4. Коды и множества совпадения
4.1. Основные свойства кодов
В настоящей главе перед нами стоят две задачи. Во-первых, мы хотим совершить краткий экскурс в теорию кодов. Эта теория дала ряд красивых результатов, применимых к различным разделам теории языков. Во-вторых, мы хотим обсудить некоторые недавно введенные понятия, тесно связанные с теорией кодов. Эти понятия нам потребуются в гл. 5 и 6. Подчеркнем, что мы не будем обсуждать так называемые коды с исправлением ошибок, а будем иметь дело исключительно с алгебраической теорией кодов, обычно рассматриваемой как часть теории полугрупп1.
1 (Более глубоко и детально ознакомиться с различными вопросами алфавитного кодирования и смежными проблемами теории конечных автоматов читатель может по работам [Л1*], [Л2*], [Мар2*].- Прим. перев.)
На интуитивном уровне код1 можно определить как такое множество слов, что любое произведение этих слов может быть "декодировано" только одним способом. Рассмотрим, например, множество слов
1 (В отечественной литературе в этом смысле часто употребляется термин "кодовое множество".- Прим. перев. )
Можно закодировать этими словами символы 0, 1, 2, 3 и "морфически" распространить это кодирование на все слова в алфавите {0,1,2,3}. Так, кодом слова 012230 будет слово
Гарантией однозначности декодирования служит тот факт, что каждое слово в алфавите {a, b} может быть представлено в виде произведения слов (4.1) не более чем одним способом. Этот факт легко установить, читая слова в алфавите {a, b) справа налево: каждое закодированное слово должно кончаться на одно из слов (4.1). Таким способом символы 0, 1, 2, 3 можно получить один за другим с правого конца. Это означает, что (4.1) является кодом.
С другой стороны, множество {a, ab, ba) не является кодом. Например, слово aba декодируется двумя разными способами: aba =(ab)a = a(ba).
Определение. Непустой язык C в алфавите ∑ называется кодом, если для любых слов xi1, xi2, ..., xim, xj1, ..., xjn из C, таких, что
имеет место xi1 = xj1. ▫
Если C является кодом, то из (4.2), очевидно, следует, что m = n и xit = xjt при t = 1, ..., m. Таким образом, каждое слово в C* единственным образом декодируется как произведение слов из C. Очевидно также, что в код не может входить пустое слово и что непустое подмножество кода также является кодом. Будем считать, что алфавит ∑ содержит не менее двух символов, так как однобуквенный алфавит тривиален с точки зрения кодирования. Теперь установим два довольно простых характеристических свойства кодов.
Лемма 4.1. Непустой язык C над алфавитом ∑ является кодом тогда и только тогда, когда существует множество символов ∑1 и биекция ∑1 на C, которую можно продолжить до инъективного морфизма ∑1* в ∑*.
Доказательство. Прежде всего заметим, что множество символов ∑1 может быть бесконечным (тем не менее понятно, что означает при этом ∑1*).
Рассмотрим часть "тогда" утверждения леммы. Предположим, что существуют ∑1 и биекция φ: ∑1→C, удовлетворяющие условию продолжения. Чтобы доказать, что C представляет собой код, рассмотрим произвольные слова xi1, ..., xim, xj1 ..., xjn из C, удовлетворяющие (4.2). Обозначая φ-1 (xit) = ait (соответственно φ-1 (xjt) = ajt получаем
(Здесь φ уже продолжено на ∑1*.) Тот факт, что отображение φ инъективно, влечет равенство
Следовательно, ai1 = aj1, откуда xi1 = φ(ai1) = φ(aj1) = xj1, и значит, С является кодом.
Рассмотрим часть "только тогда". Предположим, что C есть код. Пусть ∑1 - множество символов той же мощности, что C, а φ: ∑1→C - биекция, где соответствующие элементы обозначены одинаковыми нижними индексами. Это отображение естественным образом продолжается до морфизма ∑1* в ∑*. Нам еще надо доказать, что это продолжение φ инъективно.
Допустим противное: существуют элементы ∑1, удовлетворяющие условиям
Без потери общности можно предположить, что m в (4.3) является наименьшим из возможных: (4.3) не выполняется ни для какого m1<m. Следовательно, ai1 ≠ aj1. (При ai1 = aj1 мы получили бы
что противоречит минимальности m.) Таким образом, мы имеем
и ai1 ≠aj1. Так как ф есть биекция, то последнее неравенство влечет xi1 ≠ xj1, а это с учетом (4.4) противоречит предположению, что C является кодом. Отсюда следует инъективность продолжения отображения φ. ▫
Следующий результат известен под названием критерия Шютценберже. Будем говорить, что язык L катенативно-независим, если никакое слово w из L нельзя представить как произведение
Лемма 4.2. Катенативно-независимый непустой язык C над ∑ является кодом тогда и только тогда, когда для любого слова w в алфавите ∑ из того, что оба языка C*w и wC* пересекаются с C*, следует, что w принадлежит C*.
Доказательство. Сначала рассмотрим часть "тогда" утверждения леммы. Предположив, что C удовлетворяет условию леммы, мы должны показать, что C является кодом. Допустим противное: в C существуют такие слова xv, что
Согласно (4.5), одно из слов xi1 и xj1 является префиксом другого. Без потери общности можно считать, что
Согласно (4.5) и (4.6), языки C*y и C* (соответственно yC* и C*) пересекаются, имея общий элемент xj1 (соответственно xi2 ... xim). (Заметим, что из (4.5) и (4.6) следует, что m≥2.) Поскольку С удовлетворяет условию о пересечениях, получаем, что y принадлежит C*. Однако в силу (4.6) это заключение противоречит допущению о катенативной независимости языка.
Теперь рассмотрим часть "только тогда". Предположим, что С является кодом, и докажем от противного, что выполняется условие о пересечениях. Итак, предположим, что это условие не выполнено, т. е. что в C найдутся элементы xv, а в C* - элементы yv и такое слово w∉C*, что
Снова предполагая минимальность m, заключаем, что xi1 ≠ xj1 (В противном случае мы получили бы равенство вида (4.7) с меньшим m.) Теперь мы получаем, что
это противоречит предположению о том, что C есть код. ▫
Условие леммы 4.2 можно сформулировать более компактно: для каждого слова w из ∑*
Очевидно, что если все три множества C*w, wC* и C* имеют общий элемент, то пересекаются и пары множеств C*w, C* и wC*, C*. Обратно, если wx1 = x2 и x3w = x4, где x1, x2, x3, x4∈C*, то wx1x4 = x2x4 = x2x3w, откуда следует, что пересекаются все три множества. Заметим, однако, что одно лишь условие (4.8) (без допущения о катенативной независимости множества C) не гарантирует еще, что C является кодом.
Леммы 4.1 и 4.2 сами по себе не дают нам эффективного метода, позволяющего определить, является ли данный язык кодом, однако такие алгоритмы (для конечных языков) существуют. В сущности результаты гл. 2 приводят к следующему алгоритму: надо проверить, пусто ли множество x1C*∩x2C* для каждой пары (x1, x2) различных элементов из С. Старейшим является алгоритм, вытекающий из следующей теоремы и в первоначальном варианте принадлежащий Сардинасу и Паттерсону [SarP].
Теорема 4.3. Пусть C - непустой язык над ∑. Определим индуктивно языки C0, C1, C2, ... над ∑, полагая
Язык C является кодом тогда и только тогда, когда Ci∩C = ∅ для каждого i≥1.
Прежде чем перейти к доказательству теоремы, заметим, что в случае конечного языка C длина каждого слова в каждом Ci не превосходит длину самого длинного слова в C. Следовательно, существует лишь конечное число различных языков Ci, и мы действительно получаем алгоритм, определяющий, является ли множество C кодом (см. также упр. 1). Например, выберем в качестве С множество (4.1). В этом случае ;
Поскольку для каждого i≥1 Ci∩C = ∅, то C является кодом. С другой стороны, полагая C = {a, ab, ba}, получаем C1 = {b}, C2 = {a}. Так как C2∩C ≠ ∅, то C не является кодом.
Доказательство. Сначала рассмотрим часть "тогда" утверждения теоремы. Покажем, что если C не является кодом, то одно из множеств C* пересекает C.
Так как C не является кодом, то в C найдутся элементы xv, удовлетворяющие (4.5). Ситуацию можно изобразить так:
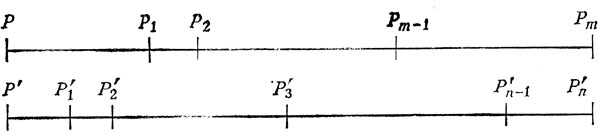
Идея состоит в том, что слово xi1 ... xim записывается на верхней прямой: отрезок PP1 содержит xi1, отрезок P1P2 содержит xi2 и т. д. Аналогично слово xj1, ... xjn, записывается на нижней прямой. Поскольку xi1 ≠ xj1, точки P1 и P1' оказываются на разных вертикалях. (На схеме принято, что xj1 является собственным префиксом xi1.) Снова предполагая минимальность m в (4.5), мы можем заключить, что ни одна из точек верхней прямой (за исключением первой и последней точек) не лежит на одной вертикали с точкой нижней прямой.
Напомним, что слова из Ci+1 получаются либо стиранием префикса, принадлежащего C*, в некотором слове из C, либо стиранием некоторого префикса, принадлежащего C, в слове из Ci. Таким образом, на нашей схеме слово в отрезке P1'P1 принадлежит C1, слово в отрезке P'2P2 принадлежит C2, слово в отрезке P1P'3 принадлежит C3, а слово в отрезке P2P'3 принадлежит C4. Рассуждая далее таким же образом, мы заключаем, что либо xjn принадлежит одному из множеств Ci (это имеет место в описанной выше ситуации), либо xim принадлежит некоторому множеству Ci (последнее имеет место в случае, когда Pm-1 ближе к общей концевой точке, чем P'n-1). В любом случае одно из множеств C, пересекает C.
Рассмотрим теперь часть "только тогда". Предположим, что С является кодом. Прежде всего индукцией по i докажем, что
(4.9)
Действительно, для i = 0 утверждение (4.9) очевидно. (Напомним, что C0 = C.) Предположим, что (4.9) выполнено для i-1, и рассмотрим w∈Ci, i≥1. По определению Ci найдутся слова x∈C и y∈Ci-1, такие, что
По предположению индукции x1y = x2 для некоторых x1 и x2 в C*. Следовательно, либо x1xw = x1y = x2, либо x1yw = x2w = x1x в зависимости от того, какое из равенств (4.10) имеет место. В обоих случаях мы видим, что C*w∩C* ≠ ∅, а это завершает доказательство (4.9).
Чтобы показать, что C не пересекается ни с одним из множеств Ci, i≥1, предположим противное: C∩Ci ≠ ∅ для некоторого i≥1. Следовательно, по определению Ci найдутся такие слова x∈C, x'∈C и y∈Ci-1, что
Рассмотрим первое равенство. В этом случае (4.9) влечет yC*∩C* ≠ ∅ и C*y∩C*≠∅, откуда, согласно лемме 4.2, следует y∈C*. Однако это невозможно, поскольку yx = x' и C есть код.
Следовательно, в (4.11) должно выполняться альтернативное равенство. Отсюда следует, что i≥2, поскольку в противном случае y принадлежало бы C, представляя собой произведение двух элементов из C. Следовательно, существуют y1∈Ci-2 и x"∈C, такие, что
Первое равенство не выполняется, потому что в силу (4.9) и леммы 4.2 y1x'x = x". Таким образом, должно выполняться альтернативное равенство
Если i = 2, то выходит, что некоторый элемент C можно записать как произведение трех элементов из C. Значит, i≥3.
Продолжая в этом духе, мы придем к тому, что i больше любого наперед заданного числа. Отсюда можно заключить, что для всех iC∩Ci = ∅. ▫
|
ПОИСК:
|
При использовании материалов сайта активная ссылка обязательна:
http://informaticslib.ru/ 'Библиотека по информатике'