических подклассов, к которым может потенциально относиться данная словоформа, употребленная в функции первой части речи. Коды эти расшифровываются в соответствии с таблицей 13. Например, словоформа BUILD в функции существительного в английских текстах может принадлежать к терминам строительства (знак С на 6-м месте, учитывая знак "/"), к терминам конструирования (знак К на 7-м месте) и может принадлежать к словам, описывающим место для жительства человека (знак Ж на 8-м месте). Знаки, стоящие на 9-11 местах, описывают семантические классы того же слова, выступающего в функции второй части речи. Далее идет четырехзначный адрес памяти, где хранится адрес русского перевода соответствующей английской словоформы, а за ним через знак "/" указывается в виде числа количество переводных эквивалентов, которыми может переводиться на русский язык соответствующая английская словоформа (предполагается, что каждый русский перевод в памяти машины занимает 80 байтов: 30 байтов для основы и 50 байтов для информации к основе).
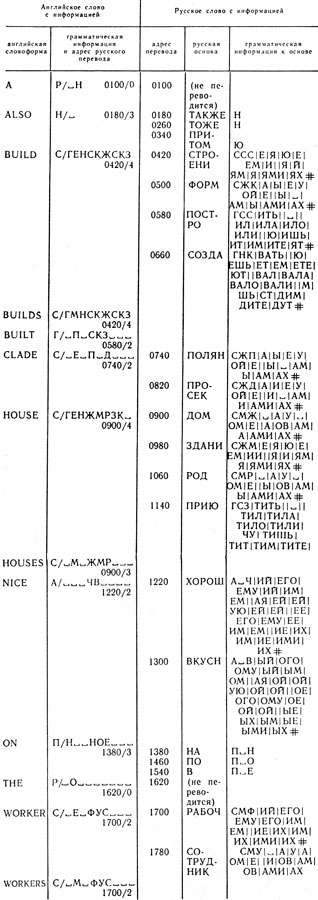
Таблица 12
Информация к русской части словаря начинается с адреса русского перевода (колонка 3). Далее идет основа русского переводного эквивалента (колонка 4) и грамматическая информация к этой основе. Последняя построена точно так, как это было сделано в рассмотренной выше задаче синтаксического анализа русского предложения. Отметим лишь, что здесь дополнительно введен для каждого слова индекс (третий знак в грамматической информации к основе), свидетельствующий о принадлежности соответствующей основы к тому или иному семантическому подклассу (табл. 13).
Итак, допустим, что с помощью программы "Чтение предложения" в область памяти с именем GROUP прочитано следующее английское предложение:
On the glade the workers built a nice house.
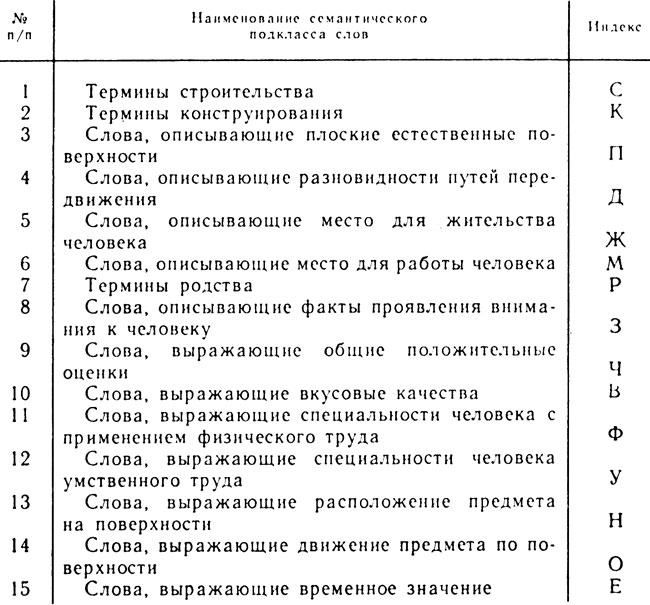
Таблица 13
С помощью алгоритма, подобного рассмотренному выше, проводится синтаксический анализ этого английского предложения*. В итоге получаем:
on the glade - обстоятельство места
the workers - подлежащее
built - сказуемое
a nice house - дополнение
* (В английском языке по сравнению с русским гораздо большее значение имеет порядок слов. Уже по расположению существительного относительно сказуемого можно судить, чем является это существительное - подлежащим или дополнением.)
В процессе такого анализа каждое слово предложения получает однозначный признак принадлежности к той или иной части речи и к тому или иному семантическому подклассу слов (последнее делается с учетом совместной встречаемости семантических подклассов слов в данном конкретном предложении). Как результат, для нашего предложения его слова получат однозначные грамматические признаки:
ON П/ 1380/3 GLADE С/ Е _ П 0740/2 WORKERS С/_М_Ф 1700/2 Г/_П_С 0580/2 А/_ _ _Ч 1220/2 C/_E _ Ж 0900/4
Далее, пользуясь знанием английского и русского языков, а также спецификой переводимых текстов (переводится ли научный текст, газетный или какой-то иной), выбирают в русском варианте возможные взаимные расположения подлежащего, сказуемого, дополнения и обстоятельства. Так, переводимое на русский язык английское предложение может быть передано следующим взаимным расположением членов предложения:
1) обстоятельство места + подлежащее + сказуемое + дополнение;
2) подлежащее + сказуемое + дополнение + обстоятельство.
Учитывая вышесказанное, допустим, что русский перевод строится по первой из двух предложенных схем.
Следующий шаг перевода-замена английских слов русскими переводными эквивалентами из англо-русского словаря. Эта простая на первый взгляд задача на самом деле является сложнейшей процедурой. Для оценки возникающих трудностей достаточно посмотреть в англо-русский словарь (табл. 12), откуда будут браться русские переводные эквиваленты. Видно, что почти все английские слова имеют по нескольку русских переводных эквивалентов. Какой же из них выбрать?
Задача значительно упрощается, если вспомнить, что в процессе синтаксического анализа английского предложения проведено однозначное отнесение английских слов к определенным частям речи и к определенным семантическим подклассам (см. с. 81). Поэтому в процессе замены слов английского предложения русскими словами происходит поиск каждой английской словоформы в англо-русском словаре (табл. 12) и замена этой словоформы одним русским переводным эквивалентом.
В итоге получаем следующую цепочку русских основ (информацию о падежных окончаниях мы здесь не приводим):
НА П _ Н ПОЛЯНА СЖМ РАБОЧ СМФ ПОСТРО ГСС ХОРОШ А _Ч ДОМ СМЖ
Заключительная задача сводится к морфологическому оформлению следующих пар слов:
(НА ПОЛЯН) -обстоятельство места
(РАБОЧ ПОСТРО) - подлежащее со сказуемым
(ХОРОШ ДОМ) - определение с дополнением
Так как предлог НА относится к семантическому подклассу, обозначающему "слова, выражающие расположение предмета на поверхности" (табл. 13), то из двух падежей (винительного и предложного), которые требует этот предлог, ЭВМ выбирает предложный, так как только он отвечает на вопрос ГДЕ? - НА КОМ? - НА ЧЕМ? - НА ПОВЕРХНОСТИ.
Помня о том, что слово GLADE в английском языке находится в единственном числе (см. табл. 12), для слова ПОЛЯН среди окончаний к этой основе (табл. 12, столбец 5) необходимо найти окончание единственного числа предложного падежа. Им будет окончание Е. В итоге получим:
НА ПОЛЯНЕ
Чтобы оформить окончаниями подлежащее и сказуемое
РАБОЧ ПОСТРО
необходимо вспомнить, что слово WORKERS в английском предложении находится во множественном числе (см. табл. 12), а глагол (соответствующий слову ПОСТРО) - в прошедшем времени. Значит, для слова РАБОЧ надо искать окончание в наборе окончаний для этой основы, находящееся в зоне для множественного числа именительного падежа. Им будет буквосочетание ИЕ. Для основы глагола ПОСТРО окончание ищем в зоне, соответствующей прошедшему времени множественного числа 3-го лица (РАБОЧИЕ - они). В итоге найдем окончание ИЛИ. Итак, получаем:
РАБОЧИЕ ПОСТРОИЛИ
Наконец, для оформления сочетания
ХОРОШ ДОМ
ЭВМ фиксирует, что слово HOUSE (ДОМ) было в тексте в единственном числе (табл. 12). Из информации в русской части к слову ДОМ машина выводит, что это слово мужского рода. Далее из специальных грамматических таблиц, находящихся в памяти ЭВМ, машина находит, что глагол ПОСТРОИТЬ является переходным глаголом, требующим после себя винительного падежа. Итак, среди падежных окончаний прилагательного ХОРОШ ищем окончание, соответствующее единственному числу, мужскому роду, винительному падежу. Им оказывается окончание ИЙ. Аналогично, набор тех же грамматических признаков позволяет найти в таблице окончаний для существительного ДОМ "пустое" окончание ("^_" "). Итак, получаем сочетание:
ХОРОШИЙ ДОМ
А в итоге все переведенное предложение будет выглядеть так:
НА ПОЛЯНЕ РАБОЧИЕ ПОСТРОИЛИ ХОРОШИЙ ДОМ
|
ПОИСК:
|
При использовании материалов сайта активная ссылка обязательна:
http://informaticslib.ru/ 'Библиотека по информатике'