4.6. Оптимизация на дискретных множествах. Метод ветвей и границ
Область определения задачи математического программирования часто имеет дискретную структуру (например, представляет собой совокупность конечного числа точек, линий, поверхностей); подобная ситуация рассматривалась в § 1.6, 1.7. В частных случаях удается выявить типичные геометрические признаки указанной совокупности (узлы целочисленной решетки, множества параллельных прямых и т. п.); в общем случае такие признаки отсутствуют, что затрудняет поиск решений соответствующих задач и приводит к необходимости применять различные комбинаторные методы, простейшим (и нежелательным) представителем которых является метод полного перебора вариантов.
Пусть дана задача: найти Х∈U→min{z = f(X)}, где U - дискретное множество. Предполагается, что U можно разбить на не пересекающиеся подмножества U(1), U(2),....,U(η) причем способ разбиения должен выбираться применительно к конкретным условиям исследования; далее, нужно уметь оценить нижнюю границу значений г на каждом подмножестве U(i)(i = 1,...,η) и найти, таким образом, ряд чисел ẑ(i), обладающих свойством ẑ(i)≤f(Х), Х∈U(i) (здесь возникают самостоятельные задачи определения ẑ(i)).
Если теперь допустить, что каждая подобласть U(i) делится, в свою очередь, на новые U(i,l) (1≤i≤η, l = 1,..., р) и существуют пути получения соответствующих ẑ(i,l), то имеет смысл исследовать процесс ветвления (рис. 4.3) с целью выявить бесперспективные подмножества U и сократить за счет этого объемы вычислений. Идея направленного разбиения U с последовательными оценками ẑ(i), ẑ(i,l),... лежит в основе метода ветвей и границ.
Чтобы иметь возможность сравнивать между собой подмножества U(i,l,..), заметим следующее: каким бы способом ни была найдена оценка ẑ, относящаяся к исходному U, она не ухудшится при рассматриваемых разбиениях, т. е. ẑ(i)≥ẑ, (i = 1,...,η); точно так же ẑ(i,l)≥ẑ(i) (1≤i≤η; l = 1,..., р) и т. д. Чем больше расхождения между величинами правых и левых частей этих неравенств, тем менее перспективным представляется соответствующее под множество очередного уровня, однако необходимые выводы
могут быть сделаны только после вычисления всех ẑ(i), затем ẑ(i) всех при некотором фиксированном i, найденном на предыдущем шаге, и т. д. Результатом подобных действий является постепенное сужение области поиска X*.
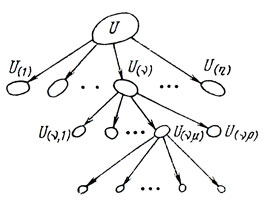
Рис. 4.3
Алгоритм метода включает следующие операции:
а) получение ẑ и выбор начальной точки X0∈U (правила для этого формулируются применительно к конкретным условиям задачи; например, в целочисленном линейном программировании за величину z можно принять значение ẑ в точке X̂, а в качестве Х0 использовать ближайшую к X̂ точку, удовлетворяющую требованиям целочисленности, см. п. 1.6);
б) сравнение ẑ с f(Х0); если окажется f(X0) = ẑ, то Х0 = Х* (это следует из определения ẑ); в противном случае - переход к п. в);
в) разбиение множества U на конечное число подмножеств U(i), (i = 1,...,η) (способ разбиения заранее не. оговаривается);
г) получение оценок ẑ(i) и выбор среди них
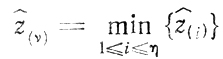
(этим однозначно определяется подмножество U(υ), предназначаемое для дальнейших исследований);
д) выбор точки X1∈U(υ) (аналог Х0) и сравнение ẑυ с f(X1); если f(X1)=ẑ(υ), то Х1 = Х*; при f(Х1)>ẑ(υ) - переход к п. е);
е) разбиение U(υ) на ряд подмножеств U(υ, l) (l = 1,..., р), тем или иным способом;
ж) получение ẑ(υ, l) и выбор среди них
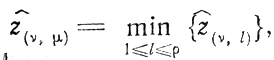
что позволяет указать U(υ, μ);
з) выбор X2∈U(υ, μ) И сравнение ẑ(υ, μ) с f(Х2); в зависимости от результата -конец или продолжение процесса поиска X* по рассмотренной схеме (см. рис. 4.3).
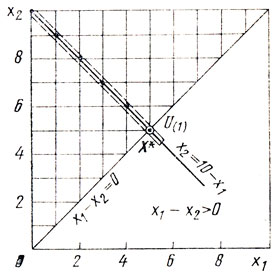
Рис. 4.4
Предложенный алгоритм обладает тем преимуществом, что не налагает никаких ограничений на структуру U и при удачных разбиениях позволяет эффективно исключать бесперспективные U(i, l,...). Вместе с тем разработка правил ветвления, способов получения очередных ẑ и Хk (k = 1, 2, ...) может потребовать специальных исследований, отражающих специфику конкретных задач, но часто приводящих к отрицательным (в смысле экономии средств и времени) результатам.
Метод ветвей и границ хорошо зарекомендовал себя в решениях целочисленных линейных задач, ряда задач распределения ресурсов, однако в общем случае его применение требует осторожности. Ниже дан иллюстративный пример.
Пример: найти х1, х2→min {z = max(x2, 10-x1)} при х1-x2≤0; 0≤x1, x2≤10, x1, x2 - целые числа.
Решение: в выражении целевой функции под знаком максимума собраны неотрицательные величины, поэтому очевидная оценка ẑ есть 0; за Х0 здесь можно принять точку (0,0), принадлежащую области определения задачи (рис. 4.4). Поскольку f(0, 0) = max {0, 10} = 10>ẑ, необходимо начать разбиение U. Множество U (порядка 60 узлов решетки, рис. 4.4) разделим на два подмножества - точки, лежащие на прямой х2 = 10-х1 и все остальные точки (это облегчает вычисления ẑ). Таким образом U(1) включает (0,10), (1,9), ..., (5,5) и ̂(1) = 5; для всех X∈U(2) выполнены условия: либо x2<10-x1 либо x2>10-x1, т. е. f(X)≥6 = ẑ(2); следовательно, ẑ(2)<ẑ(1) и дальнейший анализ должен проводиться применительно к U(1).
Подмножество U(1) содержит всего 6 элементов, и они уже исследованы; здесь X1 = (5,5); f(X1) = ẑ(1) = 5, поэтому Х* = (5,5), z* = 5.
Основные идеи и принципы построения схем поиска X*, r* в задачах с полной информацией применимы и к задачам с неполной информацией, изучаемым в гл. 5-7, хотя специфика условий, в которых проводятся исследования, существенно влияет на способы получения решений.
|
ПОИСК:
|
При использовании материалов сайта активная ссылка обязательна:
http://informaticslib.ru/ 'Библиотека по информатике'