6.3. Порождение морфизмами рекурсивно перечислимых языков
Справедливость результата, аналогичного теореме 6.7, для семейства рекурсивно перечислимых языков следует из самого определения этого семейства. Действительно, каждый язык, слова которого могут быть перечислены посредством некоторой эффективной процедуры ("эффективной" в интуитивном смысле), порождается также грамматикой типа 0. Это утверждение (обычно называемое тезисом Чёрча* будет использовано в приведенном ниже доказательстве, хотя последнее можно было бы провести и без него, см. упр. 10. Дальнейшее обсуждение тезиса Чёрча читатель может найти
* (Точнее было бы назвать его тезисом Поста Подробнее о соотношении между вычислимостью и рекурсивной перечислимостью см. [УС*].- Прим. ред.)
Теорема 6.8. Существует язык L0 типа 0 со следующим свойством: для каждого λ-свободного языка L типа 0 существует такой морфизм h, что L = h-1(L0).
Доказательство. Без потери общности можно считать, что языки типа 0 порождаются грамматиками, нетерминальные (соответственно терминальные) алфавиты которых являются собственными начальными отрезками бесконечного множества
с единственным начальным символом S1. Пусть G1, G2, ... - перечисление всех таких грамматик в порядке возрастания общего числа вхождений всех букв в продукции. Каждой грамматике G1 мы сопоставим слово вида
где p1, p2, ..., pk суть продукции Gi. Таким образом, слова вида (6.27) содержат два специальных символа # и → и, кроме того, символы из (6.26). Все эти буквы кодируются теперь словами над алфавитом {a1, a2). (Например, можно представить все буквы в виде a1ai2a1. Значения i = 1, 2 зарезервируем для специальных символов, а остальные нечетные и четные значения i будем использовать для кодирования нетерминалов и терминалов соответственно.) Применяя такое кодирование к (6.27), получаем слово
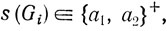
соответствующее грамматике Gi.
Для i≥1 определим теперь морфизм hi: ∑*i→{a1, a2}*, где ∑i - терминальный алфавит Gi. Пусть b∈∑i - произвольная буква, а e(b) - ее код (построенный, как указано выше) в алфавите {a1, a2). Положим
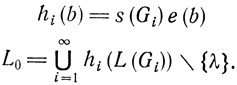
Язык L0 эффективно перечислим, например, посредством процедуры, n-й шаг которой состоит в перечислении всех непустых слов, порождаемых грамматиками G1, ..., Gn с выводами длины ≤n. Согласно тезису Чёрча, L0 есть язык типа 0.
С другой стороны, если L = L(Gi) и λ∉L, то L = hi-1 (L0). Этот результат получается сразу, поскольку "ярлык" s(Gi) наличествует только в тех словах из L0, которые содержатся в L(Gi). ▫
Заметим, что при λ∈L язык hi-1(L0) равен языку L\{λ}. Заранее нельзя сказать, какой из языков L(Gi) не содержит λ. На самом деле, проблема принадлежности λ данному языку L(Gi) неразрешима.
Как мы уже отмечали, теорема 6.8 обусловлена универсальной природой грамматик типа 0. Обсудим теперь некоторые более конкретные морфические представления языков типа 0. Оказывается, что множества совпадения очень полезны для таких представлений.
Мы хотим представить произвольный рекурсивно перечислимый язык как морфический образ множества совпадения. Этот результат давал бы представление всех рекурсивно перечислимых языков исключительно с помощью морфизмов! Само по себе это требование в какой-то мере слишком сильное по следующей причине. Каждый язык совпадения является "звездным языком", т. е. имеет вид L = L1* а, стало быть, звездными являются и языки h(L). Однако если мы предусмотрим надлежащий механизм для отбора подмножества из языка совпадения, то такое морфическое представление действительно окажется возможным. Очень простой способ, подходящий для этой цели, состоит в пересечении языка совпадения с регулярным языком. Этот способ широко используется в различных разделах теории языков. Другой возможный способ преодоления указанной трудности приведен в упр. 11.
Если ∑ и ∑1 - алфавиты, ∑⊆∑i, то морфизм H∑: ∑1*→∑* задается равенствами
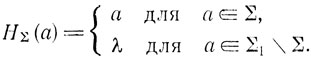
Таким образом, H∑ стирает все, кроме букв из ∑.
Теорема 6.9. Для каждого рекурсивно перечислимого языка L⊆∑*T. существуют два морфизма h1 и h2 и регулярный язык R, такие, что
Доказательство. Рассмотрим произвольный рекурсивно перечислимый язык L, порожденный грамматикой G типа 0, где ∑N и ∑T - нетерминальный и терминальный алфавиты, S∈∑N - начальный символ, а множество продукций P состоит из
pi: αi→βi, i = 1, ..., n.
(Таким образом, мы каждой продукции приписываем ее имя pi.)
По существу за конструкцией h1, h2 и R стоит следующая идея. Каждое слово в L является последним словом в некотором выводе D в рамках G. На слове D', похожем на D, морфизмы h1 и h2 удовлетворяют равенству
Однако h1 "пробегает быстрее", чем h2, префиксы D', и h2 "догоняет" h1 только в самом конце. Морфизм H∑ стирает все, кроме конечного результата. Наконец, R гарантирует, что рассматриваются только слова соответствующего вида.
Изложим теперь подробности более формально. Мы используем "штрихованные варианты" алфавитов так же, как и ранее: ∑' есть алфавит {a'|a∈S}, а w' - слово, полученное из w приписыванием штриха каждой букве. Рассмотрим алфавиты
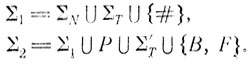
Морфизмы h1, h2: ∑2*→∑1* задаются таблицей
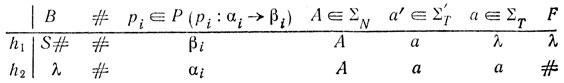
Далее, регулярный язык R задается регулярным выражением
Мы должны еще показать, что выполняется (6.28). Сначала приведем пример. Рассмотрим грамматику с продукциями
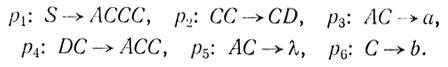
Слово ab принадлежит языку, порожденному этой грамматикой, что видно из вывода
Теперь поставим этому выводу в соответствие слово
и заметим, что H(a,b)(w) - ab и что w ∈ R. Далее, h1(w) = h2(w), где обе части равны слову, полученному из (6.29) заменой ⇒ на # и добавлением # в конце.
Возвращаясь к доказательству, мы сначала покажем, что произвольное слово x∈L содержится также в правой части (6.28). Для этого нам нужно лишь доказать по индукции следующее утверждение: каждый раз, когда
является выводом в G, существует слово w∈B(V*1PV1*#)+, такое, что
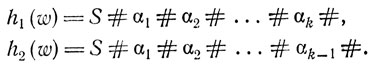
Очевидно, что этого достаточно, так как если αk = x является терминальным словом,то
Для k=1 можно выбрать w = Bp1#, где p1 - имя продукции S→α1. В качестве гипотезы индукции примем, что утверждение истинно для k. Значит, для произвольного вывода (6.30) существует слово w, удовлетворяющее требуемым условиям. Удлиним (6.30) дополнительным звеном
и продукция p: α→β принадлежит P. Пусть слово β'1 (соответственно β2) получается из β1 (соответственно из β2) приписыванием всем терминалам штрихов (при этом нетерминалы остаются без изменений). Тогда слово wβ'1pβ'2# удовлетворяет требуемым условиям для более длинного вывода. Это завершает шаг индукции.
Обратно, рассмотрим произвольное слово
Поскольку слово w∈R, его можно записать в виде
Заметим, в частности, что слово x должно стоять перед F, потому что x = H∑T(w), а все буквы, не принадлежащие ∑T, стираются морфизмом H∑T.
Теперь используем равенство h1(w) = h2(w). Если w есть префикс w, то одно из слов h1(w) и h2(w) должно быть префиксом другого. Ситуация легко исследуется просмотром всех вхождений #. Буква В вносит одно вхождение # в h1-образ, но не вносит ни одного в h22-образ. Каждое из слов wi вносит одно вхождение # в конце h1- и h2-образов. Следовательно, h1 "движется быстрее", т. е. h2(w) является префиксом h1(w).
В частности, имеем
для некоторых слов wi(1), и, следовательно,
Так как h2 "догоняет" h1 при отображении xF, должно иметь место wk(1) = x.
Слово wi, i = 1, ..., k, дает "вклад" wi(1)# в h1-образ и "вклад" w(i)i-1 в h2-образ. (Здесь мы полагаем w0(1) = S.) Поскольку wi∈V1*PV1*#, отсюда следует, что
где α→β - продукция в P. Но это означает, что мы имеем вывод
где wk(1) = x, и, следовательно, x∈L.▫
Теорему 6.9 можно применить также для характеризации языков типа 0 при помощи весьма простого генератора. Такой генератор, называемый языком перетасовки двойников, мы сейчас определим.
Рассмотрим алфавит ∑ одновременно с его "подчеркнутым" вариантом ∑. (Как и в случае со штрихами,  При этом w обозначает слово, полученное из
При этом w обозначает слово, полученное из 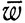 надчеркиванием всех букв.) Язык перетасовки двойников L∑ определяется равенством
надчеркиванием всех букв.) Язык перетасовки двойников L∑ определяется равенством
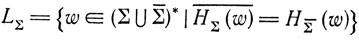
и, таким образом, состоит из слов, каждое из которых представляет собой произвольную перетасовку некоторого слова x∈∑* и его "надчеркнутого" двойника 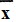 . Если морфизм
. Если морфизм
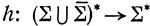
определен как
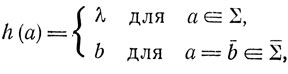
то очевидно, что L∑ = E(h, H∑).
Теорема 6.10. Для каждого рекурсивно перечислимого языка L⊆∑*T. существуют язык перетасовки двойников L∑ и регулярный язык R1, такие, что
Доказательство. Рассмотрим представление (6.28), данное в теореме 6.9. Можно считать, что ∑2 и ∑1, т. е. алфавиты области определения и множества значений морфизмов h1 и h2, не пересекаются. (Чтобы достичь этого, мы просто переименуем буквы ∑1, что не окажет никакого влияния на (6.28).)
Положим теперь ∑ = ∑2∪∑1. Пусть g - морфизм, удовлетворяющий равенству
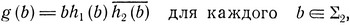
и пусть язык R1 получается из языка g(R) введением в его слова букв из  в произвольном порядке. Таким образом, R1 состоит из слов вида
в произвольном порядке. Таким образом, R1 состоит из слов вида
здесь bi - буквы из , а xj - - слова (возможно, пустые). Очевидно, язык R1 регулярен.
Равенство (6.31) является теперь прямым следствием (6.28) и равенства
которое непосредственно следует из определений. ▫
В теореме 6.10 алфавит 2 зависит от языка L. Эта зависимость не существенна. Более сильные варианты этой теоремы приводятся в упр. 3 и 14.
Результаты, приведенные в этой главе, показывают, что язык двойной перетасовки и язык Дика играют похожие роли в теориях языков типа 0 и контекстно-свободных языков соответственно. В заключение мы без доказательства приведем следующую довольно своеобразную теорему о представлении (доказательство в общих чертах намечено в упр. 15). Символами ρ и D соответственно обозначаются определенные выше отображение Дика и язык Дика "с инициалами" (см. (6.12)). Что касается ρ, то мы рассматриваем надмножество исходного алфавита 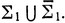 Дополнительные символы в этом надмножестве не затрагиваются отображением ρ.
Дополнительные символы в этом надмножестве не затрагиваются отображением ρ.
Теорема 6.11. Для каждого рекурсивно перечислимого языка L⊆∑+T существует морфизм h, такой, что
L = ρ(h-1(D))∩∑*T.
|
ПОИСК:
|
При использовании материалов сайта активная ссылка обязательна:
http://informaticslib.ru/ 'Библиотека по информатике'