2.3. Измерение синтаксического стиля
Рассмотрим бесконтекстную однозначную грамматику 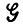 , правилам которой поставлен в соответствие массив чисел з = {pr} (см. разд. 2.10, т. 1). Если этот массив удовлетворяет условиям теоремы состоятельности для синтаксически управляемых вероятностей (см. этот же раздел), известно., что он определяет диффузный образ P(р) на множестве L(
, правилам которой поставлен в соответствие массив чисел з = {pr} (см. разд. 2.10, т. 1). Если этот массив удовлетворяет условиям теоремы состоятельности для синтаксически управляемых вероятностей (см. этот же раздел), известно., что он определяет диффузный образ P(р) на множестве L(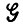 ) идеальных изображений - предложений, порождаемых грамматикой.
) идеальных изображений - предложений, порождаемых грамматикой.
Числа pr - это стилистические параметры, и априори они задаются редко. Эти параметры "измеряют" синтаксический стиль, и теперь мы займемся этой проблемой анализа образов. В данном разделе будет предполагаться известной грамматика 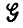 , но не pr, а случай, когда сама
, но не pr, а случай, когда сама 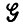 неизвестна, будет рассмотрен в гл. 7.
неизвестна, будет рассмотрен в гл. 7.
Если задано множество из n грамматически правильных предложений, порожденных на L (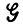 ) в соответствии с моделью синтаксически управляемых вероятностей, возникает проблема, как проверять гипотезы относительно р. Аналогично возникает и проблема, как проверить то, что их источником является один и тот же набор р стилистических параметров.
) в соответствии с моделью синтаксически управляемых вероятностей, возникает проблема, как проверять гипотезы относительно р. Аналогично возникает и проблема, как проверить то, что их источником является один и тот же набор р стилистических параметров.
Можно рассматривать L(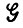 ) как выборочное пространство, содержащее счетно-бесконечную совокупность допустимых (грамматически правильных) предложений. Разбиение L(
) как выборочное пространство, содержащее счетно-бесконечную совокупность допустимых (грамматически правильных) предложений. Разбиение L(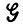 ) на не пересекающиеся множества L(
) на не пересекающиеся множества L(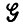 ) = A1 ∪ A2 ∪....∪Ak позволяет подсчитать для каждого множества Аi число наблюдаемых предложений и применить стандартный статистический критерий к этому множеству. Можно было бы, например, воспользоваться критерием χ2 сделав обычную оговорку о том, что в каждом множестве Аi ожидаемые частоты должны быть достаточно велики (см., например, монографию Крамера (1945), гл. 30).
) = A1 ∪ A2 ∪....∪Ak позволяет подсчитать для каждого множества Аi число наблюдаемых предложений и применить стандартный статистический критерий к этому множеству. Можно было бы, например, воспользоваться критерием χ2 сделав обычную оговорку о том, что в каждом множестве Аi ожидаемые частоты должны быть достаточно велики (см., например, монографию Крамера (1945), гл. 30).
Поступая таким образом, мы не используем преимуществ, связанных с регулярностью рассматриваемой структуры. Собственно критерий χ2 никаких сложностей не вызывает, но разбиение выбирается применительно конкретному случаю, и, следовательно, регулярность структуры пропадает. Мы же будем решать эту задачу не так и рассмотрим ее с позиций общей теории образов, положив в основу анализа детализированную структуру, неотъемлемо связанную с изучаемой задачей.
Стилистические параметры (для заданной грамматики 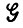 ) могут изменяться во времени и пространстве. Отразим это обстоятельство, записав
) могут изменяться во времени и пространстве. Отразим это обстоятельство, записав
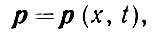 (2.3.1)
(2.3.1)где t обозначает время, а х - координату, которая может представлять не только географическое положение, но также и литературный жанр, социальную группу, к которой относятся говорящие, и другие характеристики подобного рода.
Стилистические тенденции можно в таком случае формализовать с помощью диахронической производной стиля
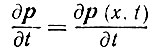 (2.3.2)
(2.3.2)и синхронической производной стиля
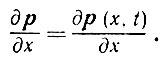 (2.3.3)
(2.3.3)Анализ стилистических образов заключается не только в поочередном анализе отдельных образов, но часто требует одновременного анализа нескольких образов с позиций стилистической тенденции и разницы между ними. Это относится к случаю непрерывных х и t. В дискретной постановке понятие "производная" следует, естественно, заменить понятием "разность".
С первого взгляда может показаться, что математический анализ стилистических образов - это трудное дело, так как вероятности на L ( ) имеют весьма сложный характер, даже если их удается задать в компактном виде (как это было сделано в разд. 3.2 т. 1). Мы убедимся, однако, что некоторые задачи можно решить, воспользовавшись структурой регулярности и выразив изображения и конфигурации на языке образующих. Это утверждение на самом деле справедливо и при более общих условиях.
) имеют весьма сложный характер, даже если их удается задать в компактном виде (как это было сделано в разд. 3.2 т. 1). Мы убедимся, однако, что некоторые задачи можно решить, воспользовавшись структурой регулярности и выразив изображения и конфигурации на языке образующих. Это утверждение на самом деле справедливо и при более общих условиях.
Целесообразно все же начать с одиночного диффузного образа. Допустим, что в результате наблюдения получено множество грамматически правильных предложений I1, I2,...,In, принадлежащих L( ), и требуется высказать некие утверждения относительно p. После выполнения грамматического разбора этих предложений можно записать совместную функцию правдоподобия в следующем виде:
), и требуется высказать некие утверждения относительно p. После выполнения грамматического разбора этих предложений можно записать совместную функцию правдоподобия в следующем виде:
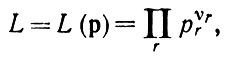 (2.3.4)
(2.3.4)где νr -число применений r-го правила грамматики (мы воспользовались уравнением (2.10.56) т. 1). Если грамматика неоднозначна, вместо последнего выражения возникает сумма членов (как в уравнении (2.3.5)), что усложняет анализ. Занумеровав синтаксические переменные i = 1,2,..., ν мы должны получить
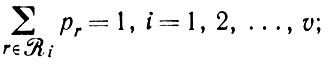 (2.3.5)
(2.3.5)где Ri - множество правил подстановки для переменной i. Мы воспользуемся критерием правдоподобия и максимизируем величину L(p) с учетом всех ограничений (2.3.5) при помощи одного множителя Лагранжа Ri для каждой синтаксической переменной. Итак,
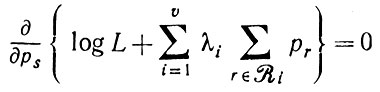 (2.3.6)
(2.3.6)или
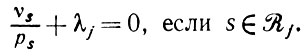 (2.3.7)
(2.3.7)Следовательно, объединив уравнения (2.3.5) и (2.3.7), получаем оценки максимального правдоподобия:
Эти оценки имеют непосредственную разумную интерпретацию.
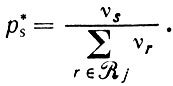 (2.3.8)
(2.3.8)Стилистический синтаксический анализ такого рода выполнен в диссертации Хенри (1972), где проведено эмпирическое изучение некоторых именных составляющих русского языка. Для того чтобы проиллюстрировать то, как это делается, приведем отдельные численные результаты. Выбранное множество правил подстановки для простых именных составляющих приведено в табл. 2.3.1. Переменные, стоящие в правых частях правил подстановки, преобразуются также с помощью терминальных (строго говоря, подтерминальных) правил в словарные классы, характер которых мы не будем здесь уточнять. Символ (S) обозначает оптимальное множественное число, а заключение переменной в круглые скобки обозначает ее оптимальность в преобразованной цепочке.
Для набора простых именных составляющих Хенри с помощью выражения (2.3.4) нашел оценки стилистических параметров -некоторые из них приведены в табл. 2.3.2. Эти оценки характеризуют
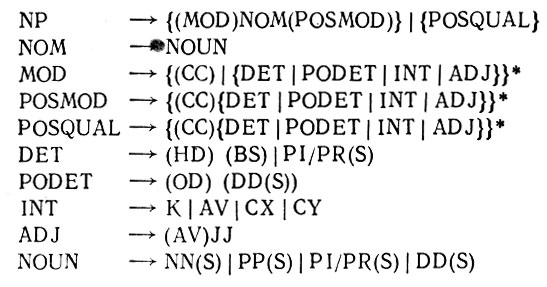
Таблица 2.3.1

Таблица 2.3.2
преобразование синтаксической переменной "существительное" (NOUN) в имя нарицательное и имя собственное в единственном и
множественном числе (NN) и (NNS) с личными местоимениями (РР) и (PPS), безличными и относительными местоимениями (PI/PR) и (PI/PRS), а также преобразование в числительные (DD) и (DDS).
В литературе, приведенной в списке, можно найти много соответствующих эмпирических данных.
Пусть эмпирически установлено, что {рr} характеризует синтаксический стиль для заданных (x, t), и пусть на L( ) задан набор предложений и имеется подозрение, что соответствующими стилистическими параметрами являются qr = рr + Δr, причем фиксированный набор Д^О. Для распознавания того, характеризуется ли некоторый временной диффузный образ параметрами р или q, воспользуемся леммой Неймана - Пирсона, ограничившись только главным членом разложения L (q) по А Это приводит к следующему выражению:
) задан набор предложений и имеется подозрение, что соответствующими стилистическими параметрами являются qr = рr + Δr, причем фиксированный набор Д^О. Для распознавания того, характеризуется ли некоторый временной диффузный образ параметрами р или q, воспользуемся леммой Неймана - Пирсона, ограничившись только главным членом разложения L (q) по А Это приводит к следующему выражению:
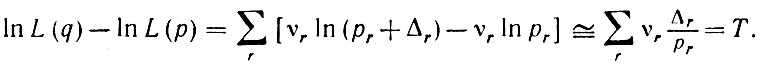 (2.3.9)
(2.3.9)Следовательно, при T ≥ T0 распознается образ с параметрами q, а в противном случае - образ с параметрами р, причем постоянную То следует подбирать так, чтобы обеспечить необходимый уровень значимости.
Мы предполагали здесь, что гипотетическая стилистическая разность А была задана. Чаще предполагается лишь наличие некоторой монотонной стилистической тенденции, отражающей то обстоятельство, что у второго образа отдельные стилистические параметры имеют большие, а другие - меньшие значения. Это означает, что в пространстве стилистических параметров q мы работаем в некоторой ограниченной замкнутой области С евклидова пространства. Пусть Свнш обозначает множество внешних точек С. Для того чтобы получить некоторое значение q^, следует максимизировать величину L(q), q∈C. Так как, однако,
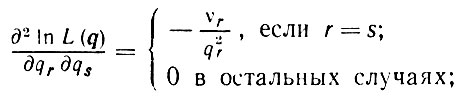 (2.3.10)
(2.3.10)то ln L (q) - вогнутая функция. Затем для определения q^ следует воспользоваться уравнением (2.3.8). Если полученное значение принадлежит С, то q^ найдено, иначе максимизирующее значение должно принадлежать Свнш и в отдельных случаях его можно определить в явном виде. Критерий распознавания имеет следующий вид:
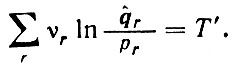 (2.3.11)
(2.3.11)
Допустим, что имеются два множества предложений, принадлежащих одному и тому же множеству L( ), но относящихся к различным жанрам 1 и 11 или к одному и тому же жанру, но к разным эпохам, и требуется получить некие утверждения о соответствующих стилистических производных (2.3.2) и (2.3.3). Сформируем два множества оценок:
), но относящихся к различным жанрам 1 и 11 или к одному и тому же жанру, но к разным эпохам, и требуется получить некие утверждения о соответствующих стилистических производных (2.3.2) и (2.3.3). Сформируем два множества оценок:
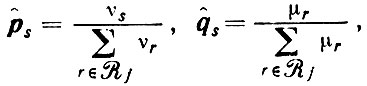 (2.3.12)
(2.3.12)где νr и μr обозначают частоты nr для двух рассматриваемых множеств предложений соответственно.
Данные, приведенные в табл. 2.3.2, характеризуют научные материалы, в основном тексты исследовательского характера, и их можно сравнить с данными, относящимися к обычной беллетристике (заимствованы из диссертации Хенри (1972)); соответствующие значения параметров qs приведены в табл. 2.3.3.

Таблица 2.3.3
Продолжаем действовать так же, как и выше. Когда изучаемая стилистическая тенденция характеризуется разностью q-p∈C, переходим к объединенному пространству (р, q) стилистических параметров. При этом отыскивается вектор (р, q) ∈ С, максимизирующий величину совместного правдоподобия и ее логарифма:
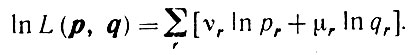 (2.3.13)
(2.3.13)
Рассмотрим два множества D1 и ID2 предложений, принадлежащие L( ), с соответствующими диффузными образами P1 и P2, которым поставлены в соответствие некоторые р и q. Множество 31 правил подстановки разбито на R' и R", и предполагается, что pr = qr Для хотя и необязательно для r ∈ R". Чтобы установить, действительно ли два диффузных образа идентичны, воспользуемся описанной выше процедурой и в результате придем к следующей теореме.
), с соответствующими диффузными образами P1 и P2, которым поставлены в соответствие некоторые р и q. Множество 31 правил подстановки разбито на R' и R", и предполагается, что pr = qr Для хотя и необязательно для r ∈ R". Чтобы установить, действительно ли два диффузных образа идентичны, воспользуемся описанной выше процедурой и в результате придем к следующей теореме.
Теорема 2.3.1.Разделение образов P1 и P2 по методу максимального правдоподобия можно осуществить с помощью достаточных статистик
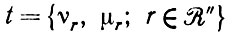 (2.3.14)
(2.3.14)и представить в терминах эмпирических энтропий относительно R": гипотеза P1 ≠ P2 принимается, если
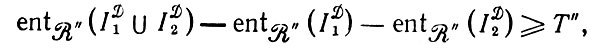 (2.3.15)
(2.3.15)в противном случае P1 = P2.
Доказательство. Совместную функцию правдоподобия можно представить как
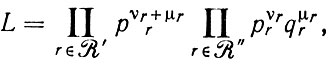 (2.3.16)
(2.3.16)так что t действительно является достаточной статистикой, а pr, r∈R' представляют параметры помех. Реализуя принцип максимального правдоподобия, максимизируем значение L при произвольных рr и qr, r∈R", с учетом естественного ограничения (2.3.5) и приходим к (2.3.12), откуда при pr = qr, r∈R", получаем модифицированную оценку
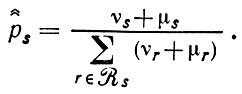 (2.3.17)
(2.3.17)В таком случае логарифм отношения максимального правдоподобия можно представить как:
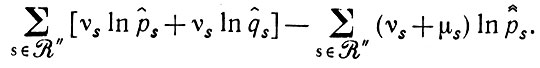 (2.3.18)
(2.3.18)Это выражение при представлении с помощью эмпирических энтропий по отношению к R" пропорционально следующему:
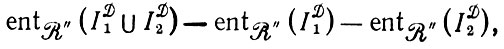 (2.3.19)
(2.3.19)
что доказывает утверждение теоремы (2.3.15)
Примечательно, сколь простой вид принимает анализ образов в рассмотренных выше задачах. Это происходит, несомненно, потому, что анализ проводится на языке образующих, а не наблюдаемых терминальных цепочек непосредственно.
Заслуживает изучения такой тип деформации стилистических образов, когда отношение связи р не является "равенством", а имеет случайный характер, и для показателей связи β и β' связь оказывается допустимой с некоторой вероятностью
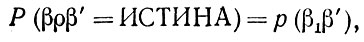 (2.3.20)
(2.3.20)
зависящей исключительно от показателей β и β. Условие (2.3.20) применяется независимо ко всем связям, соединенным в заданной конфигурации. Применительно к автоматным или бесконтекстным языкам мы получим деформации  , представляющие собой синтаксические ошибки.
, представляющие собой синтаксические ошибки.
Здесь мы не будем обсуждать способы анализа подобных деформированных образов; отношения связи типа (2.3.20) будут изучены в т. 3.
|
ПОИСК:
|
При использовании материалов сайта активная ссылка обязательна:
http://informaticslib.ru/ 'Библиотека по информатике'