Библейский мир
Вот некоторые выборочные факты из начального мира обитания Адама и Евы:

Эти факты составляют нашу базу данных. Как явствует из рис. 16.1, с этими фактами можно делать три вещи. Чтобы добавить или изъять факты, следует определить две функции: ADD (ДОБАВИТЬ) и REMOVE (ИЗЪЯТЬ):
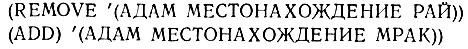
Функции ADD и REMOVE модифицируют базу данных
Имеется много различных возможностей структурировать базу данных и реализовать ADD и REMOVE. Простейшей идеей было бы поместить факты вместе в некоторый список и сделать этот список значением некоторого атома. Давайте воспользуемся для этого атомом DATA (ДАННЫЕ) ввиду его мнемонической привлекательности. Функция ADD помещает новый факт в базу данных, добавляя его к началу списка, который является значением переменной DATA. Сначала, однако, ADD проверяет, не присутствует ли уже этот факт в списке, иначе возникнет дублирование:
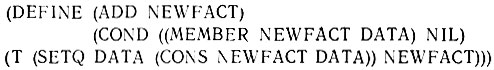
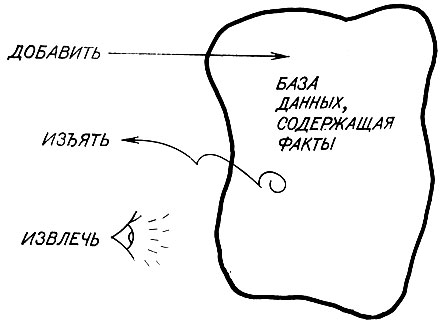
Рис. 16.1. Хранение информации в ассоциативных базах данных является альтернативой использованию свойств атомов и их значений. Нормально элементами базы данных являются списки атомов, но в общем случае допускаются также и s-выражения. Основные функции - добавление, изъятие и извлечение (поиск)
Эта функция возвращает NIL, если новый факт (NEWFACT) уже присутствует, в противном случае - сам этот новый факт. Некоторая деталь - ADD используется ввиду того воздействия, которое он оказывает на базу данных, а не из-за своего значения, так что это свойство носит случайный характер. Однако было бы разумно не возвращать нового значения переменной DATA, поскольку при этом терминал или другое устройство вывода может легко захлебнуться.
Функция REMOVE проще. В нашем варианте используется простое применение системной функции DELETE, причем если факт содержался в данных, то его значение возвращается этой функцией.

Функции FETCH и TRY-NEXT находят вхождения образцов
Как обстоит дело с поиском фактов, которые сопоставимы с некоторым образцом? Предположим, мы хотим знать, есть ли люди в нашей базе данных. Решением занимается функция FETCH (ИЗВЛЕЧЬ):
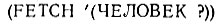
Прежде чем написать функцию FETCH, нам нужно решить, что она должна делать, если вхождения данного образца имеются. Возвращать первое обнаруженное вхождение и соответствующим образом установить значения переменных образца - это одно из легких решений. Функция MATCH (СОПОСТАВЛЕНИЕ), подставленная в соответствующий цикл, могла бы заниматься сравнением образца с последовательными элементами данных и присваивать значения переменным:
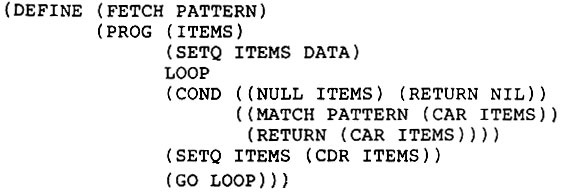
Такая функция FETCH проста и понятна. К сожалению, она оказывается бесполезной, если необходимо собрать все элементы данных, которые сопоставимы с образцом. При использовании нашей функции FETCH можно получить лишь первый элемент, который сопоставим с образцом.
Возвращать список всех сопоставимых элементов - довольно очевидная коррекция. Затем каждый элемент в возвращаемом списке может быть использован в соответствии с духом всей программы, которая осуществляет FETCH. При таких обстоятельствах функция FETCH не должна присваивать значений переменным в образце, поскольку нет никакой возможности узнать, какие из сопоставимых элементов данных должны обеспечивать эти присваивания. Поэтому
новая функция FETCH использует функцию TEST (ТЕСТ), которая не изменяет значения переменных:
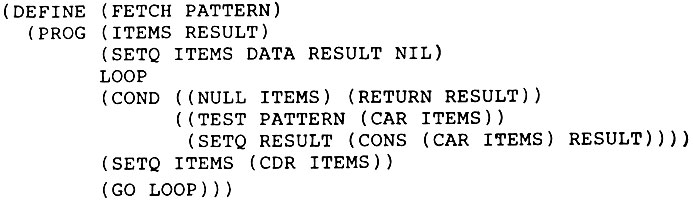
Функция TEST получается из функции MATCH, из которой удаляется свойство производить присваивания; оно заменяется любопытной альтернативой:

Просто отбрасывание (SET (ATOMCDR (CAR Р)) (CAR D)) было бы плохим решением, поскольку это запретило бы использование образцов вида (> X <Х), для которых присваивания, сделанные раньше, используются в дальнейшем. С другой стороны, не трогать программу нельзя ввиду требования, чтобы после сопоставления переменные не изменились.
Решение, разумеется, состоит в том, чтобы иметь временный, отдельный список присваиваний, оставив в покое значения переменных. Это сделано путем создания некоторого ассоциативного списка (a-list), что напоминает нам прием, использованный в связи с построением интерпретатора Лиспа. Когда встречается переменная с >, она и соответствующий ей элемент данных откладываются вместе в a-списке. Тогда в случае, если потребуется замена переменных их значениями, нужно будет заглянуть в a-список. Обычное значение используется, только если a-список оказывается беспомощным, потому что не было предшествующего использования соответствующей переменной с > в образце.
Переменная DISCOVERY (ОТКРЫТИЕ) содержит результат просмотра a-списка. Но функция CADR не может быть использована в применении к этому результату непосредственно, из-за риска взять CADR от NIL. Альтернативный вариант, возможно более изящный, основан на использовании ламбда-переменной вместо PROG-переменной, во избежание повторного вычисления при просмотре:

Теперь a-список передается как переменная функция TESTAUX (ДОПОЛНИТЕЛЬНЫЙ-ТЕКСТ), давая возможность полностью отбросить PROG в функции TEST. Лучше ли получаемый результат, зависит больше от вкуса, хотя новый подход приведет к совершенно иным результатам, если при сопоставлении будут рассматриваться рекурсивные образцы.
С использованием функции FETCH для библейского мира получается следующий результат:
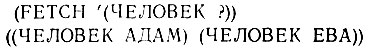
Для многих целей этого будет вполне достаточно, но еще одно усовершенствование упрощает вычисления, которые ведутся по очереди на списке открытых сопоставимых элементов и связаны с присваиванием значений переменным образца. Печать имен всех людей в нашем библейском мире является простым, хотя и скучным делом, поскольку результаты (FETCH (ЧЕЛОВЕК >Х) должны поступать на (PRINT X) путем присваивания значений X.
В языке CONNIVER Сассмана и Макдермота используется один хороший способ осуществления последовательных присваиваний. Эта работа выполняется функцией TRY-NEXT(ПОПРОБУЙ-СЛЕДУЮЩЕЕ) вместе со слегка модифицированной функцией FETCH. Функция FETCH создает список возможностей, который обычно становится значением некоторой переменной посредством операции SETQ. Вот пример:
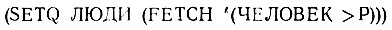
Затем функция TRY-NEXT работает над этими возможностями, обращаясь к данному атому. Каждый раз, когда применяется функция TR Y-NEXT, она вызывает новое присваивание, пока не будут перебраны все возможности. Теперь имеется такой способ напечатать имена всех людей:

Как же работают функции FETCH и TRY-NEXT? Поскольку присваивание значения должно производиться функцией TRY-NEXT, то она каким-то образом должна располагать тем образцом, который поставляется в функцию FETCH. Это легко организовать; функция FETCH просто помещает образец в начало списка, который она возвращает, так что функция TRY-NEXT может к нему обратиться, когда она будет работать со списком удачных сопоставлений. Необходима совсем незначительная модификация:
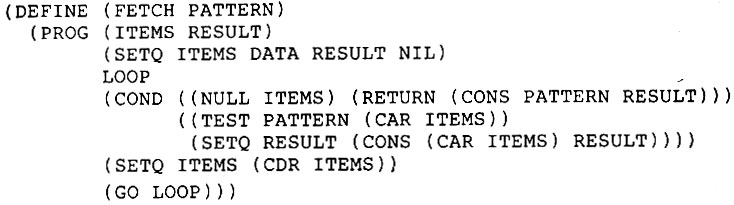
Теперь выражение (FETCH '(ЧЕЛОВЕК >P)) возвращает
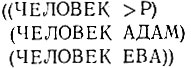
Когда функция TRY-NEXT применяется к такому списку, она должна присвоить значения переменным образца, как указывается самым первым элементом данных в этом списке, а затем отбросить этот элемент данных, так что когда TRY-NEXT применяется в следующий раз, то используется следующий элемент данных. Рассмотрим такой вариант:

Почему возникли EVAL и SET? Напомним, что функция TRY NEXT должна изменять значение атома, подаваемого на ее вход. Но чтобы это сделать, функция TRY-NEXT должна иметь доступ к самому атому, а не только к его значению. Следовательно, аргумент появляется в функции TRY-NEXT в "квотированной" форме, как обычно; далее, значение атома POSSIBILITIES (ВОЗМОЖНОСТИ) функции TRY-NEXT является атомом, значение которого следует изменить, а чтобы добраться до этого значения, надо проделать второй круг оценивания, поэтому и используется функция EVAL. Несколькими строками ниже вместо функции SETQ используется функция SET, опять-таки потому, что атом, подаваемый на вход функции TRY-NEXT,- это значение переменной POSSIBILITIES, а не сама переменная.
Заметьте, что функция ASSIGN выполняет необходимое присваивание значения переменным. Как и функция TEST, она также подобна нашей старой функции присваивания значений переменным MATCH (СОПОСТАВЛЕНИЕ);

Изменения в базе данных могут включить в работу демонов
Предположим, что Ева съедает яблоко номер А27182. Тогда уместно использовать следующие функции ADD и REMOVE;

Первая функция REMOVE делает очень важное изменение. Остальное - это просто рутинный учет, который может быть проделан подпрограммой, что даст определенный выигрыш за счет модульности системы. Для этой цели полезны демоны. Демоны представляют собой подпрограммы, вызываемые автоматически определенными добавлениями и изъятиями, производимыми в базе данных. Как следует из рис. 16.2, они постоянно наблюдают за тем, что входит в базу данных и что из нее выходит, и активируют себя, когда происходит что-то такое, что им нравится. Такая активация имеет место тогда, когда происходит успешное сопоставление между некоторым элементом в данных и тем образцом, который ассоциирован с демоном. Демон BAD-NEWS (ПЛОХИЕ-НОВОСТИ) определяется с помощью некоторого образца, который сопоставим с фактом изъятия яблока:

BAD-NEWS (ПЛОХИЕ-НОВОСТИ) - это имя демона, IF-REMO- VED (ЕСЛИ-ИЗЪЯТО) представляет собой тип демона, а (? ЕСТЬ ЯБЛОКО) - включающий его в работу образец. Поскольку этот образец, несомненно, соответствует (А27182 ЕСТЬ ЯБЛОКО), то демон переходит в активное состояние, когда этот элемент удаляется из базы данных. Таким образом, одно изъятие вызывает два других изъятия и два добавления с помощью такого демона. Разумеется, применение функций REMOVE и ADD в демоне может также вызвать их собственные ЕСЛИ-ИЗЪЯТО или ЕСЛИ-ДОБАВЛЕНО. Возможны неприятные циклы из демонов.
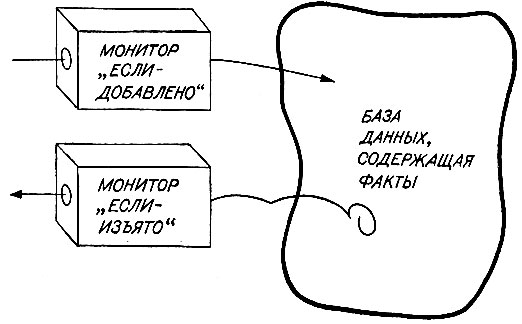
Рис. 16.2. Демоны наблюдают за потоками в базу данных и из нее. Демон типа 'если-добавлено' срабатывает, когда то, что добавляется, сопоставимо с образцом, определенным в момент создания демона. Демон типа 'если-изъято' срабатывает
Демоны полезны
Вот две причины, по которым используются демоны:
- Демоны добавляют знания в систему, не указывая, где эти знания будут использованы. Нет необходимости работать над системой дополнительно, когда в распоряжении появляется новый демон. Как компетентные помощники, они не нуждаются в подсказке, когда им надлежит вступить в работу. Они вызываются к жизни, когда складывается определенная ситуация, а не потому что к ним обращается некоторая программа. Это особенно важно, когда система создается сразу коллективом людей.
- Демоны выполняют рутинные операции учета, которые в противном случае загромождали бы программу. Системы с демонами могут быть переписаны без них, путем тщательной расстановки тестов и последующих действий в тех местах, где могли бы вступить в силу демоны. Такие системы оказываются длиннее и труднее для восприятия. Напротив, демоны удаляют операции учета с переднего плана. Они наблюдают за тем, что происходит, и ненавязчиво выполняют свои обязанности, когда этого требуют обстоятельства. Программы становятся более прозрачными, потому что в них перечисляются только важные действия - со всякого рода нагромождениями разбираются демоны, которые делают это незаметно.
Сегодня многие языки программирования обеспечивают возможности, схожие с демонами, когда процедуры активируются благодаря определенным добавлениям, изъятиям или поиску в базе данных.
Функция DEFINE-DEMON вводит демонов в базу данных
Наша задача сейчас - реализовать методы "если-добавлено" или "если-изъято". Для ориентации полезно сделать следующие замечания:
- Мы хотим реализовать систему, работающую с миром Адама и Евы, в качестве упражнения по созданию функций от баз данных.
- Мы уже реализовали функции ADD, REMOVE, FETCH и TRY-NEXT (т. е. ДОБАВИТЬ, ИЗЪЯТЬ, ИЗВЛЕЧЬ и ПОПРОБУЙ-СЛЕДУЮЩЕЕ)
- Сейчас мы реализуем функцию DEFINE-DEMON (ОПРЕДЕЛИТЬ-ДЕМОН), так что появится возможность добавлять демонов типа "если-добавлено" или "если-изъято".
Наша стратегия состоит в модификации функций ADD и REMOVE и добавлении к базе данных информации, включающей демонов. Для случая BAD-NEWS (ПЛОХИЕ-НОВОСТИ) новым элементом базы данных является следующий:
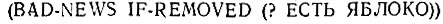
Наша общая форма для демона следует модели для BAD-NEWS, комбинируя имя, тип и образец. Чтобы такие новые элементы данных можно было использовать, функции ADD и REMOVE должны быть обобщены, чтобы они могли их найти. Успешный поиск приводит к выполнению соответствующей функции (ниже немая переменная
OLDFACT означает СТАРЫЙ-ФАКТ):
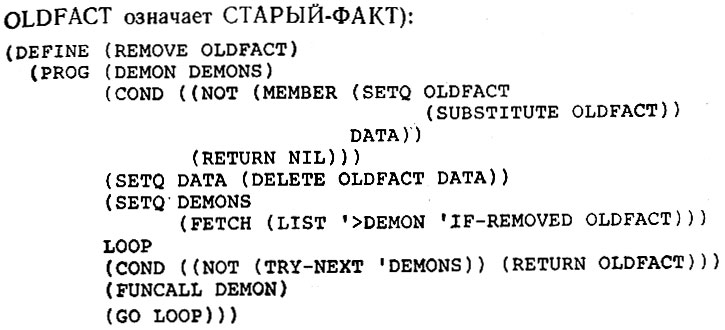
Заметим, что функция REMOVE была слегка обобщена, чтобы допустить переменные с <, пользуясь функцией SUBSTITUTE (ПОДСТАВИТЬ):

Если удаленным фактом было (А27182 ЕСТЬ ЯБЛОКО), то, безусловно, образец, поступающий в функцию FETCH, есть
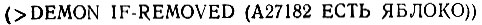
что будет соответствовать образцу, возникшему при определении демона BAD-NEWS (ПЛОХИЕ-НОВОСТИ).
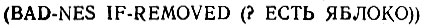
Заметим, однако, что для успеха дела необходимо обобщить функцию TEST (ТЕСТ), используемую функцией FETCH, поскольку теперь "?" допускается как со стороны образца, так и со стороны данных. Кроме того, как образцы, так и данные больше не ограничиваются атомами, но имеют элементы, которые сами по себе являются списками. Отсюда функция TEST должна быть рекурсивной для того, чтобы воспринимать и обеспечивать обработку элементов данных и образцов более общей природы.
Если образец, созданный в функции ADD (ДОБАВИТЬ), соответствует некоторому элементу данных, тогда в конечном итоге некоторое имя функции оказывается связанным с атомом DEMON и функция выполняется. Заметьте: считается, что у этой функции аргументов нет. Это не вызывает удивления, поскольку неявное
обращение через образец не открывает никакого пути, по которому можно было бы передать аргументы.
Очевидно, что работа функции DEFINE-DEMON(ОПРЕДЕЛИТЬ ДЕМОН) должна состоять из двух частей: во-первых, она должна установить нужную ассоциацию имени функции, типа демона и образца в базе данных, а во-вторых, она должна установить определение функции, которая занимает ячейку функции в указанной ассоциации. Естественно предположить, что этих целей можно добиться, используя функции CAR, CDR, APPEND и EVAL. Нужно, чтобы выражение

задавало определение так же, как это делает выражение
Поскольку аргументы оценке не подвергаются, то, разумеется, DEFINE-DEMON должна быть FEXPR. Пусть аргументом этой функции будет переменная DEFINITION (ОПРЕДЕЛЕНИЕ):
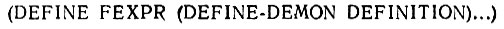
Теперь, рассматривая синтаксис функции DEFINE-DEMON, мы видим, что необходимые составляющие для обыкновенного определения функции могут быть выужены из переменной
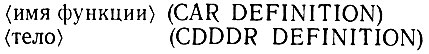
Таким образом, "определительный" эффект функции DEFINE-DEMON осуществляется путем сведения этих элементов вместе, а также включением атома DEFINE и оцениванием результата

Аналогично соответствующий элемент демона, предназначенный для базы данных, также использует определенную подборку элементов переменной DEFINITION:

Таким образом, необходимый элемент базы данных будет правильно сформирован следующим образом:

Итак, для определения функции DEFINE-DEMON (ОПРЕДЕЛИТЬ -ДЕМОН) мы имеем следующее:

Все это легче воспринимать, если помнить, что мы имеем здесь одновременно две отдельные операции определения. Первая - это определение функции DEFINE-DEMON, которая является FEXPR. Вторая - это использование DEFINE-DEMON, что означает создание и выполнение второй операции определения. Эта вторая операция создает конкретных демонов, которые являются обыкновенными EXPR.
Демонов можно добавлять и изымать
Иногда какой-то метод может оказаться лишь временно уместным. По этой причине приятным является то обстоятельство, что демонов можно добавлять и изымать. Функция DEFINE-DEMON занимается добавлением демонов. Удаления же производятся, как в следующем примере с BAD-NEWS (ПЛОХИЕ-НОВОСТИ):

Методы активируются функциями базы данных, только пока они там есть. В конечном счете, нам не нужно следить за тем, съедено ли яблоко после падения.
FETCH и TRY-NEXT могут активировать демонов типа "если-необходимо"
В развитых системах функции FETCH (ИЗВЛЕЧЬ) и TRY-NEXT (ПОПРОБУЙ-СЛЕДУЮЩЕЕ) могут также инициировать вызовы функций для выполнения определенных действий, связанных с базой данных. Раньше мы рассмотрели активирующие операции, связанные с добавлением и удалением, а теперь обратимся к поиску.
- Демоны FETCH (ИЗВЛЕЧЬ) наиболее часто используются для извлечения элементов данных, которые следуют из фактов, но сами по себе отсутствуют.
Предположим, что кому-то необходим список существ, подверженных ошибкам (т. е. FALLIBLE). Выполнять при этом (FETCH' (FALLIBLE > VICTIM)) было бы бесполезно, потому что в базе данных такие элементы в явной форме отсутствуют. Но несомненно, что все люди подвержены ошибкам, и имеет смысл перечислить их. Некоторый демон извлечения может решить такую задачу, но для его использования требуется несколько новых идей*:

* (В этом выражении HUMAN-FACT-1 (ЧЕЛОВЕК-ФАКТ-1) - имя демона, IF-NEEDED означает ЕСЛИ-НЕОБХОДИМО, FALLIBLE - ошибающийся, PEOPLE - люди, HUMAN - ЧЕЛОВЕК.- Прим. перев)
Синтаксис образца метода будет объяснен несколько позднее. Сейчас же заметим, что цикл начинается с того, что переменная PEOPLE (ЛЮДИ) становится списком возможностей. Этот список укорачивается и выполняется новая функция RECORD-INSTANCE (ЗАПИСАННЫЙ-ПРИМЕР) при каждом прохождении через тестовую часть цикла. Когда больше возможностей не остается, цикл завершается, тест удовлетворяется, и функция ADIEU (ДО-СВИДАНИЯ) приводит к возвращению из этой процедуры.
Поскольку детали здесь оказываются сложными, лучше всего подробно рассмотреть наш пример, связанный с поиском ошибающихся существ:
- Функция FETCH в выражении (SETQ EXAMPLE (FETCH' (FALLIBLE >>VICTIM))) не может найти элементов данных, но она может найти метод. Значением переменной EXAMPLE (ПРИМЕР) является:
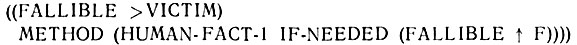
Поскольку элементы списков всех возможностей теперь могут быть и методами, и элементами данных, то для ясности необходимы маркеры METHOD (МЕТОД) И ITEM (ЭЛЕМЕНТ). Разумеется, функции FETCH и TRY-NEXT должны быть изменены так, чтобы воспринять это изменение в синтаксисе для элементов данных, а также обобщены на случай методов.
- Поэтому функция TRY-NEXT сталкивается с некоторым методом, когда она видит значение атома EXAMPLE (ПРИМЕР).
- Внутри функции HUMAN-FACT-1 (ЧЕЛОВЕК-ФАКТ-1), теперь активной, другая функция, FETCH (ИЗВЛЕЧЬ), создает список возможностей, присваиваемый переменной PEOPLE (ЛЮДИ):
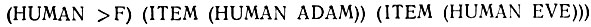
- С каждым повторением цикла функция RECORD-INSTANCE (ЗАПИСАННЫЙ-ПРИМЕР) добавляет образец метода, т. е. (FALLIBLE f F), к невидимому внутреннему списку после того, как ↑F заменяется на текущее значение F. Новый префикс t используется только в образцах типа "если - необходимо". Он показывает, что значения следует передать из метода в функцию FETCH, которая его вызывает. Этот цикл совершается по одному разу для каждого вхождения в список возможностей переменной PEOPLE, пока он не будет исчерпан. Таким образом, эта внутренняя запись содержит один элемент для каждого человека из списка PEOPLE (ЛЮДИ):
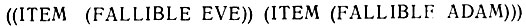
- Конец цикла приводит к ADIEU (ДО-СВИДАНИЯ). Этот специальный тип возврата пристраивает внутренний список, порожденный функцией RECORD-INSTANCE (ЗАПИСАННЫЙ-ПРИМЕР), в список возможностей на более высоком уровне, используемый тем частным случаем функции TRY-NEXT, которая активировала используемый метод. Поскольку функция TRY-NEXT работала с переменной EXAMPLE, когда произошло обращение к HUMAN- FACT-1, то EXAMPLE изменяется. Тогда этот метод HUMAN-FACT-1 поглощается и заменяется списком элементов, который он сгенерировал:
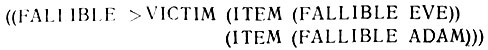
- Наконец, функция TRY-NEXT, которая видит, что она имеет дело с методом, а не элементом, рассматривает список новых возможностей, как будто бы не было этого продолжительного путешествия. Происходит поглощение первого из двух новых элементов и приписывание ЕВА в качества значения VICTIM. В целом описанный вызов метода достаточно прозрачен. Функция TRY-NEXT работает так, как если бы все поступало непосредственно из базы данных. Следующее выражение приведет к печати сначала слова ЕВА, а затем - АДАМ:

Таким образом, функция RECORD-INSTANCE (ЗАПИСАННЫЙ-ПРИМЕР), появляющаяся в методах типа "если-необходимо" (IF-NEEDED), размещает элементы, подобные данным в некотором списке, который в конечном счете сшивается в список возможностей, содержащий метод IF-NEEDED. Функция RECORD-INSTANCE конструирует каждый атом, который она размещает, путем подбора частного случая для образца в этом IF-NEEDED. Уфф!
Демоны занимаются падением
Давайте объединим все, что у нас есть, в систему, которая наблюдает за появлением дьявола, подбирает ошибающегося грешника, избавляется от яблока и перемещает Адама и Еву. Все, что нам нужно, это написать выражение для демона, наблюдающего за дьяволом:

Этот цикл заканчивается, как только конкретное значение переменной VICTIM проходит тест грешника, т. е. (PRESENT '(SINNER < VICTIM)). Функция PRESENT (ПРИСУТСТВУЕТ) просматривает базу данных, как это делает функция FETCH, лишь с тем, чтобы убедиться, что имеется хотя бы один частный случай, соответствующий образцу. Она возвращает либо Т, либо NIL.
Помните, что удаление яблока включает демона BAD-NEWS (ПЛОХИЕ-НОВОСТИ), который занимается уточнением элементов МЕСТОПОЛОЖЕНИЕ для атомов АДАМ и ЕВА. Таким образом, заканчивается все то, что началось с (ADD '(ДЬЯВОЛ МЕСТОНАХОЖДЕНИЕ РАЙ)).
Функции FETCH и TRY-HEXT отличаются гибкостью
Некоторым специалистам по решению задач нравится то, как функция FETCH работает с функцией TRY-NEXT (ИЗВЛЕЧЬ, ПОПРОБУЙ-СЛЕДУЮЩЕЕ), потому что список возможностей оказывается выявленным, готовым к модификациям, если этого потребуют те функции, которые с ним работают. Методы и элементы данных могут быть реорганизованы, и нежелательные могут быть отброшены между последовательными применениями функции TRY-NEXT. В системе CONNIVER список возможностей доступен даже изнутри методов типа "если-необходимо" как значение свободной переменной POSSIBILITIES (ВОЗМОЖНОСТИ). Таким образом, и вызывающий, и вызываемый имеют равные права на модификацию. Многие языки этого не допускают, для них решение использовать методы типа "если-необходимо" является окончательным - нет возможности остановиться и заглянуть вперед, прежде чем идти дальше.
|
ПОИСК:
|
При использовании материалов сайта активная ссылка обязательна:
http://informaticslib.ru/ 'Библиотека по информатике'