Глава седьмая. Стохастические процедуры оптимального выбора. Проблема накопления информации
7.1. Ошибки эксперимента. Учет влияния случайных факторов
Здесь будут изучены схемы поиска X*, z*, содержащие элемент случайности. Основными причинами, определяющими необходимость внесения случайности в действия исследователя, являются погрешности результатов экспериментов, а также отсутствие информации о свойствах поверхности отклика. Для простоты в первую очередь рассматриваются задачи, в которых целевая функция имеет скалярный аргумент.
Предположим, что эксперименты, проводимые в интересах решения одномерной задачи поиска (см. гл. 5), не дают точных значений z-любое из получаемых z содержит некоторую ошибку δz. Она является случайной и носит аддитивный характер (измеренная величина z представляется как сумма истинного, но неизвестного исследователю значения zи и рассматриваемой ошибки: z = zи+δz ).
Чтобы учесть присутствие δz, необходимо располагать теми или иными сведениями о ней, причем полнота этих сведений может меняться в широких пределах, начиная от законов совместного распределения ошибок в разных экспериментах и кончая моментными характеристиками (математическим ожиданием и дисперсией) величины δz при конкретном фиксированном х.
Пусть на интервале [0, 1] выбрана точка х и требуется получить оценку zи=f(x) в условиях, когда известно лишь математическое ожидание М[δz] (подобная задача возникает при попытке реализовать здесь какую- либо из детерминированных процедур поиска). Можно стремиться достичь результата путем набора статистик, повторяя многократно эксперименты в х и используя получаемые значения z для вычисления среднего z̄, после чего легко найти zи = z̄-М[δz]. Проведение этих операций связано с затратами средств и времени тем большими, чем выше требования к точности оценки zи. Вопрос о том, можно ли избежать подобных затрат (или по крайней мере повысить их эффективность) решается на основе следующих рассуждений: если в данной точке х проведены N экспериментов и определены z(1), z(2) , ... , z(N), образующие статистику, то допустимо считать
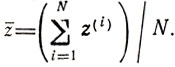
Если бы число экспериментов составило N-1, то оценка z̄ имела бы вид
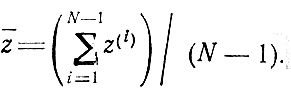
Сравнивая эти формулы, легко видеть, что между найденными z̄, обозначенными соответственно z̄N и z̄N-1 существует зависимость z̄N = [(N-1)/N]z̄N-1 + (1/N)z(N) из которой следует:
- величина z(N) являющаяся носителем "новой" информации, возникшей в последнем (по счету) эксперименте, входит в оценку z̄N с весовым коэффициентом 1/N; убывающим с ростом N;
- величина Z̄N-1 полученная на основе использования "старой" информации, содержащейся в z(1), z(2) ... z(N-1) входит в z̄N с весовым коэффициентом (N-1)/N (он становится практически равным единице уже при N = 8-10);
- наибольшей информационной эффективности можно добиться, проводя в каждой точке х только один эксперимент (это означает отказ от попыток применения детерминированных процедур поиска х*, z* там, где есть ошибки эксперимента).
При решении оптимизационных задач исследователь обычно не интересуется более или менее точным "восстановлением" вида функции z = f (x). Он стремится построить правила выбора очередных х, основываясь на результатах предшествующих экспериментов, с тем чтобы в конце концов прийти к я*. В условиях, когда есть ошибки 62, реализовать этот принцип можно путем такого выбора каждого нового значения х, при котором оно связывается определенной зависимостью с предыдущими х и соответствующими z(x). Вследствие этого в этом новом х будет учтена вся полезная информация (содержащаяся в предшествующих z) и вся ложная информация (обусловленная наличием δz), которая, однако, должна разрушаться по мере переходов от хi к xi+1 (i = 1, 2, . ..), если упомянутая выше зависимость между разными х выбрана надлежащим образом.
Пусть xi+1 = Wi(xi, zi) или xi+1 = Wi(xi, zиi + δzi). Очевидно, вид функции Wi должен влиять на характер сходимости последовательности значений xi (i = 1, 2, ...) к некоторому пределу х̂ (в частности, к х*). Если, например, Wi такова, что xi+1 = W1i(xi, zиi) + W2i(δzi), то зная свойства δzi (или предполагая их), можно утверждать: при удачном выборе W2i вероятность отклонения хi+1 от х с увеличением i станет сколь угодно малой, а сам выбор преобразований W1i, W2i (с одновременным уточнением понятия сходимости xi+1 к х̂ при i→∞) будет равносилен выбору стратегии поиска x*, z* в рассматриваемом случае. Таким образом, намечается путь решения задачи, для которого характерно то, что в каждой точке х проводится только один эксперимент, а фильтрация ошибок происходит за счет умелого сочетания длины шага и свойств случайных величин δzi. Эта идея лежит в основе методов стохастической аппроксимации.
Обратимся к определениям сходимости последовательностей случайных чисел (в дальнейшем они обозначаются большими буквами X, R и т. п., а их возможные значения - соответствующими малыми буквами).
Последовательность случайных величин Xi (i = 1, 2,...) сходится по вероятности к некоторому неслучайному пределу х̂, если для произвольного μ>0 вероятность события | Xi-x̂|≥μ стремится к нулю при i→∞, т. е.
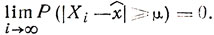
Последовательность случайных величин Xi(i = 1, 2,...) сходится в среднеквадратическом к неслучайному пределу х̂, если математическое ожидание квадрата модуля разности Xi-х̂ стремится
к нулю при i→∞, т.е.
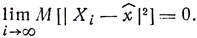
Последовательность {Хi}, сходящаяся в среднеквадратическом, сходится и по вероятности (обратное положение места не имеет).
Пусть принята форма представления xi+1 в виде суммы W1i(Xi, zиi) + W2i (δzi). В силу случайности δzi величина W1i будет случайной и может рассматриваться как случайная составляющая Xi+1; регулярной составляющей Xi+1 является W1i. Вводя обозначения W1i = Yi, W2i = Ri, получаем равенство Xi+1=Yi+Ri, которое используется в последующем анализе как исходное.
Потребуем, чтобы последовательность случайных величин Xi+1 (i = 1, 2, ...) сходилась в средне-квадратическом смысле к некоторому пределу х̂. Формально это
требование выражается как
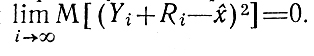
Математическое ожидание суммы, стоящей в квадратных скобках, есть (Yi-x̂)2+2 (Yi-x̂)M[Ri] + М[R2i] или (Yi-x̂)2+2 (Yi-x̂) М [Ri] + М2 [Ri] + D [Ri] (из общего определения дисперсии следует D[Ri] = М [{Ri -М[Ri]}2] = М[R2i]-М2[Ri]). Для упрощения формул положим М[Ri] = 0, что позволит представить исследуемое условие в виде
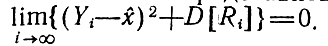
Здесь под знаком предела стоит сумма двух существенно положительных величин, и достаточно рассмотреть совместно условия
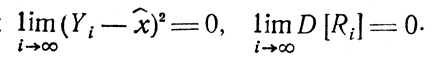
Обращаясь к первому из них, заметим, что функция должна Yi быть построена так, чтобы одинаково хорошо управлять процессом поиска в двух случаях: а) точка xi находится вблизи x̂, и есть опасность "перескочить" через х̂ при переходе к xi+1; б) точка хi находится настолько далеко от х̂, что нет оснований надеяться достичь х̂ за один шаг.
Для случая а) условие
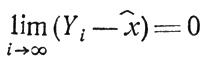
окажется выполненным, если потребовать, например, |Yi - х̂|≤αi, где αi - член последовательности неотрицательных действительных чисел, обладающей свойством
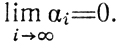
В случае б) этого требования недостаточно, поскольку желательно, чтобы каждый переход от xi к xi+1 (i = 1, 2, ...) сопровождался уменьшением расстояния до точки х. Здесь можно принять |Yi-х̂|≤|xi-x̂| - γi. Смысл этого неравенства заключается в следующем: регулярная составляющая величин Xi+1 (именно Yi) должна отличаться от х̂ меньше, чем xi, для чего вводится поправка γi (неотрицательное действительное число).
Чтобы процесс не остановился по прошествии некоторого конечного числа шагов, нужно иметь
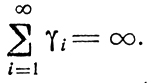
Рассмотренное условие сходимости процесса (точнее- его регулярной составляющей) может быть дано в обобщенном виде
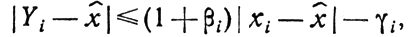
где
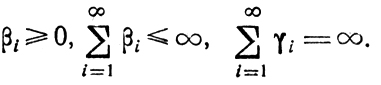
Эти замечания позволяют сделать важный вывод*, чтобы доказать сходимость процесса (и в конечном счете решить задачу поиска х*, z*), необходимо располагать определенной информацией о свойствах функции f(x) = zи. В дальнейшем при анализе процедур стохастической аппроксимации этот вывод будет конкретизирован.
Обратимся теперь к требованию
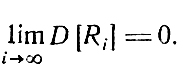
По мере совершения переходов от xi к xi+1 (i = 1, 2, ,..) характеристики ошибок δzi (например, их моменты) могут либо меняться, либо оставаться неизменными. В этой ситуации надежды удовлетворить рассматриваемому требованию связываются лишь с надлежащим выбором преобразования W2i (δzi), выполняющего роль "фильтра" случайных помех δzi. Общим моментом здесь является необходимость соблюдения условия
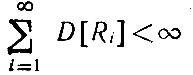
(в предположении независимости случайных величин δzi, i = 1, 2, ...).
Таким образом, процесс поиска в целом сводится к следующему: по мере проведения экспериментов,
в каждом из которых величина z = zи + δz измеряется лишь один раз, регулярная составляющая Yi очередного значения Xi+1 все меньше отличается от некоторого действительного числа х̂, а случайная составляющая Rt постепенно исключается сведением ее дисперсии к нулю.
Методы решения задач, основанные на этой идее, находят применение в различных областях исследований.
|
ПОИСК:
|
При использовании материалов сайта активная ссылка обязательна:
http://informaticslib.ru/ 'Библиотека по информатике'