5.3. Результаты о неразрешимости
Используем теперь сведение к проблеме соответствия Поста, чтобы доказать, что теорему 5.6 нельзя распространить на OL-системы. В то же время мы докажем неразрешимость проблемы языковой эквивалентности для контекстно-свободных грамматик (см. гл. 2). Оба результата вытекают из приведенной ниже леммы 5.7.
Сентенциальной формой (sentential form) грамматики мы будем называть любое слово α, такое, что S⇒*α для некоторого начального символа S. Таким образом, сентенциальные формы могут включать как терминалы, так и нетерминалы, в то время как язык L(G), порождаемый грамматикой 6, состоит только из слов в терминальном алфавите.
Лемма 5.7. Проблема, состоящая в выяснении того, порождают ли две данные контекстно-свободные грамматики одно и то же множество сентенциальных форм, неразрешима.
Доказательство. Будем рассуждать от противного, предполагая, что существует алгоритм, выясняющий, совпадают ли множества сентенциальных форм, порождаемые двумя контекстно-свободными грамматиками. Тогда этот алгоритм можно применить следующим образом для решения проблемы соответствия Поста, что и обнаружит ложность сделанного предположения.
Возьмем произвольный пример
проблемы соответствия Поста, где мы положили
Рассмотрим три языка L, Lg и Lh над алфавитом ∑∪∑1∪{#}. По определению L = ∑*#∑*1. Язык Lg является подмножеством языка L, состоящим из всех слов L, за исключением слов вида
где mi(x) обозначает зеркальный образ (mirror image) слова x, т. е. x, записанное в обратном порядке. (Если x есть λ или состоит только из одной буквы, то mi(x) = x.) Язык Lh определен подобным же образом с заменой в (5.9) морфизма g на h.
Очевидно,
(Напомним, что E(g, h) считается пустым, если состоит лишь из пустого слова.) Опираясь на сделанное нами вначале предположение, построим теперь алгоритм, выясняющий, имеет ли место равенство L = Lg∪Lh. В силу (5.10) этот алгоритм применим также к проблеме соответствия Поста. Определим следующим образом две контекстно-свободные грамматики G1 и G2. Единственным начальным символом для обеих грамматик будет S0, а нетерминальным (терминальным) алфавитом будет
Ниже перечислены продукции грамматики G1. В этом списке предполагается, что a пробегает ∑, a, b пробегает 1.
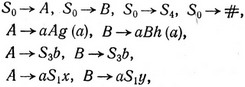
где x (соответственно y) пробегает все слова над ∑1 имеющих длину меньше |g(a)| (соответственно |h(a)|), включая пустое слово;
где x (соответственно y) пробегает множество всех слов над ∑i, имеющих длину |g(a)| (соответственно |h(a)|, но отличных от g(a) (соответственно h(a));
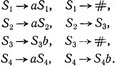
Продукции G2 получаются из продукций G1 заменой двух продукций S1→# и S3→# на продукцию S4→#. Этим определение G1 и G2 завершается.
Теперь можно непосредственно проверить, что G1 и G2 порождают одни и те же сентенциальные формы, за возможным исключением слов, состоящих только из терминальных букв - терминалов. Поэтому, поскольку мы можем решить вопрос о совпадении множеств сентенциальных форм, порождаемых G1 и G2, мы можем также решить вопрос, верно ли, что L(G1) = L(G2).
Очевидно, что L(G2) = L. В действительности L выводится по правилам G2 с использованием только нетерминалов S0 и S4. В силу (5.10) и того факта, что мы можем разрешать проблему равенства L(G1) = L(G2), для завершения леммы 5.7 достаточно показать, что
Чтобы установить это равенство, покажем, что имеет место включение в обоих направлениях. Пусть слово w принадлежит L(G1). Надо показать, что w∈Lg∪Lh. Это верно, если w=#. Поэтому предположим, что w≠#. Так как S4 нельзя устранить, заключаем, что первая продукция, применявшаяся в выводе w, есть S0→A или S0→B. В силу симметричности ситуации достаточно рассмотреть первый случай и показать, что w принадлежит Lg. Последовательность различных нетерминалов, появляющихся в выводе w из A, должна быть одной из следующих:
В каждом из этих случаев легко проверить, что w∈Lg. (Часть слова, идущая за центральным маркером #, в первом случае оказывается "слишком длинной", а во втором - "слишком короткой". Третий случай указывает на ошибку в сопоставлении a и g(a).)
Предположим, наоборот, что w∈Lg∪Lh, скажем w∈Lg. Если w∈#∑*1, то в грамматике G1 слово w порождается с помощью продукции
Таким образом, можно предположить, что
Пусть u - наибольшее натуральное число в отрезке 0≤u≤k, такое, что w' = w1g(aiu ... ai1). Предположим сначала, что u = 0, т. е. w' нельзя представить в виде w' = w1g (ai1) Если |w'|<|g(ai1)|, то слово w порождается продукциями.
Если |w'|≥g (ai1)|, то положим w' = w"x, где |x| = |g(ai1) и x≠g (ai1). Слово w может порождаться также продукциями
Теперь предположим, что u = k. В этом случае w' имеет вид
Кроме того, w1≠λ, так как в противном случае слово w не принадлежало бы языку Lg. Теперь w может порождаться продукциями
Предположим, наконец, что 1≤u<k. Тогда существует такое слово w1, что
но не существует такого слова w2, что
Если |w1|<|g (aiu+1)|, то w порождается продукциями
В противном случае w1 можно записать в виде w1 = w3x, где |x| = |g(aiu+1)| и x≠g(aiu+1). (Напомним, что w' нельзя представить в виде (5.13).) Теперь слово w порождается продукциями
Итак, мы показали, что во всех случаях слово w принадлежит L(G1).▫
Приведенное доказательство показывает, что в общем случае мы не в состоянии решить проблему равенства множеств сентенциальных форм, порождаемых грамматиками G1 и G2 (поскольку не существует соответствующего алгоритма). Грамматики G1 и G2 можно преобразовать в OL-системы, добавляя к ним продукции c→c для каждого терминального символа c. Следовательно, проблема языковой эквивалентности для OL-систем неразрешима. (В действительности она остается неразрешимой даже для частного класса OL-систем, а именно для систем, имеющих вид G1 и G2. Такие OL-системы, например, не используют λ-продукций.)
Но приведенное выше доказательство показывает также неразрешимость проблемы L(G1) = L(G2), когда G1 и G2 рассматриваются как контекстно-свободные грамматики. Следовательно, проблема языковой эквивалентности для контекстно-свободных грамматик неразрешима. Из наших рассуждений в действительности следует, что эта проблема остается неразрешимой даже для линейных грамматик, когда ни в одной продукции правая часть не содержит более одного нетерминала.
Таким образом, королларием* леммы 5.7 является следующий результат.
* (Под королларием теоремы здесь подразумевается утверждение, вытекающее не только из формулировки этой теоремы, но и из ее доказательства (этим королларий отличается от следствия). - Прим. перев.)
Теорема 5.8. Проблема языковой эквивалентности для OL-систем неразрешима. Проблема языковой эквивалентности для контекстно-свободных грамматик также неразрешима.
Оценки и отзывы на https://ozersklust.com помогут сделать правильный выбор.
|
ПОИСК:
|
При использовании материалов сайта активная ссылка обязательна:
http://informaticslib.ru/ 'Библиотека по информатике'