4.3. Анализ обстановки
Познакомившись с тем, как машина может использовать графовую модель операции для описания среды и планирования стратегии поведения, мы хотели бы теперь понять, как научить робота с помощью нескольких картинок на экране телевизора строить внутренние модели окружающей среды. В этом разделе мы с целью сопоставления вкратце рассмотрим два механизма обработки таких изображений, запрограммированных для вычислительной машины, а затем займемся анализом обстановки, в результате которого зрительное восприятие обстановки в целом можно свести к восприятию совокупности объектов, каким-то образом расположенных в пространстве. В задачах распознавания букв предъявленную картинку нужно отнести к одному из сравнительно небольшого числа классов, например определить цифру или букву алфавита. В задачах распознавания рукописных текстов на картинку попадает уже целое слово, а образующие его буквы несколько искажены тем, что они связаны друг с Другом. Поэтому при попытках разобрать написанное слово необходимость разбиения на элементы предъявляет программе Дополнительные требования помимо распознавания букв. Но, с другой стороны, появление контекста может послужить толчком к развитию методов, непригодных для обработки единичных символов. Например, что означает символ α - букву a или букву и? Трудно сказать, но если эта буква встретилась в слове "тар", т. е. безусловно является второй буквой слова "т - р", то, справившись со словарем, мы узнаем, что существует слово "тир", но нет слова "тар" и поэтому следует избрать первое толкование. Люди обычно используют гораздо более широкий контекст для разрешения неопределенностей. Однако в настоящее время непрактично было бы вкладывать в машину нечто большее, чем словарь общеупотребительных слов и выражений, и, следовательно, ее подход к использованию контекста нельзя даже сравнивать с возможностями человека, который по завязке интриги на стр. 43 детективного романа может догадаться о развязке на стр. 217!
Нам хотелось бы теперь перейти от обработки зрительного образа, представленного в виде четко очерченного контура, о котором к тому же известно, что он содержит линейную последовательность символов, к нечеткому распределению света и теней на экране телевизора (или распределению потенциалов в колбочках и палочках) и спросить себя, как можно распознать эту картину и извлечь информацию, необходимую для взаимодействия с окружающей средой, которую эта картина отображает. Заметим, что подобный анализ обстановки может быть организован по иерархическому принципу не менее чем с двумя различными уровнями анализа. Сравните, как вы идете по улице, где препятствия надо различать лишь для того, чтобы не наткнуться на них (велико же бывает смущение, если таким препятствием оказывается знакомый, утверждающий, что вы нарочно сделали вид, будто не замечаете его), т. е. когда вы видите, где препятствие, а не что это такое, с тем, как вы складываете из кусочков картинку и где в равной степени важно и "что" и "куда". Однако провести здесь четкую грань нельзя. Решая навигационную задачу, мы должны принимать во внимание не только положение, но и скорость перемещения препятствия, а (как показывает материал разд. 2.1) ответ на вопрос "что" в значительной степени зависит от характера нашей активности в данный момент.
Рассмотрим конкретную задачу составления программы для робота рука - глаз, состоящего из телевизионной камеры, вычислительной машины и механической руки, предназначенной для того, чтобы брать предметы со стола (рис. 63). Вычислительная машина может пользоваться различными программами для управления рукой в зависимости от формы предмета - куб это, пирамида или шар. Мы будем говорить, что робот "распознал" предмет в тот момент, когда машина получает доступ к соответствующей программе. В настоящее время подобные программы узнают куб "по имени" и используют наименование для адресации соответствующей подпрограммы. Простота ситуаций, в которых приходится работать роботу, позволяет в определенной степени обойти проблему ее направленности. В более сложных ситуациях может оказаться необходимым вызывать подпрограммы в зависимости от целого комплекса признаков, не пользуясь программами распознавания объектов. В среде же, в которой встречаются лишь кубы, пирамиды и шары, "распознавать" предметы очень просто: если у предмета нет острых ребер, это шар, если в поле зрения попадает грань с четырьмя углами, это куб, при условии, что видны еще две вершины, и пирамида, если дополнительно видна лишь одна вершина. (Важно отметить, что такая простая классификация становится возможной лишь потому, что робот заранее "знает", что кроме кубов, пирамид и шаров ему ничего не может встретиться. Это своего рода "знание контекста", которое должно быть воплощено в КМ (разд. 4.1). Обычно мы принимаем решения быстрее, чем могли бы, поскольку можем использовать свои знания о некоторых свойствах окружающей среды. Конечно, иногда, например если человек вместо ужа взял в руки гремучую змею, это "знание" может и подвести.)
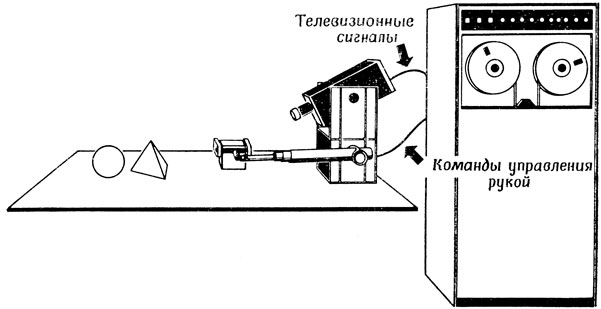
Рис. 63. Гипотетический робот, использующий сигнал от телевизионной камеры для того, чтобы с помощью вычислительной машины управлять движениями механической руки
Поскольку речь идет о роботе, остается задача выяснения местоположения предмета и его ориентации. Здесь, однако, важно отметить, что, например, для куба, изображенного на рис. 64, машине вовсе не нужно вычислять все координаты куба, а достаточно определить середину видимой грани AB и невидимой грани CD - единственные параметры, знание которых необходимо для программы захвата куба и правильного положения руки.
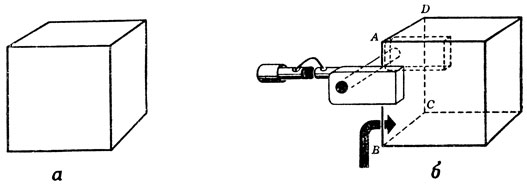
Рис. 64. Для управления движениями механической руки, изображенной на рис. 63, необходимы координаты невидимой грани куба. а. Объект, как его 'видит' камера, б. Грань, координаты которой необходимы для того', чтобы правильно расположить 'руку'
Рассмотрим в этом свете различные способы анализа обстановки, разработанные разными группами, занимающимися конструированием роботов (разд. 4.4), примерно к 1970 г. Обычно прежде всего решают задачу замены двумерного растра интенсивности света приближенным контурным изображением предмета на зрительном поле. [Для упрощения задачи обычно пользуются плоским освещением, не дающим теней. В настоящее время ведутся работы над тем, как помешать роботу рассматривать тени как самостоятельные объекты (черта, характерная и для совсем маленьких детей).] Таким образом, первые два этапа обработки зрительных изображений у роботов аналогичны предварительной обработке зрительных стимулов у кошки (разд. 2.4): сначала усиливается контраст, а затем точки наибольшего контраста соединяются короткими прямыми отрезками. Результат подобной обработки применительно к изображению куба показан на рис. 65, А. Следующий шаг состоит в том, чтобы до некоторой степени заполнить промежутки с помощью длинных прямых, в основном проходящих по коротким отрезкам, в результате чего получается контур, изображенный на рис. 65, Б.
Отметим, что рис. 65, Б никак нельзя назвать законченным контурным изображением куба. Некоторых линий здесь не хватает, особенно на пересечении двух граней, где характер отражения света меняется мало или совсем не меняется, и в результате детекторы контраста не дают необходимого материала блоку линейной аппроксимации.
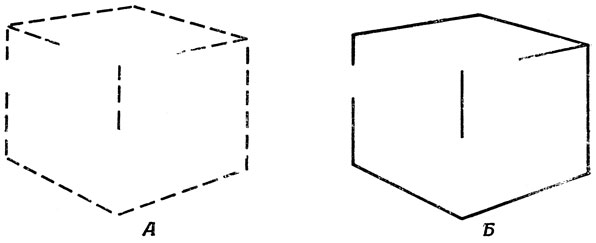
Рис. 65. Две стадии предварительной обработки изображения куба
По-видимому, возможны две основные стратегии (рис. 66) дальнейшей обработки такого незавершенного изображения, как на рис. 65, Б. Первая из них - метод продолжения прямых (straight-through analysis) - состоит в том, чтобы попытаться дополнить контур до "идеального контурного изображения", а затем пытаться распознать этот новый контур. При втором - анализе вложением (nested analysis) - сначала выдвигают гипотезу о том, что может изображать исходный грубый набросок, а затем уже исследуют его более тщательно, стараясь подтвердить примерную гипотезу. Мне кажется, что второй подход больше соответствует естественной схеме, используемой человеком.
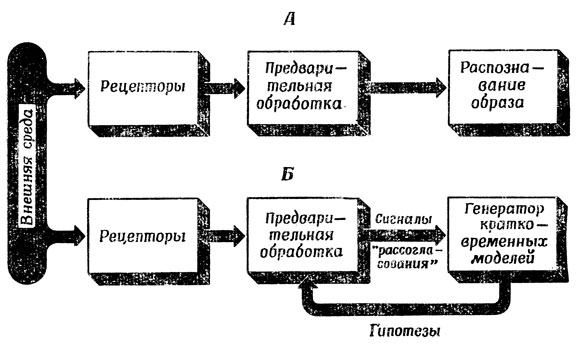
Рис. 66. А. Обработка зрительных образов методом продолжения прямых. Б. Один из возможных вариантов анализа вложением. Вероятно, подобным образом происходит обработка зрительной информации у человека. При этом 'эфферентное управление', использующее рабочую гипотезу, вызывает перестройку канала прохождения сигнала
При использовании метода продолжения прямых несовершенный набросок контура предмета в прямолинейной среде можно обрабатывать с помощью эвристического поиска идеального контура, основываясь на эвристиках "линии должны продолжать существующие линии" или "нужно выбрать имеющийся угол и провести через него прямую, параллельную уже существующей"; поиск продолжается до тех пор, пока не удастся удовлетворить таким критериям полноты, как "любая линия всегда должна соединять две вершины и не может повиснуть в воздухе" или (если есть возможность пользоваться объемной информацией) "если вершина расположена на ближнем конце прямой, то из нее обычно должно выходить более двух прямых". Если штрих на исходном несовершенном рисунке очень короткий, его можно стереть. Если две прямые продолжают одна другую, то разрыв между ними можно заполнить, если только между ними нет пересечений, свидетельствующих о том, что они принадлежат разным объектам.
Анализ вложением также может использовать подобные процедуры продолжения прямых, но для него они являются составной частью процесса распознавания объектов. Например, главная идея подхода Дьюда и Харта [62] состоит в том, чтобы сначала найти вертикальные прямые, а затем попытаться "наращивать" ответвления от этих прямых, постоянно проверяя, не приводит ли это к очертаниям некоторого "известного" предмета. В такой программе анализ изображения продолжается лишь до тех пор, пока предмет не будет узнан с определенной степенью достоверности, и, следовательно, "идеальное" контурное изображение предмета строится машиной уже после распознавания, а не до него.
Читатель сам может попытаться составить перечень необходимых команд, позволяющих дополнять изображения, подобные показанному на рис. 65, Б. Более тонкие методы могут использовать также информацию о цвете предмета и материале, из которого он сделан.
Создается впечатление, что люди пользуются анализом вложения в большей степени, чем методом продолжения линий. Мы воспринимаем контур, как бы плохо он ни был различим, потому что мы узнали куб, а не потому узнаем куб, что добросовестно дорисовали все контурные линии. Искусство импрессионистов в значительной степени основано на их умении передать игру цвета на поверхностях, и прошло много времени, прежде чем другие художники и широкая публика поняли, что это дает такое же "истинное" представление об окружающем мире, как и четкие контуры, раскрашенные соответствующими красками. И так же как в проблеме распознавания рукописных текстов, где, как мы убедились, предположения о том, что мы видим слово, имеющееся в словаре, позволяет компенсировать недостаток информации, приводящий к разночтениям, так и здесь гипотеза о том, что наблюдаемый предмет является одним из знакомых нам предметов, позволяет компенсировать неполноту контурной информации. Этот факт - то, что мы ищем достаточное число признаков, по которым наблюдаемый стимул можно отнести к одному из известных объектов, а не пытаемся оценить все детали (включая и отсутствующие) зрительного образа,- открывает, по-видимому, возможность простой механистической интерпретации наблюдений гештальт-психологии, утверждающей, что мы воспринимаем "целое", а не совокупность "деталей", как и следует из закона "замыкания" (law of closure), согласно которому, например, изображение на рис. 67 будет воспринято как квадрат. Понятно, что, узнав в этом изображении квадрат, мы можем затем заполнить разрыв на правом ребре, но главное как раз в том, что это изображение мы воспринимаем как квадрат с "дыркой", а не как "фигуру из пяти прямолинейных отрезков. Вы спрашиваете, а не квадрат ли это? Конечно, нет. Для квадрата достаточно четырех отрезков".
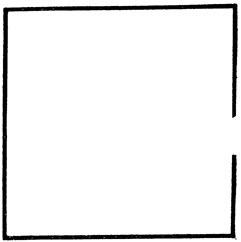
Рис. 67. Иллюстрация закона 'замыкания'. Эта фигура воспринимается как квадрат с разрезом
Воспринимая сложную обстановку, человек быстро переводит глаза с одной точки на другую. Точки фиксации взгляда соответствуют деталям, весьма важным для восприятия. Другими словами, система со сложной организацией восприятия не просто равномерно сканирует обстановку, а ищет те несколько ее черт, которые позволили бы быстро составить общее суждение о ней в целом. Знать, на что следует посмотреть после этого, - прекрасный пример одной из составляющих интеллекта. Например, Тихомиров и Познанская [242] выяснили, что шахматисты-мастера смотрят на доску меньше, чем новички, и запоминают позицию точнее, причем мастера переводят свой взгляд с одного ключевого места позиции на другое, а новички сканируют доску случайным образом. Если же расположить фигуры на доске случайным образом, так что у мастера не может возникнуть содержательной стратегии поиска, результаты его попыток запомнить расположение фигур оказываются сравнимыми с результатами новичка.
На этом этапе читатель может возразить, что в наших рассуждениях слишком смазывается различие между человеком и роботом. "В конце концов робот обрабатывает телевизионную картину, а мы воспринимаем реальный мир", - возмутится он.
Хотя не следует преуменьшать многие различия, имеющиеся между людьми и (существующими) машинами, разграничение, выраженное в приведенной фразе, основано на недоразумении. Человеческий мозг, перерабатывающий электрические потенциалы, приносимые зрительным трактом, столь же далек от "реальности", как и вычислительная машина, перерабатывающая изображение на телевизионном экране. А ощущение реальности создается благодаря тому, что предварительную обработку мы осуществляем подсознательно, а начинаем работать сознательно (хотя я и не берусь объяснить, как именно!) лишь на уровне представления зрительного образа в виде совокупности объектов, расположенных в пространстве, представления, которое многократно оправдывало себя в качестве прочной основы взаимодействия с внешним миром. Таким образом, именно направленная на действие оперативная модель (ср. разд. 4.1) внешней среды (которую для робота тоже можно сделать, хотя и в значительно более простом варианте, чем тот, что есть у человека), а не осознание предварительной переработки, сопутствующей формированию этой модели, обеспечивает ощущение реальности.
Анализ вложением свидетельствует еще и о том, что переработка сенсорной информации ни в коей мере не является однонаправленным процессом (рис. 66, А), а организована по принципу схемы на рис. 66, Б, где даже периферическая переработка зависит от процессов централизованного формирования гипотез. Естественно, что учет сенсорной информации другой модальности, а также сигналов обратной связи от рецепторов значительно усложнит картину.
Убедившись в том, что распознавание простых объектов можно поручить машине, и получив попутно некоторые представления о процессах восприятия у человека, мы должны заняться проблемой анализа обстановки, образованной несколькими предметами, из которых одни частично загораживают другие. Для простоты мы будем рассматривать лишь статичные среды. (А это значит, что мы можем вернуться и еще раз пересмотреть часть картины, будучи уверенными, что там ничего не изменилось; однако при этом мы лишаем себя тех многих важных примет, которые дает движение.) Предположим также, что мы работаем с "идеальными контурами", которые аккуратно воспроизводят все видимые границы.
Один из методов, вполне успешно справлявшийся с анализом обстановки из нескольких предметов, каждый из которых принадлежит короткому списку "знакомых" объектов, получил название метода подгонки модели [214]. По своей сути это тот же метод, который мы обсуждали в связи с рис. 63. Предположим, например, что у нас есть "модели" куба, шара, пирамиды. Тогда мы сможем подогнать модель куба под 9 линий (рис. 68, А), а затем снять их, оставив нерешенной проблему распознавания оставшегося контура. Но к этому контуру легче подогнать модель призмы, чем модель куба или шара, и, следовательно, мы заканчиваем анализ обстановки, сделав вывод, что перед нами "Куб, стоящий перед призмой".
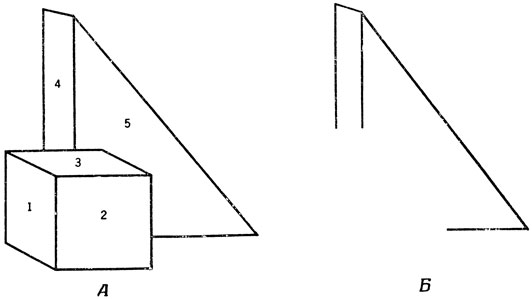
Рис. 68. Пример подгонки моделей. Подогнав модель куба под девять отрезков (А), мы можем стереть их, оставив остальные линии (Б). Эти оставшиеся линии больше соответствуют призме, чем кубу или шару, а, следовательно, анализ изображения приводит к выводу: 'Куб, стоящий перед призмой'
Другой подход, также основанный на использовании идеального контура, но, кроме того, требующий, чтобы все изображения были образованы лишь прямыми, основан на декомпозиции изображения с последующими попытками распознавания отдельных его частей. В этой связи Гузман [98] предложил метод, основанный на изучении каждого узла для выяснения того, насколько правомерно считать, что примыкающие к ней области принадлежат одной и той же фигуре.
Рассмотрим рис. 69, где показаны узлы трех типов. Заметим, что узел типа "стрелка" на рис. 68, А встречается в разных ориентациях трижды и что во всех случаях две из областей разбиения, образующих угол стрелки (1 и 2), оказываются принадлежащими одному предмету, а третья область (3) - другому. Узел типа Y встречается лишь однажды, и все его грани принадлежат одному предмету. Наконец, узел типа T встречается тоже три раза, и во всех случаях области, лежащие по разные стороны от "верхней" перекладины, принадлежат разным объектам.
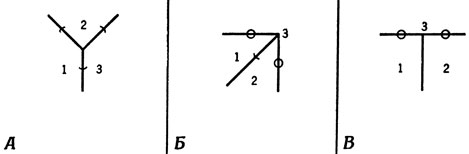
Рис. 69. Три типа узлов, которые можно использовать в качестве признаков в задаче декомпозиции изображения на отдельные объекты. А Узел типа Y. Б. 'Стрелка'. В. Узел типа T. Ребра, помеченные дужками, вероятнее всего, разделяют две грани одного и того же объекта, и для них показатель связи должен быть равен +1. Ребра же, помеченные кружочками, вероятнее всего, разделяют грани двух разных объектов, и для них показатель следует положить равным -1
Это наводит на мысль о возможности следующего подхода. Составим "турнирную таблицу", в которой каждой паре различных областей соответствует одна клетка; для каждой такой пары будем решать, являются ли две входящие в нее области двумя гранями одного предмета, в зависимости от значения "показателя связи", который вычисляется по трем приведенным выше признакам следующим образом. Будем записывать в каждую клетку таблицы по единице каждый раз, когда найдется узел, в котором соответствующие области являются областями (1, 2), (2, 3) или (3, 1) узла Y или областями (1, 2) - для "стрелки", и минус 1, если области являются областями (1, 3) или (2, 3) для "стрелки" или узла T. Закончив эту обработку, мы относим к одному объекту все области, для которых суммарный показатель связи не менее +1.
Пример подобной обработки рис. 68, А приведен на рис. 70. Мы рекомендуем читателю проделать аналогичную работу с рис. 71, где он сможет убедиться, что некоторые из локальных указаний (например, для узлов 8, 9 и 11) будут ошибочными, но учет всех узлов в целом дает правильную декомпозицию.
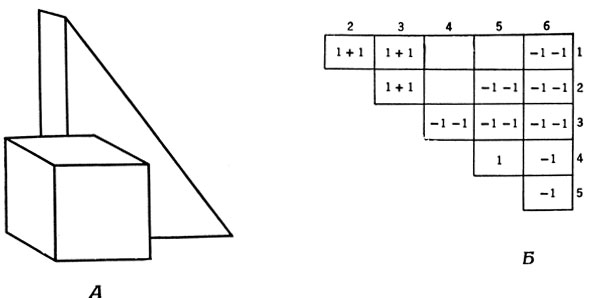
Рис. 70. Использование признаков рис. 69 для того, чтобы отделить куб от стоящей за ним призмы. У грани 1 положительные показатели связи с гранями 2 и 3, а у граней 2 и 3 - между собой. В то же время у граней 1 и 3 отрицательные показатели связи с 'гранью' 6, у грани 2 - с 5 и 6, у грани 3 - с 4 и 5 и т. д. На основании этого делается вывод о том, что грани 1, 2 и 3 принадлежат одному объекту. Аналогичным образом положительно 'связаны между собой грани 4 и 5, тогда как область 6 выделяется как самостоятельный 'объект' (фон)
После того как мы воспользовались подобным алгоритмом декомпозиции, мы без особого труда сможем применять и методы распознавания изолированных объектов, получая в результате рабочее описание обстановки. Изящное обобщение работы Гузмана можно найти у Хаффмана [122].
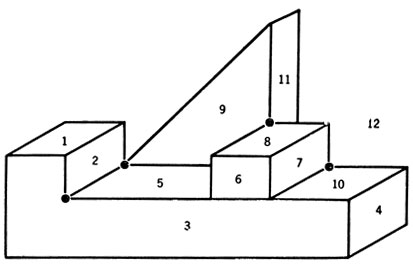
Рис. 71. Это изображение правильно анализируется с помощью признаков рис. 69, несмотря на то, что классификация узлов, помеченных жирными точками, была ошибочной
Проблему "изучения структурного представления по примерам" рассматривает Уинстон [262], а "процедуру представления данных в вычислительных программах для понимания естественных языков" - Виноград [260].
Все эти примеры ясно показывают, что машины в состоянии провести анализ обстановки и описать ее в виде совокупности предметов, расположенных в пространстве вполне определенным образом. Конечно, существующие методы применимы лишь в условиях хорошего освещения и для небольшого числа простых объектов, но так или иначе первый шаг уже сделан. Быть сможет, еще важнее то, что многие процессы, которые кажутся само собой разумеющимися, например наша приобретенная в очень раннем возрасте способность распознавать отдельные объекты в перенасыщенной предметами комнате, на самом деле весьма сложны. И изучая их реализацию на машине, мы не только начинаем понимать, что именно требует объяснения, но и получаем какое-то представление (возможно, ошибочное, но эти ошибки помогают иногда наметить новые направления исследований) о том, как могут быть устроены механизмы, которые мы надеемся обнаружить в нервных сетях. Но прежде чем вернуться к теории мозга, бросим беглый взгляд на то, как эвристический поиск и анализ обстановки объединяются в задаче управления роботом.
|
ПОИСК:
|
При использовании материалов сайта активная ссылка обязательна:
http://informaticslib.ru/ 'Библиотека по информатике'