5.2. Проблемы эквивалентности для DOL-систем
Проблемы языковой и последовательностной эквивалентности для DOL-систем несколько различны, хотя и тесно связаны между собой. Различие состоит в том, что две DOL-системы могут порождать один и тот же язык в разном порядке; типичным примером служат две системы:
Тесная связь этих двух проблем убедительно иллюстрируется тем фактом, что еще за несколько лет до того, как была установлена разрешимость этих проблем, было доказано, что разрешимость одной из них влечет разрешимость другой.
Сначала докажем разрешимость проблемы последовательностной эквивалентности для DOL-систем. Фактически большая часть необходимого для этой цели аппарата содержится в гл. 4. Приведем сначала несколько примеров, выявляющих возникающие здесь трудности.
Рассмотрим две DOL-системы
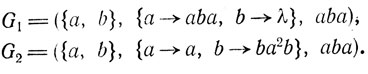
Легко видеть, что
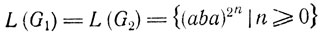
и что S(G1) = S(G2) состоит из всех слов в L(G1) в порядке возрастания длины. Следовательно, G1 и G2 языково и последовательностно эквивалентны.
Специфические соображения, подобные проведенным в предыдущем примере рассуждениям, не распространяются на общий случай. Что касается последовательностной эквивалентности, можно по одному порождать слова из двух последовательностей S(G1) и S(G2), каждый раз проверяя, совпадают ли i-е слова в двух последовательностях для i = 1, 2, ... . Эта процедура составляет "полуалгоритм" для неэквивалентности: если G1 и G2 последовательностно неэквивалентны, то процедура завершается правильным ответом. Но если G1 и G2 в действительности последовательностно эквивалентны, то процедура не заканчивается никогда.
Чтобы превратить эту процедуру в алгоритм, надо уметь вычислять число C(G1, G2), такое, что если первые C(G1, G2) элементов в S(G1) и S(G2) совпадают, то S(G1) = S(G2). Оказалось, однако, что эта задача очень трудна, хотя, с другой стороны, не исключено, что в качестве C(G1, G2) достаточно взять удвоенный объем алфавита G1 и G2; во всяком случае, не известен ни один пример, противоречащий этому предположению. Действительно, следующий пример (который можно распространить на большие алфавиты, см. упр. 1) является "худшим" из известных примеров двух DOL-систем G1 и G2, таких, что S(G1)≠S(G2), но наибольшее (возможное при данном объеме алфавита) число первых слов в этих двух последовательностях совпадает.
Рассмотрим две DOL-системы G1 и G2 с аксиомой ab. Продукциями для G1 (соответственно для G2) являются
Читатель может проверить, что в последовательностях S(G1) и S(G2) первые три слова совпадают, но дальнейшие слова различаются.
После этих примеров перейдем к общему решению проблемы последовательностной эквивалентности для DOL-систем. Будем говорить, что два морфизма g и h (определенные на ∑*) равны на языке L⊆∑*, если g(w) = h(w) выполняется для всех w из L. Очевидно, что g и h равны на L тогда и только тогда, когда L⊆E(g, h), где E - множество совпадения, определенное в гл. 4.
Прежде всего докажем две леммы.
Лемма 5.1. Существует алгоритм, позволяющий выяснить, равны ли два морфизма на данном регулярном языке R1.
1 (Относительно этой леммы см. замечание переводчика в конце главы.- Прим. ред.)
Доказательство. Пусть A - конечный детерминированный автомат, представляющий R⊆∑*. Рассмотрим пути в A из начальной вершины в одну из заключительных вершин. Пусть какой-либо из них содержит цикл, т. е. пусть для непустого слова w и некоторых слов w1 и w2 все слова w1wnw2, n≥0, принадлежат R. Тогда мы утверждаем, что либо
либо g и h не равны на R. Действительно, если (5.2) не выполнено, то для достаточно больших n
(
Но поскольку все слова w1wnw2 принадлежат R, из (5.3) следует, что g и h не равны на R.
Рассмотрим теперь подмножества Ek(g,h) языка E(g,h), определенные в упр. 4.8. Пусть t - число вершин в A, и пусть
где a пробегает ∑. (Здесь рядом с фигурными скобками стоит символ абсолютной величины.) Выберем из множеств Ek(g, h) такое, что k≥u(t - 1)/2.
Мы можем выяснить, имеет ли место включение
(Указанная возможность следует из того, что оба этих языка регулярны; см. упр. 4.8, а также теоремы 2.7 и 2.8.) Если (5.4) выполняется, то ясно, что g и h равны на R. Обратно, если g и h равны на R, то (5.2) выполняется для всех слов w, таких, что соответствующие им пути из начальной вершины в заключительную содержат петлю. Из этого факта следует, что (5.4) выполняется. В самом деле, мы предположили, что R⊆ E(g, h), и нам известно, что, согласно (5.2), абсолютная величина разности |g(x)| - |h(x)|, где x - префикс некоторого слова из R, не может превышать выбранного нами числа k. Это доказывает правильность (5.4). ▫
Лемма 5.2. Проблема выяснения, содержится ли данный DOL-язык L в данном регулярном языке R, разрешима.
Доказательство. Пусть L = L(G), где G = (∑, h, w) есть DOL-система, и пусть R может быть представлен конечным детерминированным автоматом A. Без потери общности можно предположить, что ∑ является также алфавитом пометок (т. е. входным алфавитом) автомата A.
Построим теперь последовательность автоматов A (h), A(h2), A(h3), ... следующим образом. Для каждого A(hi) множество вершин, начальная и заключительные вершины, а также алфавит пометок совпадают с соответствующими объектами в автомате A. (Из этого факта следует, что все автоматы в нашей последовательности не могут быть различными; в дальнейшем эта информация окажется весьма полезной.) В A (hi) существует помеченная буквой а стрелка из вершины s в вершину s' тогда и только тогда, когда в A существует помеченный словом hi(a) путь из s в s'. Очевидно, что это условие определяет автомат A(hi). Кроме того, R = hi(Ri), где Ri - язык, представляемый автоматом A(hi).
Поскольку не все автоматы в нашей последовательности различны, найдутся такие числа i и j, i<j, что A(hi) = A(hj). Этот факт влечет равенство
для всех k. Следовательно, каждый автомат из нашей исходной последовательности автоматов является элементом последовательности
(Автоматы из (5.5) не обязательно все различны.)
Пусть теперь R1 - пересечение языков, представляемых автоматами (5.5) и автоматом A, т. е.
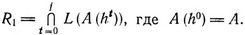
Очевидно, что можно эффективно построить автомат Ль представляющий язык A1. (Это следует из теоремы 2.7 и того факта, что j можно вычислить эффективно.)
Мы утверждаем, что L⊆R тогда и только тогда, когда w∈L(A1). (Очевидно, последнее условие разрешимо.) Действительно, L⊆R тогда и только тогда, когда hi(w)∈L(A) для каждого i≥0. Последнее условие выполняется тогда и только тогда, когда для каждого i≥0 имеем w∈L(A(hi)), а это в свою очередь эквивалентно включению w∈L(A1)).▫
Теперь мы готовы установить первый основной результат, в конечном итоге ведущий к разрешимости проблемы последовательностной эквивалентности для DOL-систем.
Теорема 5.3. Проблема равенства двух данных элементарных морфизмов на данном DOL-языке разрешима.
Доказательство. Чтобы решить вопрос о равенстве двух элементарных морфизмов g1 и g2 на языке L(G), где G = (∑, h, w) - некоторая DOL-система, мы поступаем следующим образом. В силу теоремы 4.13 язык E(g\,g2) регулярен. Пусть R0, R1, R2, ... - эффективное перечисление всех регулярных языков над ∑. (Очевидно, такое перечисление возможно. Например, можно рассмотреть сначала конечные детерминированные автоматы с одной вершиной, затем с двумя вершинами и т. д.)
Рассмотрим теперь два полуалгоритма, один для равенства, а другой для неравенства. Последний очевиден: берем последовательность
и проверяем, имеет ли место равенство
g1(hi(w)) = g2(hi(w))).
Если морфизмы g1 и g2 не равны на L(G), то этот полуалгоритм завершается правильным ответом.
(i + 1)-й шаг полуалгоритма для равенства состоит в проверке с использованием леммы 5.1, равны ли g1 и g2 на Ri и в случае положительного ответа в последующей проверке, содержится ли L(G) в Ri. Последнюю проверку можно осуществить с помощью леммы 5.2, и из положительного ответа следует равенство g1 и g2 на L(G). (В случае отрицательного ответа на какой-либо из этих вопросов мы переходим к (i+2)-му шагу.) Если морфизмы g1 и g2 равны на L(G), то этот полуалгоритм завершается правильным ответом.
Алгоритм для теоремы 5.3 заключается в параллельном применении этих двух полуалгоритмов (т. е. в чередовании их шагов).▫
Вместо абстрактной последовательности Ri, i = 0, 1,2, ..., в предыдущем доказательстве можно рассмотреть конкретную последовательность регулярных языков Ei(g1, g2), определенную в упр. 4.8. Тогда (i+1)-й шаг в нашем полном алгоритме состоит в проверке равенства g1(hi(w)) = g2(hi(w)) и в случае положительного ответа в проверке включения L(G)⊆Ei(g1, g2). Конечно, мы получили бы очень простой алгоритм, основываясь лишь на лемме 5.2, если бы могли эффективно построить регулярный язык E(g1, g2). (Напомним, что построение автомата А в доказательстве теоремы 4.9 не было эффективным.)
Проблему последовательностной эквивалентности для DOL-систем можно свести к теореме 5.3. Основная идея этого сведения заключается в декомпозиции морфизма произвольной DOL-системы таким образом, чтобы достаточно было проверить равенство элементарных морфизмов на DOL-языке. В этом плане оказывается полезной следующая лемма.
Лемма 5.4. Пусть h1 и h2 - морфизмы из ∑* в ∑*. Тогда существуют последовательность i1, ..., im элементов из множества {1,2} и морфизмы f, p1, p2, такие, что
причем морфизмы p, элементарны. Кроме того, последовательность i1, ..., im и морфизмы f, p1, p2 можно построить эффективно.
Доказательство. Если морфизмы h1 и h2 элементарны, то выберем pj = h], j = 1, 2. В качестве f возьмем тождественный морфизм, а в качестве последовательности элементов из {1,2} - пустую последовательность.
Предположим теперь, что хотя бы один из морфизмов h1 и h2 не элементарен. Рассмотрим составленное из h1 и h2 произведение, допускающее максимальное упрощение
Более подробно, мы предполагаем, что (5.7) выполняется для
f: ∑*→∑1* и g: ∑*1→∑*,
где подалфавит ∑1 имеет меньшую мощность, чем ∑, и если
то мощность алфавита ∑2 не меньше мощности ∑1.
Теперь положим pj = hjg, j = 1, 2. Тогда (5.7) влечет (5.6). Кроме того, минимальность ∑1 гарантирует элементарность p1 и p2. Действительно, если hjg допускает упрощение hjg = g'g", то получаем
где произведение в правой части можно упростить с помощью алфавита меньшей мощности, чем у ∑1.
Это построение эффективно, потому что при данной произвольной последовательности i1, ..., im можно проверить, выполняется ли (5.6) для некоторого элементарного морфизма pj. (Вопрос об элементарности данного морфизма легко разрешается, см. упр. 2.) Таким образом, мы просто систематически перебираем все последовательности до тех пор, пока не найдем подходящую. Первая часть доказательства гарантирует, что в конце концов мы получим требуемый результат.
Теперь у нас есть все необходимое для установления основного результата.
Теорема 5.5. Проблема последовательностной эквивалентности для DOL-систем разрешима.
Доказательство. Вез потери общности предположим, что даны две DOL-системы вида
т. е. системы с совпадающими начальными словами и алфавитами. Обозначим слова в последовательностях S(Gi), i = 1, 2, следующим образом:
Пусть теперь i1, ... , im, p1, p2, f удовлетворяют лемме 5.4 для h1 и h2. Введем обозначения
и рассмотрим DOL-системы
(Заметим, что ∑ может содержать буквы, не входящие фактически в S(Gij). Однако морфизмы gi определены на всем ∑.)
Очевидно, если S(G1) = S(G2), то для всех j, 0≤j≤m, имеет место
Справедливо также обращение этой импликации, что можно показать при помощи следующего рассуждения от противного. Предположим, что выполняется (5.8), но существует натуральное число n, такое, что w(1)n≠w(2)n, и возьмем наименьшее из таких натуральных чисел. Очевидно, что n не может быть меньше m или равно ему, так как в этом случае первые элементы последовательностей S(G1n) и S(G2n) были бы различны, что противоречит (5.8). Таким образом, n≥m+1. Выбрав теперь такое натуральное t, что
мы видим, что (t+1)-е слова в последовательностях S(G1n1) и S(G2n1) различны, что также является противоречием.
Таким образом, для завершения доказательства нам нужно только установить разрешимость равенств (5.8). С этой целью рассмотрим фиксированное j и положим
Рассмотрим также морфизмы p1, p2, f, введенные ранее в этом доказательстве. Можно предположить, что wf(1) = wf(2) и, следовательно, f (w1(1)) = f(w1(2)), поскольку в противном случае S(H1)≠S(H2), и вопрос решен.
Рассмотрим теперь DOL-системы
где ∑i - тот подалфавит алфавита ∑, с помощью которого упрощается морфизм gi. (В данном случае мы должны взять подалфавит, поскольку морфизм fpi не обязательно определен на всем ∑.)
По теореме 2.3 можно выяснить, равны ли морфизмы p1 и p2 на L(K1. Но из определений непосредственно следует, что p1 и p2 равны на L(K1) тогда и только тогда, когда S(H1) = S(H2).▫
Доказательство разрешимости проблемы языковой эквивалентности для DOL-систем не содержит никаких существенно новых идей в плане теории языков и поэтому опускается. Существенным в этом доказательстве является сопоставление заданной DOL-системе G = (∑, h, w) систем вида
где "период" p достаточно велик, чтобы гарантировать однозначный порядок слов, так что становится применимой теорема 5.5. В процессе работы алгоритм пытается уменьшить период ценой увеличения "первоначального беспорядка" q. Что касается деталей доказательства следующей теоремы, мы отсылаем читателя к упр. 5.
Теорема 5.6. Проблема языковой эквивалентности для DOL-систем разрешима.
|
ПОИСК:
|
При использовании материалов сайта активная ссылка обязательна:
http://informaticslib.ru/ 'Библиотека по информатике'