б) Первый алгоритм Гомори
В этом алгоритме впервые была реализована идея метода отсечения. Он дает конечную процедуру решения полностью целочисленной задачи линейного программирования, заданной в виде
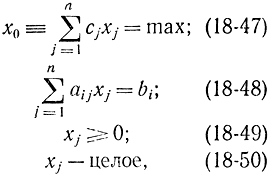
где i = 1, 2 ..., m; j = 1, 2, ..., n.
Выразим функцию цели x0 и все переменные x1 ..., xn через не базисные переменные xj (j ∈ N), где N - множество i индексов, соответствующее не базисным переменным
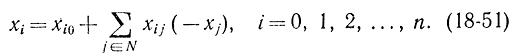
Здесь используются для удобства другие по сравнению с гл. 16 обозначения: xi0 = b'i - свободные члены; xij = a'ij - коэффициенты при j-й не базисной переменной; x0j= с'j, причем xi0 = 0 при i > m, а для i > m
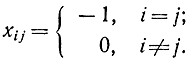
Кроме того, нулевые компоненты в векторах иногда будут опускаться, например, для вектора-столбца
В дальнейшем в формуле (18-51) будет иногда меняться порядок нумерации и не обязательно m первых переменных xi0 будут отличны от нуля. Обозначим через [x] целую часть вещественного числа, равную наибольшему целому числу, не превышающему х. Дробная часть числа определяется как {x} -х-[х]. Допустим, что х (L, с) - решение задачи (18-47) - (18-49) без требования целочисленности. Оно получается приравниванием нулю не базисных переменных в соотношении (18-51), соответствующем последнему этапу симплекс-процедуры xi = xi0. Считая (18-51) решением задачи линейного программирования без требования целочисленности, запишем его в виде
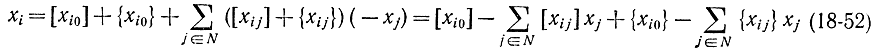
Для любого целочисленного решения, задаваемого формулой (18-51), величина
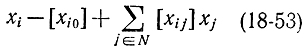
должна быть целой. Но отсюда с учетом (18-52) следует, что
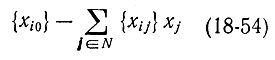
также должна быть целой. Так как величина 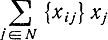 не может быть отрицательной, потому что {xij}≥0, xj≥0 и 0 <{xi0}<1 величина (18-54) не может быть положительным целым числом. Следовательно, любое допустимое решение xj целочисленной задачи (18-47) - (18-50) должно удовлетворять неравенству
не может быть отрицательной, потому что {xij}≥0, xj≥0 и 0 <{xi0}<1 величина (18-54) не может быть положительным целым числом. Следовательно, любое допустимое решение xj целочисленной задачи (18-47) - (18-50) должно удовлетворять неравенству
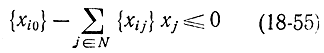
или
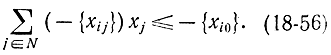
Нетрудно убедиться, что решение задачи (18-47) - (18-49) без требования целочисленности не удовлетворяет неравенству (18-56). Тем самым условие отсечения (18-44) удовлетворяется.
Соотношение (18-56) определяет гиперплоскость, которая отсекает не целочисленное решение, оставляя по другую сторону целочисленное решение. Это правило отсечения и составляет основное содержание метода Гомори. Его следует добавить к ограничениям (18-48), тогда их станет m + 1. Для соотношения (18-56) можно ввести дополни-тельную переменную
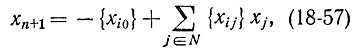
которая будет целочисленной, благодаря чему задача останется полностью целочисленной. Задачу с добавлением ограничения (18-57) будем называть расширенной. Можно показать, что для ее решения нет необходимости решать все заново. Действительно, если обозначить через Аб матрицу, состоящую из r линейно-независимых столбцов матрицы А =|| aij|| исходной системы (18-48), тогда базисное, но не обязательно допустимое решение (18-51) может быть записано в виде
где не базисные переменные xj (j ∈ N) приравнены нулю.
Обозначим через Аб1 матрицу, соответствующую базису расширенной задачи
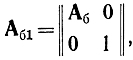
В эти матрицы добавлен вектор-столбец
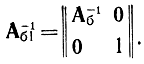
соответствующий дополнительному ограничению (18-57). Теперь базисное решение расширенной задачи запишется как
причем для оптимального решения не целочисленной линейной задачи
где
- вектор оценок, компоненты которого состоят из коэффициентов функции цели при базисных переменных. Это базисное решение недопустимо, так как
Соответствующий базису Аб1 вектор оценок для расширенной задачи будет равен || сб, 0 ||. Далее введем вектор
где aj - j-й вектор-столбец матрицы А и величины zj = сбxj, причем x0j = c'j - cj. Тогда получим, что величины c'j, равные коэффициентам функции цели при j-x переменных для расширенной задачи, будут такими же, как и для оптимального решения линейной задачи (18-47) - (18-49) без условия целочисленности (18-50), так как векторы xj ∈ N для расширенной задачи, которые обозначим через x(1)j, будут равны:
Так как мы исходим из того, что получено оптимальное решение линейной задачи без требования целочисленности, то в соответствии с результатами гл. 16 должно быть zj - cj ≥ 0. Если при этом учесть, что вектор оценки для расширенной задачи имеет вид || сб, 0 ||, то получится базисное, но недопустимое решение расширенной задачи, для которого zj - cj ≥ 0. Но отсюда следует, что выгоднее для поиска решения расширенной задачи использовать двойственный, а не прямой симплекс-метод. При этом, грубо говоря, процедура поиска сокращается в два раза, так как при использовании двойственного симплекс-метода величины zj - cj, равные свободным коэффициентам ограничений двойственной задачи (и коэффициентам функции цели прямой задачи), остаются неотрицательными, что указывает на то, что на всех этапах двойственного симплекс-метода имеет место базисное решение двойственной задачи, не допустимое для прямой. Если применять прямой симплекс-метод, в данном случае пришлось бы выполнить обе половины процедуры, т. е. искать решения среди базисных. Это повлекло бы за собой изменение знаков коэффициентов zj - cj и потерю базисного начального решения двойственной задачи.
Чаще всего для решения расширенной задачи двойственным симплекс-методом достаточно одной итерации. Если решение получится не целочисленным, его повторяют, добавляя новые дополнительные ограничения типа (18-57), выбирая другое значение i. Эта процедура продолжается до тех пор пока не будет получено оптимальное решение целочисленной задачи (18-47) - (18-50). Таким образом получается итерационная процедура отыскания оптимального решения целочисленной задачи линейного программирования. На первом этапе решается задача Q0 линейного программирования без требования целочисленности. Если полученное решение допустимо для целочисленной задачи, то оно является оптимальным. В противном случае переходят ко второму этапу, где решают двойственным симплекс-методом задачу Q1 линейного программирования без требования целочисленности, которая имеет на одно ограничение и одну переменную больше, чем задача Q0. После этого или процесс прекращают, если полученное решение допустимо для целочисленной задачи, или переходят к решению следующей задачи Q2 без требования целочисленности, которая получается в результате построения нового отсечения, и т. д. Если ввести индекс k для обозначения номера очередного этапа (k = 0, 1, ...), то, очевидно, что на первых этапах число дополнительных ограничений будет расти с ростом к. Но можно утверждать, что какое бы большое k ни было, общее число различных дополнительных ограничений (отсечений) в задаче Qk не может превышать n + 1, так как общее число переменных в исходной задаче равно n и, по-видимому, можно ожидать, что общее число отсекающих гиперплоскостей будет равно n (далее они будут повторяться). Дело в том, что вспомогательная переменная хn+k_1 которая является базисной в задаче Qk_1 при построении задачи Qk может быть опущена, так как не обязательно,чтобы выполнялось ограничение, соответствующее этой переменной. Результаты решения задачи Qk_1 учитываются в задаче Qk использованием переменных xj, которые входили в оптимальное решение задачи Qk_1 Исключение лишнего ограничения осуществляется вычеркиванием в симплекс-таблице, составленной для задачи Qk-1, строки и столбца, соответствующих переменной xn+k_1 причем имеется в виду симплекс- таблица типа (n - 1) * (m + 1). В силу того что исходная задача содержит n переменных, после исключения из задачи Qk-1 ограничений, соответствующих вспомогательным переменным xn+v, вошедшим в оптимальное базисное решение этой задачи, получается задача, содержащая не более n дополнительных ограничений. С переходом от нее к задаче Qk необходимо добавить одно ограничение, поэтому общее число ограничений в задаче Qk может превосходить общее число ограничений в задаче Q0 не более чем на n + 1. Гомори доказал, что для случая целочисленных элементов матрицы А и компонент вектора b решение исходной задачи целочисленного линейного программирования можно получить, решив конечное число задач Qk.
Процедура классического метода Гомори отличается от выше рассмотренной двумя положениями. Во-первых, необязательно решать исходную задачу линейного программирования. На первом этапе можно использовать любое базисное, но необязательно допустимое решение, для которого все zj - cj ≥ 0. Во-вторых, в алгоритме Гомори на каждом этапе ищется решение так называемой лексикографической задачи линейного программирования (j-задачи), что позволяет выбирать решение при условии неоднозначности задачи. Вектор х = (x1, х2, ..., хn) = ||xj|| называется лексикографически положительным, т. е. х > 0, если первая отличная от нуля его компонента положительна, т. е. xi ≥ 0, где l = min {j/xj≠0}.
Расширенный план хопт (допустимое решение) называется лексикографически оптимальным, если для всех расширенных планов х разность хопт - х лексикографически положительна: хопт - х0.
В рассмотренных выше процедурах отсутствует правило выбора переменной и соотношения типа (18-52), с помощью которого строится правильное отсечение, когда несколько компонент оптимального вектор-решения исходной линейной задачи не целочисленны. В алгоритме Гомори используется первая по номеру не целочисленная переменная. Если переписать соотношения (18-52) для k-й итерации (этапа) Qk в виде
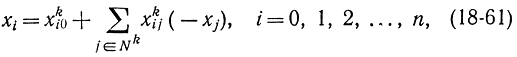
то правило выбора очередной переменной в алгоритме Гомори запишется как
и правильное отсечение на (k + 1)-м этапе запишется в виде
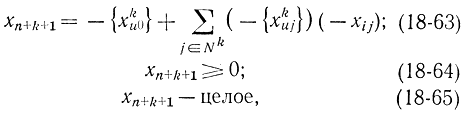
Причем функция цели также включена в систему (18-61) под номером i = 0. Таким образом, если функция цели имеет на нулевом этапе нецелочисленное значение, то первое отсечение строится с ее учетом. Если гарантирована целочисленность функции цели, то правило (18-62) запишется в виде
Для не особого случая задачи линейного программирования, когда множество оптимальных планов не пусто и ограниченно, всегда существует лексикографический оптимальный план задачи.
Лексикографический симплекс-метод, или l-метод, отличается от симплекс-метода главным образом правилом для определения вектора, вводимого в базис, которое на следующем шаге обеспечивает лексикографичность симплекс-таблицы [Л. 97]. Можно показать, что если множество допустимых значений исходной линейной задачи выпукло и ограниченно, то строки симплекс-таблицы
могут быть лексикографически упорядочены, т. е. любой столбец лексикографически положителен:
Как всегда, из базиса выводится наибольшая по модулю отрицательная переменная хр (р ∈ Nб).
Приведенная выше симплекс-таблица приспособлена для двойственного симплекс-метода и имеет n + 1 строк и m столбцов с первой строкой, состоящей из свободных членов x0j. Для определения вводимой в базис переменной последовательно повторяется процедура определения максимальных отношений. Сначала вычисляется
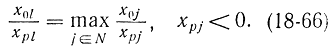
Если l единственно, j-й столбец вводится в базис. В противном случае для тех j, для которых выполняется (18-66), снова вычисляют
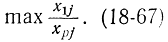
Если максимум достигается при одном j, этот столбец вводится в базис. В противном случае повторяют процесс определения максимума для тех j, для которых он достигается, т. е.
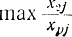
Тем самым однозначно определяется столбец xl вводимый в базис, так как иначе один вектор xj оказался бы пропорционален другому, что невозможно из-за условия независимости векторов ау, составляющих матрицу Аб = || аj||, если учесть, что
В результате этого будет найден вектор
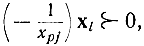
такой, что
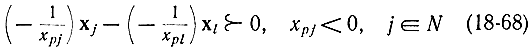
или
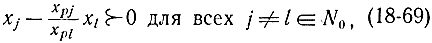
так как в соответствии с формулой (18-67) выбран вектор xl с минимальным значением x0l/|x0l|.
Левая часть формулы (18-69) определяет все компоненты вектора xj следующего этапа Q2 за исключением р-й компоненты. Вектор xj определяет j-й столбец новой симплекс-таблицы, которая получается из предыдущей исключением хр из базиса и включением в него хl. Эта симплекс-таблица согласно (18-69) за вычетом р-й строки будет лексикографически правильной. Ранее было доказано, что исходные симплекс-таблицы задач Q0 и Q1 были лексикографически правильными. Проверим, не нарушит ли р-я компонента лексикографичность вектора xj. Компонента р столбца xj равна xpj/xpl. А вектор-столбец симплекс-таблицы, соответствующий переменной хр, ставший теперь не базисной переменной, имеет компоненты
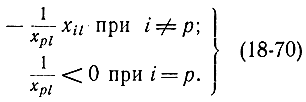
Вектор xl=||xil|| был лексикографически положителен, и его первая, отличная от нуля компонента была положительна. Следовательно, этой компонентой не могла быть xpU которая меньше нуля. Поэтому вектор-столбец, соответствующий переменной хр, благодаря условиям (18-70) будет лексикографически положителен. Так как хрl не является первой ненулевой компонентой хl то в силу (18-70) x≥0, j≠l∈N. Кроме того, для всех j, входящих в новое множество N не базисных переменных, полученное из N исключением j = l и добавлением соответствующего хр имеем хj≥ 0.
Далее, в соответствии с условиями (18-70)
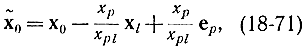
где ер - единичный - вектор с единичной компонентой. Отсюда
Это означает, что при лексикографическом симплекс-методе вектор х0 лексикографически уменьшается.
Данное утверждение справедливо для любого этапа k, так как в задаче Qk+1 (n + 1)-я компонента исходного вектора х0 равна соответствующим компонентам вектора х0 в задаче Qk.
При добавлении на каждом шаге ограничений, осуществляющих очередное отсечение, число компонент вектора xj увеличивается. В результате исключения ограничений, вспомогательные переменные которых вошли в базис, условие xj≥0, j ∈ N не нарушится. Действительно, ранг матрицы X = || xij || = || xj || = || aij || в задаче (18-61), состоящий из r+1 столбцов xj, равен r + 1. После каждого этапа (итерации) первые n + 1 уравнений останутся такого же типа, как и (18-61). Поэтому мало вероятно, что n + 1 компонент некоторого вектора xj обратятся в нуль и лексикографическая положительность этого вектора всегда будет определяться n + 1 его первыми компонентами. Это обеспечивает конечность процедуры выбора вектора, вводимого в базис, которая сводится к перебору n строк. Случай, когда все xpj≥0, j ∈ N, не рассматривается, так как в нем двойственная задача имеет неограниченное решение, а прямая целочисленная задача не имеет допустимого решения
Обозначим симплекс-таблицу, соответствующую k-y этапу, через
где Qn = {0, 1, ..., n) - множество индексов; Nk0=Qn-Nkб или Nk0 = {0, 1, ..., n} - Nб, - множество индексов, соответствующее не базисным переменным Nk и нулевой переменной на k-м этапе. Тогда с переходом к (k + 1)-у этапу строка xn+k+1, задаваемая формулой (18-63), приписывается снизу к таблице Tk. В результате получаем недопустимую только по строке xn+k+1 и так называемую j-нормальную таблицу, в которой любой вектор-столбец xj лексикографически положителен:
т. е. первая" ненулевая компонента этого вектора положительна. К этой таблице применим j-метод, причем, как уже указывалось, переменная хn+k+1 (k ≥ 0) выводится из базиса сразу же после введения ограничения xn+k+1 ≥ 0, где xn+k+1 = βk - akx. После вывода переменной xn+k+1 из базиса соответствующая строка вычеркивается, а после ввода в базис переменной xl (l≥ n + 1) соответствующая строка не восстанавливается. Размер симплекс-таблицы на каждом шаге ограничен числом (n + 2) * (m+ 1), где n - число переменных xj в исходной задаче; n - число не базисных переменных на k-м этапе, которое совпадает с числом не базисных переменных в исходной задаче, причем один столбец отводится на свободные члены xi0 [формула (18-58)], (n + 1)-я строка соответствует переменным х1, х2, ...,хn, одна строка - переменной xn+k+1 (в момент ее введения в базис). Если в ходе дальнейших вычислений переменная xn+k+1 снова попадает в базис, то соответствующая строка в симплекс-таблице не восстанавливается и в дальнейших вычислениях эта переменная не участвует.
Такие сокращения вычислительных процедур возможны потому, что дополнительные ограничения аkх ≤ βk, связанные с правильными отсечениями, используются только как средство отсечения не целочисленного решения и перехода от k-го этапа к (k + 1)-му этапу. Сами ограничения нас как бы не интересуют, так как их влияние учтено через введение новых базисных переменных.
Очевидно, что в методе Гомори можно выделить большие итерации, которые начинаются с введения дополнительного ограничения (18-63), и малые итерации симплекс-метода для решения задачи линейного программирования с этим ограничением.
Пример 18-3. Решим с помощью алгоритма Гомори следующий численный пример:
Введением неотрицательных целочисленных переменных х3 и x4 каноническая форма рассматриваемой системы приобретает вид:
Соответствующая j-задача будет определяться следующим образом:
- Опорный план
хисх = {0, 0, 0, 38, 2}.
- Номера базисных переменных
Nбисх = {3, 4}.
- Номера не базисных переменных
Nисх= Q - Nисхб = {1, 2}.Не базисные переменные выразим через базисные по формуле (18-66):х3 = 38 - 2x1 - 9x2;х4 = 2 - х 1 + 2х2.
Для получения лексикографической симплекс-таблицы исходного j-псевдоплана введем новую переменную
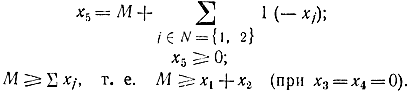
Решая систему уравнений, с учетом целочисленности переменных х1 и х2 имеем строгое неравенство
Следовательно,
Лексикографически правильная симплексная таблица 18-1 [Tисх(0)] имеет вид:
где xисх(0) - коэффициенты в правых частях уравнений; Q0 = {0, 1, 2, 3, 4, 5} - расширенное множество индексов переменных; N0 = {0, 1, 2} - расширенное множество индексов не базисных переменных; Nб = {3, 4, 5} - номера базисных переменных.

Таблица 18-1
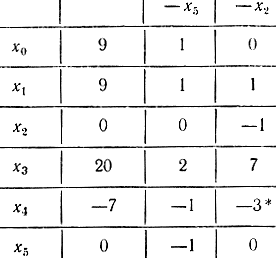
Таблица 18-2
Найдем переменную, выводимую и вводимую в базис, по правилам (18-62) и (18-17) соответственно. Направляющим элементом, помеченным в табл. (18-1) звездочкой, является
Переменная x1 выводится из базиса, вводимой в базис переменной является х5. Элементы симплекс-таблицы при этом преобразуются по следующим соотношениям:
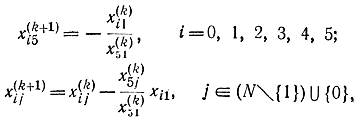
где знак " \ " означает вычитание множеств. В результате преобразований, соответствующих двойственному циклу, l-нормальная таблица приобретает вид табл. 18-2 [Тисх(1)]
В соответствии с первым шагом алгоритма Гомори решаем l-задачу, состоящую в проверке условия допустимости, нахождении переменной, выводимой из базиса, переменной, вводимой в базис, и пересчете таблицы, аналогично предыдущим преобразованиям. При этом k* = 4, l* = 2, направляющим элементом таблицы является х42 = -3, а индекс j принимает значения
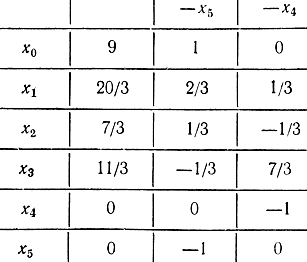
Таблица 18-3
В результате этого двойственного цикла, когда новая переменная вводится в базис, приходим к исходной j-задаче, данные которой отражены в табл. 18-3.
Максимизация расширенного плана (l-задача) имеет вид:
- l-псевдоплан
хисх={x0, x1, x2, x3, x4, x5} = {9, 20/3, 7/3, 11/3, 0, 0};
- номера базисных переменных
Nбисх(2) = {j, 2, 3};
- номера не базисных переменных
Nисх(2)(N\{l}) ≚{k} = {4, 5},Nиcx(2) = {0, 4, 5}.
Для табл. 18-3 повторяем общую итерацию l-метода; l-псевдоплан удовлетворяет условию допустимости и, следовательно, является l-оптимальным планом. В соответствии с алгоритмом Гомори переходим ко второму и последующим шагам.
Второй шаг. Проверяем, является ли l-оптимальный план целочисленным. План не целочислен, переходим к третьему Шагу.
Третий шаг. Полагаем k = 0 (нулевая большая итерация).
Четвертый шаг. Выбираем наименьшую по номеру строку табл. 18-3, которой соответствует не целочисленная компонента
Пятый шаг. Строим правильное отсечение:
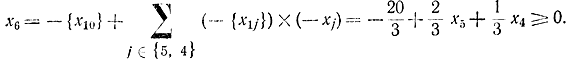
Шестой шаг. Приписываем строку, соответствующую новому ограничению, к таблице T0 (табл. 18-3) и получаем таблицу Т0 (табл. 18-4). Формирование нового ограничения и переход к решению очередной l-задачи отражает прямой цикл алгоритма.
Седьмой шаг. К l-задаче, записанной в виде l-нормальной таблицы Т0, применяем l-метод и производим описанные ранее процедуры.
Результаты последующих преобразований отражены в табл. 18-5, табл. 18-6, табл. 18-7. l/-оптимальный план является целочисленным; таким образом, получаем максимум линейной формы z = 8 при х1 = 6 и х2 = 2.
Геометрическая иллюстрация решения целочисленной задачи дана на рис. 18-6. Пунктиром показаны прямые, осуществляющие правильные отсечения.
Следует заметить, что практика решения задач с помощью первого алгоритма Гомори показывает практически малую его эффективность из-за большого количества требуемых итераций.
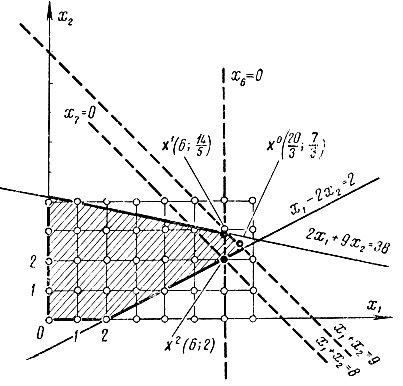
Рис. 18-6. Пояснение к примеру 18-3
Так, в задачах, в которых без требования целочисленности было необходимо 20 итераций, для получения решения в соответствии с первым алгоритмом Гомори для целочисленной задачи даже 2 000 итераций еще не дали сходимости [Л. 89]. Поэтому на практике очень часто используют другие алгоритмы решения линейных задач целочисленного программирования, основанные на некоторых эвристических принципах, используемых для построения отсечения. Хотя сходимость этих алгоритмов в общем случае не доказана, они очень часто обеспечивают достаточно быструю сходимость.

Таблица 18-4

Таблица 18-5

Таблица 18-6

Таблица 18-7
Так, в отличие от алгоритма Гомори дополнительную отсекающую . плоскость (18-51) можно выбирать так, чтобы она пересекала ось xj (j ∈ N) в точках, как можно более удаленных от начала координат. При этом переменные xj, удовлетворяющие уравнению (18-51), будут принимать максимальные значения, что соответствует наибольшему продвижению в область допустимых решений от точки х = || х0, 0 ||. В соответствии с этой идеей выбирается такая переменная, для которой отношение {xl0}/{xlj} имеет максимальное значение. Другая идея основана на одновременном построении всех сечений, соответствующих не целочисленным переменным, и включении их в расширенную задачу. Число отрицательных переменных в этой задаче будет равно числу дополнительных ограничений.
В случае применения ЦВМ при решении задач целочисленного программирования возникают дополнительные трудности, связанные с проблемой округления. Дело в том, что решение, вычисленное ЦВМ, может быть в результате округлений не целочисленным.
|
ПОИСК:
|
При использовании материалов сайта активная ссылка обязательна:
http://informaticslib.ru/ 'Библиотека по информатике'