7. Распознавание образов
Многие из тех полезных функций, которые легко осуществляет мозг, но которые достаточно трудны для вычислительной машины, попадают в категорию распознавания образов. С некоторыми из этих функций человек справляется настолько естественно, что их принято считать само собой разумеющимися. Когда человек, например, читает малоразборчивый рукописный текст или ведет беседу за праздничным столом, он обычно не думает, что выполняет высокоинтеллектуальную задачу. Тем не менее он делает то, что весьма трудно имитировать на машинах. Задачи идентификации слов в письме (или, если угодно, в печатном тексте) или в устной речи относятся к области распознавания образов.
Разумеется, распознавание образов не ограничивается только распознаванием слов: наша повседневная действительность требует распознавания лиц людей, а также множества различных вещей, из которых, скажем, ножи, вилки, ложки, капуста, автомобили - это всего лишь несколько предметов, которые сразу приходят в голову. Первобытным людям (и животным) приходилось распознавать хищников и потенциальную жертву (будь то животное или растение) и т. п.
Системы искусственного распознавания образов называют "ушами и глазами вычислительных машин". Как заметил Оливер Селфридж, без распознавания образов "интеллект" вычислительных машин - нереальное, эфемерное свойство. Иначе говоря, распознавание образов - это особый тип интеллекта; ввод и вывод данных в таких системах осуществляется в текстовом и цифровом виде. Когда данные поступают от оператора-человека, наиболее вероятно, что они будут тщательно отобраны и заведомо окажутся "по существу". Вычислительная машина с "глазами и ушами" лишена преимуществ такого предварительного отбора: она должна сама выбрать нужные данные из того громадного потока информации, которая в основном не имеет прямого отношения к делу, точно так же, как это приходится делать человеку или животному.
Искусственное распознавание образов вводит вычислительную машину в тесный контакт с реальным миром. Исследования в области роботики также направлены на то, чтобы дать машине возможность непосредственно взаимодействовать с реальным миром. Эти два направления придают искусственному интеллекту особый характер, весьма отличный от всего достигнутого ранее.
Распознавание образов может относиться к любой из сенсорных модальностей и не обязательно ограничиваться одной из них. Наибольшее развитие получило распознавание зрительных образов. К числу сравнительно простых относятся работы по распознаванию печатных символов, используемых для "читающих машин", которые применяются в деловых сферах, или тех знаков, которые используются в системах чтения для слепых.
Автоматическое чтение напечатанных символов (оптическое распознавание образов, ОРО) находит гораздо более широкое применение, чем могут представить себе многие люди. Так, многие финансовые и другие документы печатаются таким образом, чтобы их могли прочитать как люди, так и машины. Чтение существенно упрощается, когда буквы в соответствующих текстах напечатаны одним стандартным шрифтом. Тогда распознавание сводится к применению шаблонов.
Пример печатного материала, предназначенного для чтения машиной, представляют собой стилизованные символы на банковских чеках. Они напечатаны магнитными чернилами и читаются не оптическими средствами, а устройствами, регистрирующими магнитное поле. Это в значительной степени делается потому, что в процессе прохождения через банковскую систему чеки обычно густо покрываются печатями и поэтому часть цифр оказывается замазанной. Поскольку для резиновых печатей используются обычные, немагнитные, чернила, они не препятствуй ют магнитному чтению.
Символы на чеках продуманы так, что допускают очень простой метод чтения: они сканируются с помощью вертикальной щели устройством, подобным считывающей или записывающей магнитофонной головке. Выходной сигнал щели пропорционален количеству магнитных чернил. Форма этого сигнала, обрисовываемая по мере того, как щель проходит символ слева направо, для каждого символа различна, что позволяет машине распознавать, какой символ был прочитан. Распределение магнитных чернил по вертикали для чтения машиной не существенно, но важно для того, чтобы эти символы были понятны людям. При таком способе работы отпадает необходимость в том, чтобы считывающая головка располагалась очень точно по вертикали: это очень удобно, поскольку позволяет сделать щель намного больше, чем высота символа.
Конечно, одну и ту же информацию на чеке можно было бы представить двумя различными способами: магнитными чернилами для чтения машиной и обычной печатью для чтения людьми. Однако использование единого символа, читаемого и машиной, и человеком, дает экономию в затратах на печать и, кроме того, исключает подозрение, что эти два представления не соответствуют друг другу.
Кроме чеков большое число других финансовых документов, например счета за газ и электричество, содержат цифры, которые при поступлении в учетную организацию считываются методами ОРО. Эти цифры напечатаны шрифтом, который специально разработан для использования методов ОРО, но вместе с тем легко читается и людьми.
Машинное чтение существенно затрудняется, если символы на документах не напечатаны определенным, заранее установленным шрифтом и если в тексте встречаются печатные цифры, вписанные человеком. Существуют читающие машины, предназначенные для чтения разных шрифтов и записей от руки (но печатными буквами); однако добиться того, чтобы машина читала обычные рукописные символы, весьма трудно. Очень сложной при этом оказывается проблема сегментации, т. е. решение вопроса о том, где кончается одна буква и начинается другая.
Для печатных символов и печатных букв, вписанных от руки, была разработана методика, которая обеспечивала машинное чтение с незначительными ошибками. (Строго говоря, некоторая доля ошибок и отказов имеется, поскольку допускается, что вместо распознавания символа машина может "заявить": "Я не знаю".) Почтовое ведомство Великобритании проделало работу по внедрению систем автоматического распознавания почтовых кодов для автоматической сортировки почты. В этом случае не произойдет ничего страшного, если машина для какой-то небольшой части почтовых отправлений сообщит: "Я не знаю". Тогда эти отправления просто придется подвергнуть ручной сортировке, как и ту часть отправлений, где код вообще не указан.
В связи с применениями машинного чтения в деловой сфере полезно помнить, что почти всегда существуют какие-то варианты, позволяющие обойтись и без применения читающих машин (вроде использования двух видов печати числа на банковских чеках). В Советском Союзе, где введена система числовых почтовых кодов, конверты и почтовые открытки выпускаются с нанесенным на них трафаретом из пунктирных линий, как показано на рис. 12. Цифры на коде записывают, обводя соответствующие линии трафарета (рис. 13). На обратной стороне конвертов показано, как следует "строить" каждую из десяти цифр (рис. 14).

Рис. 12. Сетка из пунктирных линий для нанесения почтового кода на конвертах, выпускаемых в Советском Союзе
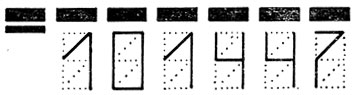
Рис. 13. Сетка с почтовым кодом Института проблем передачи информации АН СССР, г. Москва
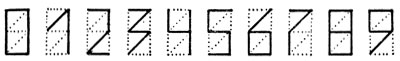
Рис. 14. Образец написания цифр почтового кода, напечатанный на отвороте конверта
В устройстве, предназначенном для чтения почтовых кодов, записанных в такой форме, необходимо лишь правильно расположить трафарет (чему помогают нанесенные на трафарет жирные черточки), а затем определить, какие из линий были обведены.
Одним из первых применений метода ОРО была машина ERA*, использованная для чтения кассовых чеков. Она предназначалась для широкой сети мелких магазинов. Идея состояла в том, чтобы данные, нанесенные на чеки, и были записями о покупках, произведенных в отдельных магазинах, которые можно было бы обрабатывать на центральной вычислительной машине.
* (Аббревиатура от англ. Electronic Reading Automation - электронный читающий автомат. - Прим. перев.)
Казалось бы, эту проблему можно решить иначе: снабдить каждый кассовый аппарат устройством записи на магнитную или бумажную ленту той информации, которая чернилами наносилась на чеки, Вследствие большого числа кассовых аппаратов, разбросанных по различным магазинам, оказалось дешевле установить одну читающую машину, а кассовые аппараты оставить такими, какие они есть. (Но на практике все выглядит значительно сложнее. Чтобы ERA работала с определенной степенью точности, необходимой в деловых операциях, требовалось высокое качество печати на чеках кассовых аппаратов.)
Распознавание символов - это лишь один из видов распознавания зрительных образов. В частности, ввиду повышенного интереса к роботике сегодня основное внимание уделяется анализу сцен, тогда как прежде обычно предполагалось, что изображение, подлежащее распознаванию, расположено изолированно на каком-то фоне. При распознавании образов, как правило, удается обеспечить это путем предварительной подготовки изображения, однако в других случаях приходится узнавать объекты, частично загороженные другими объектами и расположенные на достаточно сложном фоне.
Другая сенсорная модальность - автоматическое распознавание речи - имеет много потенциальных приложений, и поэтому ей уделяется очень большое внимание. Герои научно-фантастических фильмов чаще всего общаются с вычислительными машинами, используя обычную речь. При этом зрителям легче следить за происходящим на экране, чем в случае, если бы диалог человека с вычислительной машиной велся с помощью клавиатуры. Но кроме того, в этом находит отражение тот факт, что для людей речь - наиболее естественное средство общения.
Без сомнения, устройство распознавания речи, способное работать, не имея никаких ограничений на входные сигналы, - дело далекого будущего. В действительности же заставить такое устройство работать на основе лишь речевого входного сигнала - задача вряд ли выполнимая. (У человека процесс распознавания речи действует не изолированно, а опирается на механизмы, связанные с пониманием смысла.)
Но в том случае, если требуется узнать слово из небольшого словаря возможных слов, автоматическое распознавание речи представляется делом вполне реальным, если устройство распознавания может быть "натренировано", т. е. каким-то образом приспособлено к данному конкретному диктору. Даже устройство, способное различать произносимые вслух десять цифр, может обеспечить полезный диалог с вычислительной машиной по телефонной линии. Подобными устройствами были снабжены коммерческие вычислительные установки. (Генерирование речевых сигналов на выходе вычислительной машины осуществить сравнительно просто; соответствующие устройства имеются в продаже, причем покупатель может выбрать по желанию мужской или женский голос.)
Устройство, способное распознавать слова из небольшого словаря, может оказаться полезным во многих ситуациях, где оператор должен отдавать машине приказы, когда его руки чем-то заняты. Такое устройство полезно рабочему, который благодаря ему получает возможность отдавать довольно однообразные команды типа "вверх", "вниз", "влево", "вправо", "стоп" цеховому подъемному крану. Аналогичная ситуация возникает при сортировке почтовых посылок, когда оператор помещает посылку на ленту конвейера и в то же время называет город, в который она посылается. В отсутствие устройства автоматического распознавания речи здесь пришлось бы держать второго оператора, который должен был бы нажимать кнопки, передавая информацию о пункте назначения оборудованию, направляющему посылки с конвейера в соответствующие почтовые мешки. При автоматическом распознавании речи можно обойтись одним оператором.
Эванс из Национальной физической лаборатории (г. Теддингтон) разработал систему распознавания речи, способную реагировать на словарь в несколько сотен слов. Он рассматривает свою систему в связи с ситуацией, когда команда самолета получает какую-то информацию в ходе полета. Секрет состоит в том, что в каждый момент времени система чувствительна лишь к небольшому подмножеству слов словаря, зависящему от данного контекста. Например, при некоторых вопросах, которые система может задать пользователю, единственным разумным ответом может быть одна из десяти цифр - в таком случае система будет чувствительна только к этим десяти словам. У человека распознавание речи существенно зависит от контекста, и принципы, на которых Крис Эванс построил свою систему, есть не что иное, как простая форма использования зависимости от контекста.
Люди обладают также способностью к распознаванию тактильных образов, и этой проблеме в последнее время стали уделять заметное внимание в работах по искусственному интеллекту. Существуют также формы распознавания, не связанные ни с какой сенсорной модальностью, например распознавание врачом некоего комплекса симптомов, указывающего на конкретное заболевание, или распознавание метеорологом комплекса данных, указывающего на степень вероятности какой-то конкретной погоды.
Распознавание образов и обучение
Распознавание образов - это область, где наиболее отчетливо видно, что человеческие способности зависят от обучения и опыта. Ребенок учится распознавать буквы главным образом на многочисленных примерах, показ которых каждый раз сопровождается точной и правильной классификацией. Следовательно, процесс распознавания образов неразрывно связан с обучением, и вполне естественно рассматривать их совместно.
В принципе устройство распознавания зрительных образов могло бы действовать посредством исчерпывающе полной классификации. Предположим, изображения формируются на своего рода сетчатке, которая представляет собой некий массив светочувствительных элементов. Обычно на вход системы распознавания образов поступают сигналы от подобного массива. В одной из систем массив содержал 32 элемента по ширине и 48 элементов по высоте, т. е. всего 1536 элементов. Но даже для такой грубой сетки (которая намного грубее телевизионного изображения) при условии, что каждый элемент создает двоичный сигнал (черное или белое, без серого), число возможных образов составляет 21536, или примерно 10460. Для обеспечения исчерпывающей классификации распознающее устройство должно располагать возможностью классификации каждого из этого громадного числа образов.
При таком большом числе возможных образов работа путем исчерпывающей классификации нереальна. Даже при достаточном объеме памяти для ее заполнения посредством определенной процедуры обучения потребуется эксперимент колоссальных (и неосуществимых) масштабов.
На практике системы распознавания действуют таким образом, что прежде всего обрабатывают изображение с целью выделения признаков, получая тем самым некоторое новое представление с заметно уменьшенным информационным содержанием. Эти признаки могут либо представлять собой определенные участки изображения, либо иметь достаточно общий характер, скажем давать ответ на вопрос: "Имеется ли на изображении горизонтальная черта?"
Оливер Селфридж описывает весьма общую схему обучающейся системы, предназначенной для распознавания образов. Он назвал ее пандемониум, подчеркнув тот факт, что эту схему лучше всего представлять работающей с сильным использованием параллелизма. Элементы пандемониума названы демонами. Это относительно автономные сущности, подобные демону Максвелла в термодинамике.
На самом нижнем уровне находятся демоны данных, или демоны изображения (рис. 15), которые играют роль светочувствительных элементов сетчатки глаза. На самом верхнем уровне находится демон решения, который определяет выход всей системы в целом, а именно указывает, к какой категории относится узнанный образ. Ниже демона решения имеется некоторое число демонов понимания, каждый из которых соответствует одной из узнаваемых категорий.
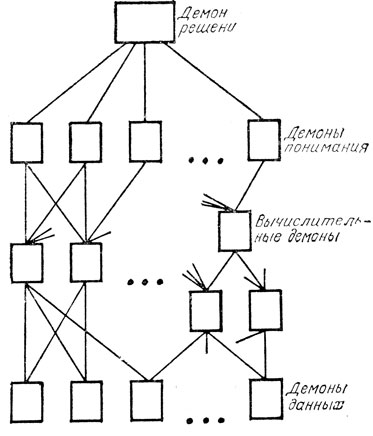
Рис. 15. Пандемониум Селфриджа
Идея состоит в том, что каждый демон понимания должен определить меру соответствия образа, поступившего на демоны данных, с категорией образа, представленного этим демоном понимания. Чем лучше это соответствие, тем более сильный сигнал посылается к демону решения, который выбирает самый сильный из поступивших сигналов.
Можно было бы сделать так, чтобы демоны понимания получали входные сигналы от демонов данных непосредственно, но, поскольку в требованиях различных демонов понимания имеется некоторое сходство, более экономично включить в процесс распознавания образов этапы предварительной обработки, которые могут быть одинаковыми для нескольких демонов понимания. Такую роль играют вычислительные демоны, соответствующие устройствам извлечения признаков в других схемах.
Пандемониум представляет собой обучающееся устройство, и каждый демон понимания постоянно осуществляет настройку своего способа комбинации выходов вычислительных демонов при образовании своего выхода, направляемого демону решения. Эта подстройка определяется обратной связью с окружающей средой, указывающей на правильность или полезность принимаемого решения. Обратная связь может реализоваться либо в форме общего указания на полезность (степень достижения цели, используемой в целевой функции для подъема на холм), либо в форме входного сигнала, поступающего от "учителя", указывающего ретроспективно правильную классификацию. Если обратная связь относится к последнему типу, то для контроля процесса обучения можно использовать алгоритм тренировки персептрона (гл. 8). Селфридж считает, что все демоны понимания вычисляют взвешенные суммы сигналов, поступающих от вычислительных демонов, так что i-й демон понимания вычисляет свой выходной сигнал Di следующим образом:
где суммирование ведется по всем вычислительным демонам, a dj - выходной сигнал j-го вычислительного демона.
Процесс настройки в демоне понимания связан с изменением весов wij. Как мы уже отмечали, способы настройки должны зависеть от характера обратной связи системы в целом, Если это скалярная оценка степени достижения цели, то настройка основывается на процедуре подъема на холм, как это описано в статье Селфриджа.
Когда эти веса таковы, что принимаемое решение близко к оптимальному, то для любого вычислительного демона становится возможным вычислить его ценность для всей системы в целом. Ценность вычислительного демона определяется тем, насколько используется его выход. Подходящей мерой ценности j-го вычислительного демона могла бы быть величина
Такое вычисление ценности позволяет производить изменения в используемом множестве вычислительных демонов: можно, например, автоматически исключать малоценные демоны и заменять их другими. Таким образом, самосовершенствование пандемониума приобретает самоорганизующийся характер, т. е. не сводится просто к самооптимизации путем подстройки параметров.
Селфридж предлагает два способа получения новых вычислительных демонов. Оба они основаны на том соображении, что, по-видимому, целесообразно создавать демоны, имеющие что-то общее с теми уже существующими демонами, которые доказали свою высокую ценность. Эти методы называются слиянием и делением с мутацией.
Слияние просто означает, что выходные сигналы двух демонов высокой ценности комбинируются между собой. Если эти выходные сигналы носят логический характер типа "все или ничего", то существует десять способов* их комбинирования, которые порождают новый сигнал "все или ничего". Селфридж предлагает выбирать одну из десяти возможностей произвольным образом.
* (Так как от двух переменных имеется 16 различных функций, но две из них константы 0 и 1, а четыре функции одного переменного. - Прим. ред.)
На рис. 15 показано, что на вход одного из вычислительных демонов поступают сигналы от двух других демонов: это демон, который, возможно, возник в результате слияния. Для того чтобы два входных демона имели подходящие меры ценности, необходимо, конечно, чтобы демон, получающий от них сигналы, вносил вклады в суммы, определяющие ценности составляющих демонов. Величина этих вкладов, как предполагается, должна зависеть от величины его собственной суммы, определяющей ценность. Можно убедиться, что обратная связь, по которой поступают вклады в меры ценности в сети такого сорта, осуществляется через достаточно длинную цепочку элементов.
Автор настоящей книги [2] занимался изучением этой значащей обратной связи (и некоторых ее вариантов), считая ее весьма важной характеристикой самоорганизующейся сети. Хотя Селфридж постулирует слияние, он ничего не говорит о необходимости такой обратной связи по цепочкам элементов. Общее представление о необходимости сохранения путей "доставки" полезной информации хорошо согласуется с наблюдаемым поведением живых систем. Хорошо известно, например, что мышцы укрепляются при тренировке и становятся слабее в отсутствие ее. По-видимому, то же самое можно сказать и о костях. Установлено, что сенсорные окончания также развиваются при их активном использовании.
Другим способом генерации новых вычислительных демонов является деление с мутацией. Суть этого метода состоит в том, что должны формироваться новые демоны, подобные (но, конечно, не идентичные) тем, ценность которых оказалась высокой. На практике трудно добиться нужной степени подобия. Необходимо, чтобы демоны модифицировались существенным образом и чтобы возникали качественно новые типы. Представление демонов должно быть таким, чтобы в результате мутаций, характер вычислительного демона не разрушался полностью, что обычно происходит в программе, записанной на машинном языке, при изменении одного или пары двоичных разрядов, но чтобы в то же время поведение демона могло оказаться качественно новым. Эта проблема аналогична той, что связана со способами введения качественно новых членов в с. о. ф. в программе Сэмюэля для игры в шашки. Данная проблема имеет также отношение к принципу эвристической связи Минского.
При начальной формулировке принципа пандемониума Оливер Селфридж обсуждал, в частности, его применение к автоматическому восприятию азбуки Морзе, передаваемой вручную. Он обнаружил, что длительности точки, тире и интервала часто не связаны между собой стандартным образом (в соответствии с которым тире в три раза продолжительнее точки, интервалы в пределах кода, представляющего один символ, имеют ту же длину, что и точка, а интервалы между символами имеют ту же длину, что и тире).
Правильная интерпретация символов азбуки Морзе должна основываться на анализе длины передачи, в которой они встречаются. В пандемониуме это достигается благодаря тому, что входные сигналы для демонов данных представляют длину сообщения, простирающегося по обе стороны от символа, который подлежит интерпретации.
Применение метода пандемониума к распознаванию образов описано Селфриджем и Нейссером [3]. Выходными сигналами вычислительных демонов являются ответы на вопросы типа того, что мы задавали ранее: "Имеется ли в символе горизонтальная черта?" Возможны и другие вопросы подобного сорта, например: "Какая половина данного изображения более зачернена, верхняя или нижняя?", "Является ли фигура выпуклой или вогнутой?" и т. д.
В результате было достигнуто распознавание изображений с малой вероятностью ошибки. Однако в этом практическом приложении метод деления с мутацией не использовался. В заключение своей статьи Селфридж и Нейссер признают, что важнейшие проблемы, по существу, остались нерешенными: "Наиболее важный процесс обучения остался незатронутым: ни одна из имеющихся программ не в состоянии вырабатывать свои собственные тестовые критерии. Эффективность всех этих критериев неизбежно ограничивается изобретательностью или произволом программистов. Вряд ли мы понимаем, как можно снять эти ограничения. А пока "искусственный интеллект" остается лишь искусной хитростью".
Распознавание фиксированного шрифта
Необходимость в выделении признаков посредством вычислительных демонов или эквивалентных им систем с другими названиями возникает только тогда, когда возможны вариации одного и того же изображения или символа. В большинстве коммерческих приложений систем распознавания образов шрифт, используемый для символов, хорошо известен и распознавание является лишь вопросом использования эталонов. В этом случае необходимо просто ввести некоторый допуск на расхождение между символом и шаблоном с учетом дефектов печати и помарок на бумаге.
Можно вычислить меру соответствия между двумя изображениями, одним из которых является распознаваемое входное изображение, а другое хранится в памяти в виде эталона. Такую меру иногда называют пространственной (или двумерной) кросс-корреляцией. Подходящей мерой может служить доля общей площади, в которой два изображения согласуются (т. е. в обоих изображениях совпадают черное или белое), когда их накладывают друг на друга после того, как они приведены в стандартное положение. Идентичные изображения сливаются в одно.
В читающей машине, предназначенной для определенного шрифта, можно получить кросс-корреляцию входного символа с хранимыми в памяти устройства эталонами, причем распознавание определяется наиболее хорошо согласующимся эталоном. Если ни один из хранящихся в памяти эталонов не дает хорошего соответствия или хотя бы соответствия, явно превышающего соответствия входного изображения с другими эталонами, то машина может ответить: "Я не знаю".
Шрифт, которым печатаются цифры на счетах за газ R электричество, тщательно подобран таким образом, чтобы пространственная кросс-корреляция между символами этого шрифта была небольшой.
Распределенные признаки
Джон Паркс из Национальной физической лаборатории предложил систему распознавания образов, предназначенную для идентификации шрифтов и написанных от руки печатных букв. Система предназначена для широкого применения в тех сферах деятельности, где существует постоянная потребность в переносе данных с документов в память вычислительной машины.
Система Паркса основана на представлении символа в виде массива 32×48 небольших квадратных элементов (иногда называемых пикселями). Этот массив просматривается с целью обнаружения отрезков прямых, которые могут быть ориентированы различным образом. Просмотр осуществляется средствами электроники, но делается точно так, как если бы на каждый участок исходного массива, содержащий 7×7 пикселей, накладывалась решетка, состоящая из 7×7 фотоэлементов.
В действительности решетка движется по изображению слева направо, перемещаясь каждый раз на один пиксель, после чего опускается на один пиксель вниз и снова перемещается слева направо и т. д. В каждом положении регистрируется выходной сигнал каждого фотоэлемента и производятся определенные сравнения между группами фотоэлементов.
На рис. 16 показано, какие сравнения могут осуществляться между подмножествами фотоэлементов: среднее из выходных значений, помеченных знаком "плюс", сопоставляется со средним из значений, отмеченных знаком "минус". Если изображение более темное под ячейками "плюс", то мы получаем данные относительно возможности присутствия в этой области горизонтального отрезка. Строки фотоэлементов взяты длиной в пять элементов, хотя они могли бы иметь длину и 7 элементов. Это позволяет не слишком жестко отбирать линии по направлению.
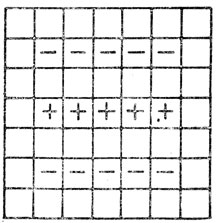
Рис. 16. Связи точек отсчета решетки при поиске горизонтальных отрезков прямой
Аналогичное сопоставление данных, полученных от фотоэлементов, составляющих вертикаль, выделяет отрезки линий, расположенные примерно вертикально. Сравнение таких элементов по диагонали (как показано на рис. 17) для одного из двух возможных направлений определяет наклонные линии.
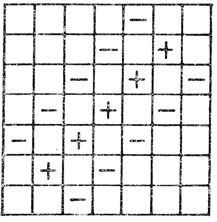
Рис. 17. Связи точек отсчета решетки при поиске отрезков прямых, идущих слева направо, снизу вверх
Таким образом, исходное множество пикселей, каждый с указанием яркости, превращается в массив ячеек, ряд из которых несет информацию о наличии отрезка прямой, идущего в том или ином определенном направлении. (Если в какой-то ячейке имеются данные, свидетельствующие о наличии отрезка, одновременно идущего как бы в двух или трех направлениях, то допускается, чтобы в ней хранилась информация сразу о нескольких направлениях.)
Новый массив опять просматривается с помощью решетки 7×7, которая при определенных условиях указывает на выявление некоторого морфологического признака символа. Таким признаком может быть окончание линии (допускалось восемь ориентации), изменение направления (допускались острые, прямые и тупые углы, каждый в восьми положениях), слияние или пересечение. С учетом их разнообразия и ориентации в системе имеются 54 различных морфологических признака.
На рис. 18 показаны необходимые условия, при которых элементы под решеткой в ходе второго сканирования могли бы установить окончание горизонтальной прямой, идущей слева.
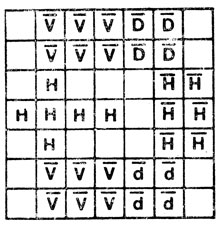
Рис. 18. Решетка, используемая на втором этапе сканирования, целью которого является обнаружение горизонтальной прямой, идущей слева. Ячейки, помеченные символом Н, должны занимать положение, в котором при первом просмотре был обнаружен горизонтальный отрезок. Аналогично символ V означает наличие вертикального отрезка (если таковой имеется). Символ D означает, что отрезок идет слева направо, снизу вверх, символ d соответствует наклону отрезка в другую сторону. Там где буквенный символ помечен черточкой, в ячейке может быть все, что угодно, за исключением указанной там буквы. Этот на первый взгляд произвольный критерий для определения морфологического признака явился результатом большой экспериментальной работы; он должен быть и не слишком жестким, и не слишком расплывчатым
Представление символа сводится к перечню морфологических признаков с указанием их примерного положения в области изображения. Довольно простая программа, составленная на основе обширной статистики, собранной на свободно написанных цифрах, позволяет затем переходить от списка признаков к довольно надежному узнаванию.
Первоначальный просмотр изображения с помощью решетки фотоэлементов и обнаружение отрезков прямых очень хорошо соответствую! процессу, который происходит в зрительной коре мозга животных на начальных этапах обработки изображений. Это обстоятельство обсуждается далее, в гл. 12.
Слуховое восприятие
Произнесенное слово, предложение или какая-либо последовательность звуков могут быть преобразованы в двумерную картинку без сколько-нибудь значительной потери информации. Такая картинка называется звуковой спектрограммой. Обычно по горизонтальной оси в ней откладывается время, а по вертикальной - частота (скажем, от 50 до 3000 или 4000 Гц). Звуковая энергия, переданная на определенной частоте в некоторый момент времени, отображается путем зачернения соответствующего участка на спектрограмме.
Звуковые спектрограммы, построенные в реальном масштабе времени, использовались для того, чтобы дать возможность глухим людям "слышать", наблюдая за экраном дисплея. Пользуясь этим вспомогательным средством, глухой человек оказывается в состоянии участвовать в разговоре.
Методы распознавания произносимых слов могут быть весьма сходны с методами распознавания символов и других зрительных образов. Признаки, выделяемые по спектрограмме, по-видимому, должны быть проще, чем морфологические признаки в схеме Паркса. По всей вероятности, признаками здесь могут быть случаи обнаружения достаточно большой энергии в той или иной частотно-временной ячейке. Определенная трудность состоит в том, что слова "эластичны" во временной области: слова, имеющие одно и то же значение, могут быть произнесены быстро или медленно, со слогами укороченными или растянутыми. Такой эластичности почти нет в частотной области - гласным звукам соответствуют вполне определенные форматные частоты.
Как отмечалось ранее, искусственное распознавание речи может быть достигнуто при условии, что словарь возможных слов невелик. В системе распознавания слов могут быть использованы принципы персептрона (см. следующую главу), что позволяет обучить систему голосу конкретного говорящего лица.
Система органов слуха человека обладает поистине удивительными свойствами: люди могут вести беседы и в условиях шумной вечеринки, и по телефону при наличии сильных искажений и помех. Восприятие речи человеком не ограничивается лишь распознаванием слов или фонем. Оно включает в себя целый ряд сложных взаимосвязанных процессов, протекающих на многих уровнях. Об этом мы будем говорить подробно в следующей главе в разделе "Инженерия знаний".
Кластерный анализ
До сих пор, говоря о проблеме распознавания образов, мы предполагали, что нам заранее известны категории (классы) тех образов, которые предстоит распознать. Более гибкая система, предназначенная для обучения распознаванию, должна сама открывать эти категории. Некоторые системы, предназначенные для распознавания символов, были способны к "обучению без учителя". Иными словами, при предъявлении большого числа вариантов букв такая система должна быть в состоянии решать для себя, что в поступивших на ее вход сигналах представлено 26* различных образов (или 52, если учитывать прописные и строчные буквы).
* (Речь идет об английском алфавите, состоящем из 26 букв. - Прим. перев.)
Любую схему такого типа, работающую без обратной связи, указывающей на полезность создаваемой классификации, следует каким-то образом несколько "подтолкнуть" в направлении получения требуемого результата. В отсутствие обратной связи, свидетельствующей о целесообразности результата, буквы точно так же могли быть расклассифицированы, например, на широкие и узкие или на содержащие замкнутые области и не содержащие таковых.
В некоторых подходах к распознаванию образов используется метрическая информация - и входные значения могут быть представлены точками в фазовом пространстве. Например, если отложить по осям координат, как это сделано на рис. 19, рост и вес людей, то из приведенной выборки следует, что люди разделились на две группы; точки соответствующие этим группам, разделены на рисунке пунктиром. Нарисовав такую линию, можно распознавать новых людей в зависимости от их роста и веса как членов той или иной группы.
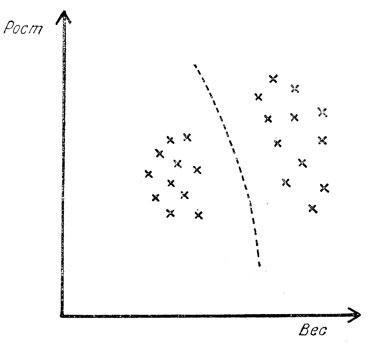
Рис. 19. Диаграмма рассеяния, каждая точка которой соответствует какому-то лицу и определяется его ростом и весом. Пунктирная линия разделяет две группы лиц
По определению разделяющих линий, подобных той, что изображена на рис. 19, существует обширная литература (см., например, Себестьен [5]). В трехмерном пространстве можно найти соответствующую разделяющую поверхность, а при более высокой размерности - разделяющую гиперповерхность. Иногда разделяющая линия (или поверхность) выводится на основе некоторой известной классификации. Если классификация строится на основе самих данных (как в ситуации, представленной на рис. 19), то говорят о кластерном анализе.
|
ПОИСК:
|
При использовании материалов сайта активная ссылка обязательна:
http://informaticslib.ru/ 'Библиотека по информатике'