Множественные миры
Иногда задача по своему характеру стимулирует развитие нескольких альтернативных подходов. Обычно одна атака развивается до тех пор, пока дело не застопорится. Временно отложенная процедура, может быть возобновлена, если другие подходы к задаче окажутся относительно хуже. Тем временем большинство фактов относительно самого мира задачи остаются неизменными, хотя какие-то факты могут быть добавлены или изъяты по ходу рассуждения. Поэтому необходимо иметь несколько почти идентичных моделей мира и обеспечить некоторый способ переключать цель функций базы данных с одной на другую.
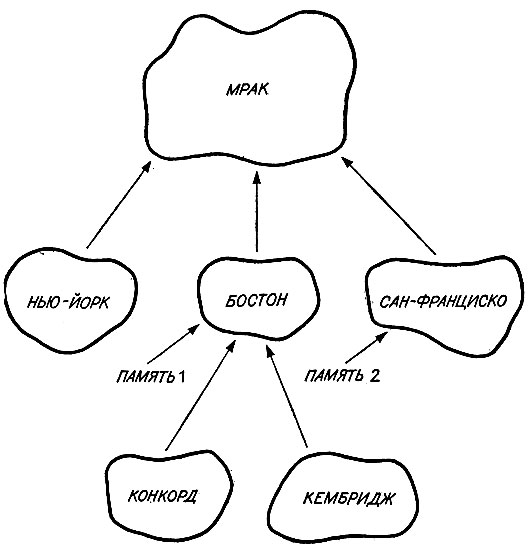
Рис. 16.3. Из соображений экономии базы данных могут быть организованы в виде дерева. В настоящем примере Нью-Йорк имеет все те же свойства, что и Мрак, за исключением специфических отличий, отмеченных в узле Нью-Йорк. Конкорд отличается от Мрака за счет той информации, которая имеется в узле Бостон и Конкорд. Некоторый факт может присутствовать в базе данных Мрак, отсутствовать в базе данных Бостон и вновь присутствовать в случае Конкорда или Кембриджа
Множественные контексты стимулируют предварительные попытки при решении задач
Предположим, например, что Адам хочет присмотреть себе новое место для жилья. Он, возможно, вообразит себя находящимся в том или ином месте, построив для каждого из них модель мира. Большинство житейских фактов будут одними и теми же независимо от рассматриваемого мира. Следуя соображениям эффективности, каждая из выработанных моделей будет отсылаться к некоторой централизованной совокупности таких фактов, а не пользоваться каждый раз их отдельной копией.
Рис. 16.3 в абстрактной форме иллюстрирует, что нам нужно. Большинство фактов хранится в базе данных наверху, т. е. в начальной базе данных. Каждое дополнение - это запись о добавлениях и удалениях. Вход в эту базу данных обычно лежит через одно из таких дополнений. Цепь звеньев от вводимого дополнения до начальной базы данных определяет множество принятых во внимание добавлений и изъятий.
Что же должно быть сделано на уровне s-выражений для реализации такой базы данных, состоящей из связанных между собой множественных контекстов? Прежде значением переменной DATA (ДАННЫЕ) был список всех элементов базы данных. Теперь же это будет совокупность связанных списков, по одному для каждого набора элементов. Переменная DATA становится списком списков, причем каждый элемент соответствует некоторому дополнению.
Новые ячейки создаются с помощью функции PUSH-CONTEXT (ВТОЛКНУТЬ-КОНТЕКСТ). Предположим, что значение DATA говорит о двухконтекстной цепи:
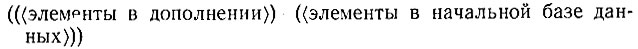
Тогда, выполнив (SETQ DATA (PUSH-CONTEXT DATA)), получаем новое значение для переменной DATA:
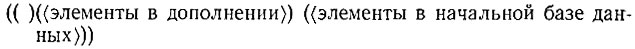
Вполне естественно, что вначале новая ячейка оказывается пустой.
Функция POP-CONTEXT (ВЫТОЛКНУТЬ-КОНТЕКСТ) делает обратное, она используется для того, чтобы установить указатель переменной DATA на один шаг выше по нашей цепи. Если возникает какая-то необходимость вернуться в состояние, которое было действительным в момент, непосредственно предшествующий POP-CONTEXT, то ясно, что должно быть установлено значение некоторой переменной, чтобы сохранить содержимое базы данных в этой точке. Это делается так:
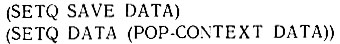
В дальнейшем восстановление делается просто командой
Остановимся, чтобы подвести итоги.
- Значение переменной DATA является список подконтекстов.
- Новые, изначально пустые подконтексты порождаются функцией PUSH-CONTEXT (ВТОЛКНУТЬ-КОНТЕКСТ).
- Старые состояния сохраняются явным образом путем установления значений атомов, соответствующих имеющемуся значению атома DATA (ДАННЫЕ).
- Старые состояния восстанавливаются либо путем установки значения DATA равным запомненным величинам, либо за счет использования функции POP-CONTEXT (ВЫТОЛКНУТЬ- КОНТЕКСТ), если восстанавливаемое состояние находится на некотором расстоянии вверх по цепи от текущего контекста.
Чтобы контексты можно было добавлять, требуется дополнительная работа
Естественно, что воплощение идеи множественных контекстов потребует значительного изменения функций ADD (ДОБАВИТЬ). REMOVE (ИЗЪЯТЬ) и FETCH (ИЗВЛЕЧЬ). Функция FETCH должна искать сопоставимые элементы не только в первом дополнении в цепи, но также и в каждом подконтексте вверх по пути обращения. Удаление также приводит к трудностям. Каждый из удаленных элементов должен бы исчезнуть - операции FETCH работают над значением имеющейся сейчас переменной DATA в тот момент, когда указанный элемент уже удален, но если контекст переустановлен заново функцией POP-CONTEXT, то функция FETCH должна иметь возможность доступа к указанному элементу. Последний удаляется только в отношении пути доступа, идущего через данный подконтекст, но не для других путей.
Одним методом решения такой задачи является дополнение каждого элемента в базе данных знаком если это добавление, или знаком "-", если это изъятие. Тогда функция REMOVE будет в действительности изымать элемент данных, только если он появляется во входном контексте. В противном случае она вернет его назад, снабдив знаком "-", указывающим, что это было локальное удаление.
Чтобы увидеть, как это все работает, рассмотрим следующую последовательность:

Здесь различные контексты связаны лишь изменением место прибывания Адама. Очевидно, что Адам заглядывает туда и сюда, подыскивая себе место для жилья. Он пробует Нью-Йорк, и немедленно отвергает эту идею. Бостон* тоже не годится, но его, пожалуй, стоит оставить в памяти. Следующим городом является Сан-Франциско, но он тоже не подходит. Он все еще хранится в памяти, когда Адам возвращается еще раз к Бостону.
* (Бостон, Кембридж и Конкорд представляют собой города в штаге Массачусетс, США, непосредственно примыкающие друг к другу. В Кембридже располагается Массачусетский технологический институт, в составе которого работает лаборатория искусственного интеллекта, руководимая автором книги.- Прим. перев)
При изучении района Бостона в контексты должны быть включены города Конкорд и Кембридж с помощью двух независимых применений функции PUSH-CONTEXT (ВТОЛКНУТЬ-КОНТЕКСТ) к переменной ПАМЯТИ. Тогда это будет соответствовать контекстной структуре, показанной в абстрактной форме раньше.
Наша реализация в высшей степени неэффективна
Мы не пытались сделать программы быстрыми ни на уровне методов программирования в языке Лисп, ни на уровне выбора алгоритмов. Первым делом мы добивались простоты изложения. В результате работа программы носит затяжной характер. Несомненно, замена примененной нами функции сопоставления на такую, которая использует определенные пользователем макрокоманды вместо ATOMCAR и ATOMCDR, может значительно улучшить ситуацию, поскольку операции над именами атомов очень дорогостоящие.
Точно так же очень плохо держать базы данных в форме списка. Когда список для базы данных становится большим, то его просмотр с целью найти определенный элемент становится весьма дорогостоящей процедурой. Различные новые формы хеш-таблиц (или функций расстановки), широко применяемые в программировании, здесь могут также дать значительное улучшение. Эффективность остается, однако, одной из проблем, и исследовательская работа здесь продолжается.
|
ПОИСК:
|
При использовании материалов сайта активная ссылка обязательна:
http://informaticslib.ru/ 'Библиотека по информатике'